


571
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享原子操作CAS(Compare-And-Swap)和锁-CSDN博客
定义:原子操作指的是在执行过程中不可被中断的操作,该操作要么完整地执行完毕,要么完全不执行,不存在执行到一半的中间状态。 在多线程或者多进程环境里,原子操作能够保证在同一时刻仅有一个线程或者进程可以对共享资源进行访问和修改,从而避免数据竞争和不一致的问题。
高性能:由于 CAS 是无锁算法,避免了锁的竞争和上下文切换带来的性能开销,因此在高并发场景下具有较高的性能。
避免死锁:传统的锁机制在使用不当的情况下可能会导致死锁问题,而 CAS 操作不存在死锁的风险。
ABA 问题:CAS 操作在比较内存位置的值时,只关注值是否相等,而不关心值的变化过程。如果一个值从 A 变为 B,再从 B 变回 A,CAS 操作会认为值没有发生变化,从而继续进行更新操作。这种情况被称为 ABA 问题。
自旋开销:在 CAS 操作失败时,通常会采用自旋的方式不断重试,直到操作成功。如果竞争非常激烈,自旋会消耗大量的 CPU 资源,降低系统性能。
互斥锁(Mutex)
定义:互斥锁(Mutual Exclusion Lock)是一种用于保护共享资源的同步原语,确保同一时间只有一个线程可以访问该资源。当一个线程获取到互斥锁时,其他线程如果尝试获取该锁,会被阻塞,直到持有锁的线程释放锁。
工作原理
应用场景:适用于锁的持有时间较长、线程竞争较为激烈的场景,例如对数据库的读写操作、文件的访问
自旋锁(Spin Lock)
定义:自旋锁是一种忙等待的锁机制。当一个线程尝试获取自旋锁时,如果锁已经被其他线程持有,该线程不会进入阻塞状态,而是会不断地循环检查锁的状态,直到锁被释放。
工作原理
应用场景:适用于锁的持有时间非常短、线程竞争不激烈的场景,例如在一些内核代码中对临界区的保护。
时间判断:临界资源访问时间和锁切换所花费的时间相比
原子性可以保证在同一时刻只有一个线程或进程能够对共享资源进行特定操作,避免了多个线程或进程同时修改共享资源而引发的错误。
单核单CPU
多核多CPU
存储体系结构
三级缓存cache:为了解决CPU运算速度与内存访问速度不匹配的问题
写回策略(write-back)
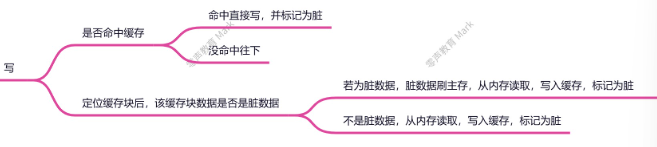
1.写
2.读
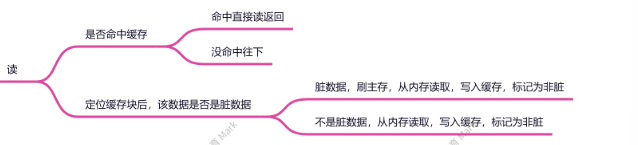
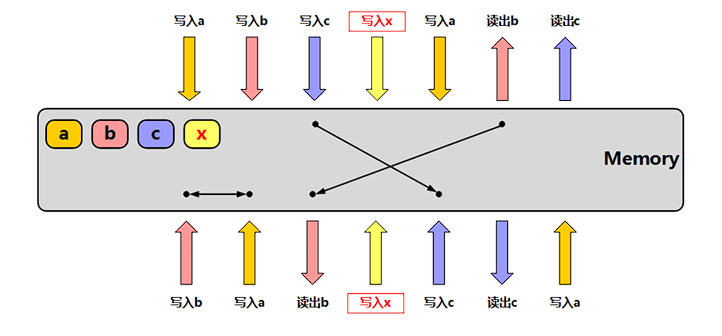
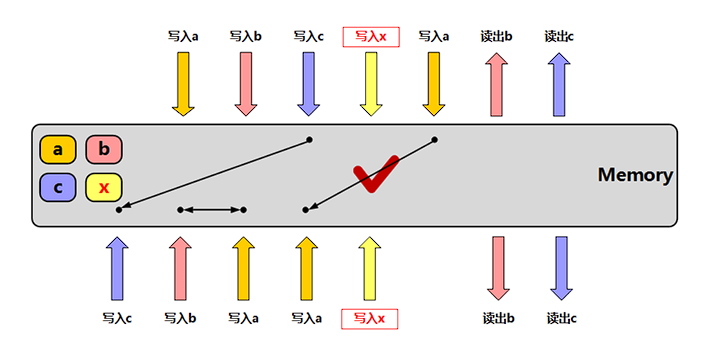
基于写会策略会产生缓存不一致的问题
缓存一致性
问题产生的原因:CPU是多核的,会访问到未同步的数据
解决方法:
写传播(Write Propagation)
定义:写传播是解决缓存一致性问题的一种基本策略,其核心目标是确保在多处理器系统中,当一个处理器对共享数据进行写操作时,这个写操作的结果能够被其他处理器感知到,进而保证所有处理器的缓存中该数据副本的一致性。
工作原理:当一个处理器对其缓存中的数据进行写操作时,需要将这个写操作传播到其他处理器的缓存或者主存中。具体的传播方式可以分为写直达(Write-Through)和写回(Write-Back)两种:
事务串行化(Transaction Serialization)
定义:事务串行化是数据库管理系统中用于保证事务并发执行正确性的一种隔离级别。事务是一组不可分割的数据库操作序列,事务串行化要求所有事务按照某种顺序依次执行,就好像这些事务是一个接一个串行执行的一样,从而避免了并发执行可能带来的数据不一致问题。
工作原理:在事务串行化隔离级别下,数据库系统会对事务进行排序,并按照这个顺序依次执行。为了实现这一点,数据库系统通常会使用锁机制来保证同一时间只有一个事务可以访问和修改共享数据。当一个事务获得了所需的锁后,其他事务必须等待该事务释放锁后才能继续执行。
优缺点
MESI 一致性协议
定义:MESI 协议是一种广泛使用的缓存一致性协议,它是基于总线监听机制实现的。MESI 协议定义了缓存行的四种状态:Modified(已修改)、Exclusive(独占)、Shared(共享)和 Invalid(无效),通过这四种状态的转换来保证缓存一致性。
四种状态
工作原理:每个处理器的缓存控制器会监听系统总线,当其他处理器对共享数据进行操作时,会通过总线广播相应的消息。缓存控制器根据接收到的消息和当前缓存行的状态,进行状态转换和数据更新。
为什么会有原子序的问题?
内存序规定了什么?
6种不同的内存序
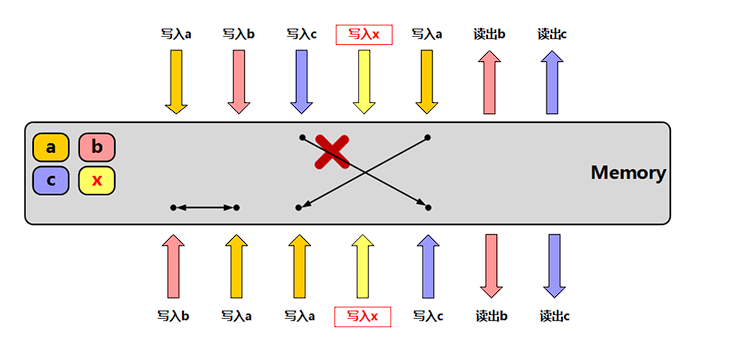
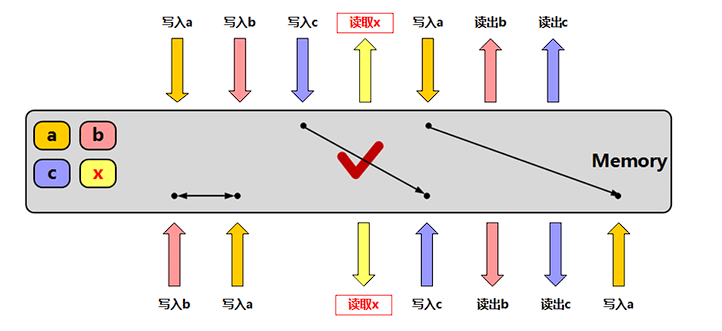
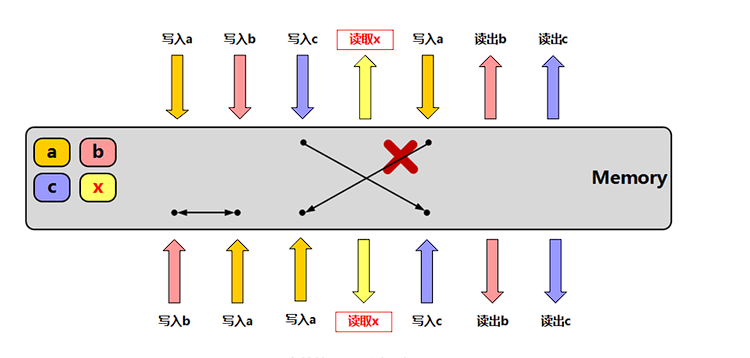
| 在多线程情况下是否保证 | 可见性 | 顺序性 |
| memory_order_relaxed | x | x |
| memory_order_acquire | √ | √ |
| memory_order_release | √ | √ |
| memory_order_consume | - | - |
| memory_order_acq_rel | √ | √ |
| memory_order_seq_cst | √ | √ |
std::shared_ptr 采用引用计数的方式来管理对象。当一个 std::shared_ptr 被创建并指向一个对象时,该对象的引用计数会被初始化为 1。每当有新的 std::shared_ptr 指向同一个对象时,引用计数就会加 1;而当一个 std::shared_ptr 被销毁(例如离开其作用域)或者被重新赋值指向其他对象时,引用计数会减 1。当引用计数变为 0 时,意味着没有任何 std::shared_ptr 再指向该对象,此时 std::shared_ptr 会自动释放该对象所占用的内存。
我们用原子变量来实现shared_ptr种引用技术的实现
#pragma once
#include <atomic>
// 自定义的 shared_ptr 模板类,用于管理动态分配的对象
template <typename T>
class shared_ptr {
public:
// 默认构造函数,初始化 ptr_ 为 nullptr,ref_count_ 也为 nullptr
// 表示这个 shared_ptr 不管理任何对象
shared_ptr() : ptr_(nullptr), ref_count_(nullptr) {}
// 带参数的构造函数,接受一个指向 T 类型对象的指针
// 使用 explicit 关键字防止隐式转换
// 如果传入的指针不为空,创建一个新的原子引用计数对象并初始化为 1
// 否则,ref_count_ 为 nullptr
explicit shared_ptr(T* ptr) : ptr_(ptr), ref_count_(ptr ? new std::atomic<std::size_t>(1) : nullptr) {}
// 析构函数,调用 release 方法来释放管理的对象和引用计数
~shared_ptr() {
release();
}
// 拷贝构造函数,用于创建一个新的 shared_ptr 并共享另一个 shared_ptr 管理的对象
// 复制 ptr_ 和 ref_count_
// 如果 ref_count_ 不为空,将引用计数加 1
shared_ptr(const shared_ptr<T>& other) : ptr_(other.ptr_), ref_count_(other.ref_count_) {
if (ref_count_) {
// 使用 std::memory_order_relaxed 进行原子操作,只保证原子性,不保证顺序
ref_count_->fetch_add(1, std::memory_order_relaxed);
}
}
// 拷贝赋值运算符,用于将一个 shared_ptr 的值赋给另一个 shared_ptr
// 首先检查是否是自我赋值,如果不是则释放当前管理的对象和引用计数
// 然后复制 ptr_ 和 ref_count_,如果 ref_count_ 不为空,将引用计数加 1
shared_ptr<T>& operator=(const shared_ptr<T>& other) {
if (this != &other) {
release();
ptr_ = other.ptr_;
ref_count_ = other.ref_count_;
if (ref_count_) {
ref_count_->fetch_add(1, std::memory_order_relaxed);
}
}
return *this;
}
// noexcept 表示这个函数不会抛出异常,编译器可以生成更高效的代码
// 移动构造函数,用于将另一个 shared_ptr 的所有权转移到当前 shared_ptr
// 复制 ptr_ 和 ref_count_,并将原 shared_ptr 的 ptr_ 和 ref_count_ 置为 nullptr
shared_ptr<T>(shared_ptr<T>&& other) noexcept : ptr_(other.ptr_), ref_count_(other.ref_count_) {
other.ptr_ = nullptr;
other.ref_count_ = nullptr;
}
// 移动赋值运算符,用于将另一个 shared_ptr 的所有权转移到当前 shared_ptr
// 首先检查是否是自我赋值,如果不是则释放当前管理的对象和引用计数
// 然后复制 ptr_ 和 ref_count_,并将原 shared_ptr 的 ptr_ 和 ref_count_ 置为 nullptr
shared_ptr<T>& operator=(shared_ptr<T>&& other) noexcept {
if (this != &other) {
release();
ptr_ = other.ptr_;
ref_count_ = other.ref_count_;
other.ptr_ = nullptr;
other.ref_count_ = nullptr;
}
return *this;
}
// 解引用运算符重载,返回管理对象的引用
// 允许像使用普通指针一样使用 shared_ptr 进行解引用操作
T& operator*() const {
return *ptr_;
}
// 箭头运算符重载,返回管理对象的指针
// 允许像使用普通指针一样使用 shared_ptr 调用对象的成员函数
T* operator->() const {
return ptr_;
}
// 获取当前 shared_ptr 管理对象的引用计数
// 如果 ref_count_ 不为空,使用 std::memory_order_acquire 加载引用计数的值
// 否则返回 0
std::size_t use_count() const {
return ref_count_ ? ref_count_->load(std::memory_order_acquire) : 0;
}
// 获取管理对象的原始指针
T* get() const {
return ptr_;
}
// 重置 shared_ptr 管理的对象
// 首先释放当前管理的对象和引用计数
// 然后将 ptr_ 指向新的对象,如果新对象不为空,创建一个新的引用计数对象并初始化为 1
void reset(T * p = nullptr) {
release();
ptr_ = p;
ref_count_ = p ? new std::atomic<std::size_t>(1) : nullptr;
}
private:
// 释放管理的对象和引用计数
// 使用 std::memory_order_acq_rel 进行原子操作,保证操作的原子性和顺序
// 如果引用计数减 1 后变为 1,表示这是最后一个引用,释放对象和引用计数
void release() {
if (ref_count_ && ref_count_->fetch_sub(1, std::memory_order_acq_rel) == 1) {
delete ptr_;
delete ref_count_;
}
}
// 指向管理对象的指针
T* ptr_;
// 指向原子引用计数对象的指针
std::atomic<std::size_t>* ref_count_;
};



