



272
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本次作业框架如下:
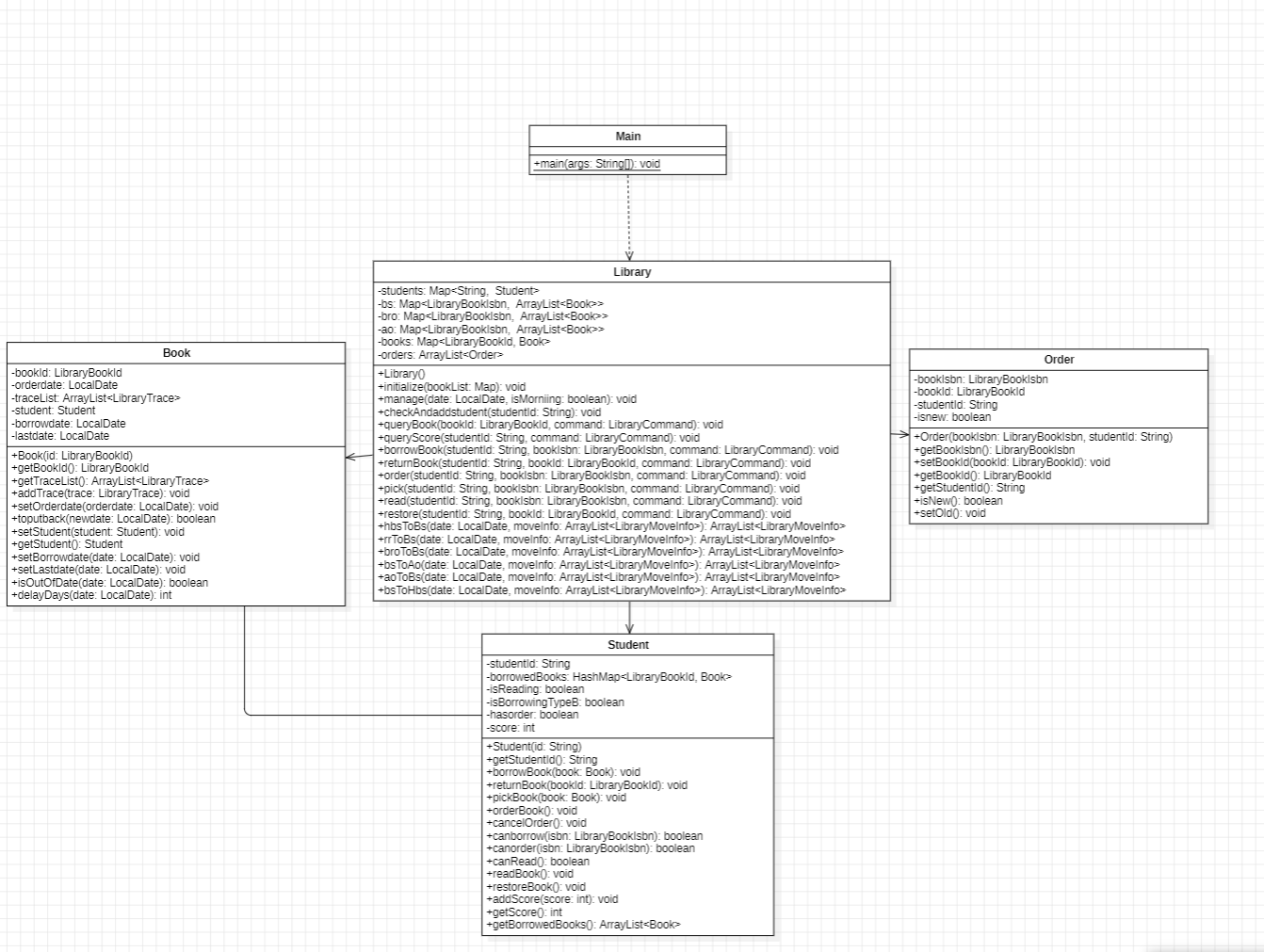
事实上,就是所有具体的功能交给library实现,而其中用来表示关系的类由人,书,指令。library中间用hashmap来记录不同处有哪些书。
本次作业的第一次,先做了类图,后两次先有了代码,才有了uml图(毕竟每次就只要改个30-50行)。总体上,或许是因为第一次的时候,水平太差,画出来的uml图,在实际操作中难以实现。第一次实验本来计划是将所有书可以放的地方作为类,library作为信息中转,但是在实现的时候,发现这并不聪明,耦合程度非常高,这是因为每个类可能都要做很多类似的事,不断传数据。
经过这3次开发。我认为类图,最好是想明白需要哪些类,然后考虑类之间的关联关系,比如这次作业中本质上是library将任务中一部分交给student和book。最后想想数据应该怎么存,便于传输和判断,也就是确定对象。对于方法,我觉得规划好library这一对接输入输出的类就可以了,毕竟别的类只要想好能干嘛就行,具体的实现等到任务下放再写也不迟。
而对于状态图,我想第一次作业这样从0开发的可能有些用,毕竟这对于对题意的理解有帮助。而放在第二次作业,就只能作为一种验证,事实上用处就不大了。
我最常用的是豆包,第三单元用了Gemini。事实上一些经典算法,他们都能很好胜任,实现一些名字就能说明的方法,只要按Tab就可以。但是,如果要进行大规模的纠错以及写,Gemini明显正确率非常高,尤其是针对jml写的时候。
我发现我们实验课对于大模型,一直更多将其作为一个实现的方法,也就是希望AI给出正确的代码,而这无论如何提示事实上都非常困难,而且由于大模型写出来的代码优势非常晦涩,难以纠错。我认为大模型更好用的是将它作为一个大型搜索引擎,以及帮助拓宽框架思路。也就是让他做一些抽象的事情,以及查询一些知识型的内容。举个例子,比如现在有一个循环边查边删,你可以放心的交给大模型实现正确的方法,大模型在逻辑清晰的时候正确率非常高。另一方面,你可以直接将题目交给大模型,它可以很快返回一个虽然不一定对,甚至不一定能跑的代码,但是它大致的关于类与状态的思路,都是值得学习的。(毕竟,比起我们这种第一次设计的,大模型再愚蠢,也很可能做的比我好的多)
我觉得这方面的进步还是非常明显的。Unit1不参考学长的博客基本毫无思路,而Unit2已经可以有一些自己的想法了,后两个单元,已经可以自己写了(可能是题目简单了)。我认为我确实对低耦合有了一定的理解,甚至我觉得最大的推手不是作业内容,而是checkstyle,他教会了我写代码应该把该下放的内容下放,该抽象的部分抽象。另一方面,我对层次化有了一定的理解。现在我认为代码有两个初始端,一边是对接要求的部分,一边是最基本的对容器的维护。写代码就是用正确的逻辑把这两者串起来。串的过程就是层次化的过程,串一次就是一个层次。
这方面其实感觉是从无到有的进步,虽然现在还是只会手动构造边界和随机数据轰炸。从第一次完全不能测试,只能用评论区里“长”出来的评测机。第二次写的太烂,没有评测。到第三次开始寻找边界以及复杂度特别高的样例测试,第四次可以用评测机构造一些样例对拍。这其中,我觉得更多的是可以发现一些易错点,故而有了更好的评测思路。对于JUnit呢,这个感觉还是没什么用,毕竟都能完全理解要求了,对于一个不到60行的方法,很难产生什么错误,即使产生错误,我想println可以更容易地找到。
最大的收获固然是架构设计。但还有一些关于这门课的收获,我认为也是受益匪浅。第一,对于大模型的使用,从只会全文复制,到了会提炼一部分输入,得到的答案作为参考,而不是在上面修改。第二,对代码风格的改善,基本上对于不复杂的方法可以做到看名字就知道内容。(好的代码应该没有注释,而是看着代码就能理解)第三,debug的方法与心态的改善,已经对于瞪眼一下午没有收获习以为常,内心不会为此感到焦躁了。

