


89,062
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
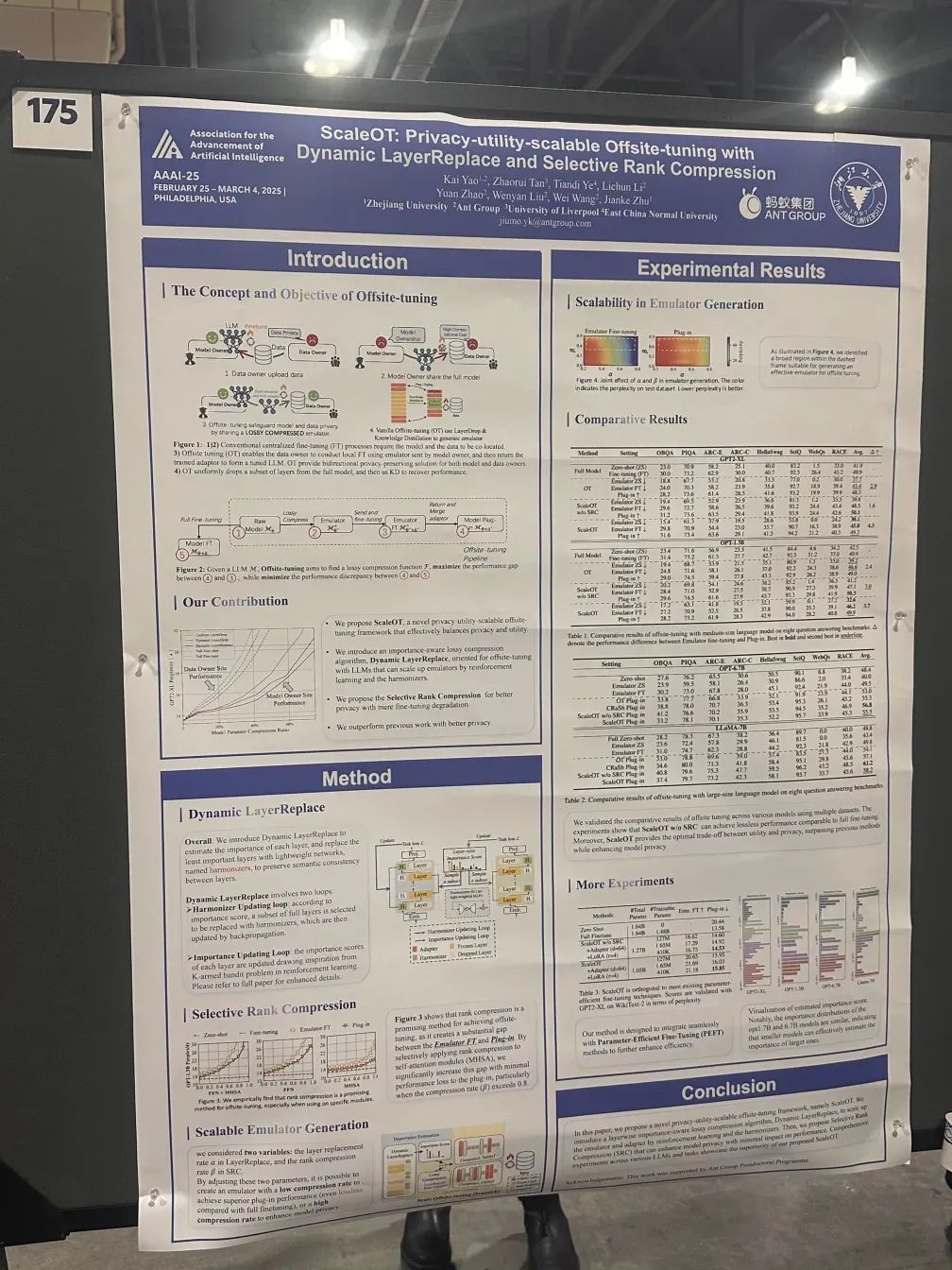
分享继摩斯大模型跨域微调方向论文被顶级会议AAAI录取后,在被顶会录取的13000个投稿中,成功进入前4.6%,获得2025AAAI oral presentation资格。来自摩斯的代表,于近日在费城完成演讲。

摩斯的代表分析了当前离线调优方法所存在的问题,现场介绍了跨域微调大模型隐私保护训练方法,和摩斯基于此背景提出的ScaleOT框架。
这种新的大模型跨域微调算法,设计了重要性感知的动态层替换模型压缩方法,有效攻克了在仿真器生成时计算复杂度高、模型隐私安全性不足等难题,为大模型隐私微调方向提供了新颖的思路与解决方案。ScaleOT框架是一种新颖的隐私效用可扩展离线调优框架,能够有效平衡隐私性和效用性,实现生产级可用。
论文地址:https://arxiv.org/pdf/2412.09812
这一全新的大模型隐私微调算法,已在摩斯大模型隐私安全产品上线,产品融合了数据脱敏、拆分学习、模型混淆、差分隐私、TEE等多种技术路线,实现大模型落地应用中的模型微调、推理全链路数据和模型隐私安全保护。
同时,摩斯还提供大模型算力和行业大模型服务;支持TEE GPU云服务和一体机方案;支持开源通用大模型,支持deepseek满血版,以及法律大模型、金融大模型、营销大模型等行业大模型在线加密调用。
欢迎各行业生态伙伴进行合作咨询!!
关注我,获取更多资讯~


