


272
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本单元使用UML的方式,引导我们开展正向建模。从实际体验而言,正向建模对我的感受很奇怪:由于类图设计过程中只泛泛地写方法和成员,而没有考虑实际实现,导致在设计时很难评判自己建模方案的优劣性和可行性。从个人角度还是比较习惯直接写代码的过程,但是本单元使用正向建模后,架构在每次迭代中,相较于前几个单元变化极小(不过由于题目不一样也没什么可比性)。
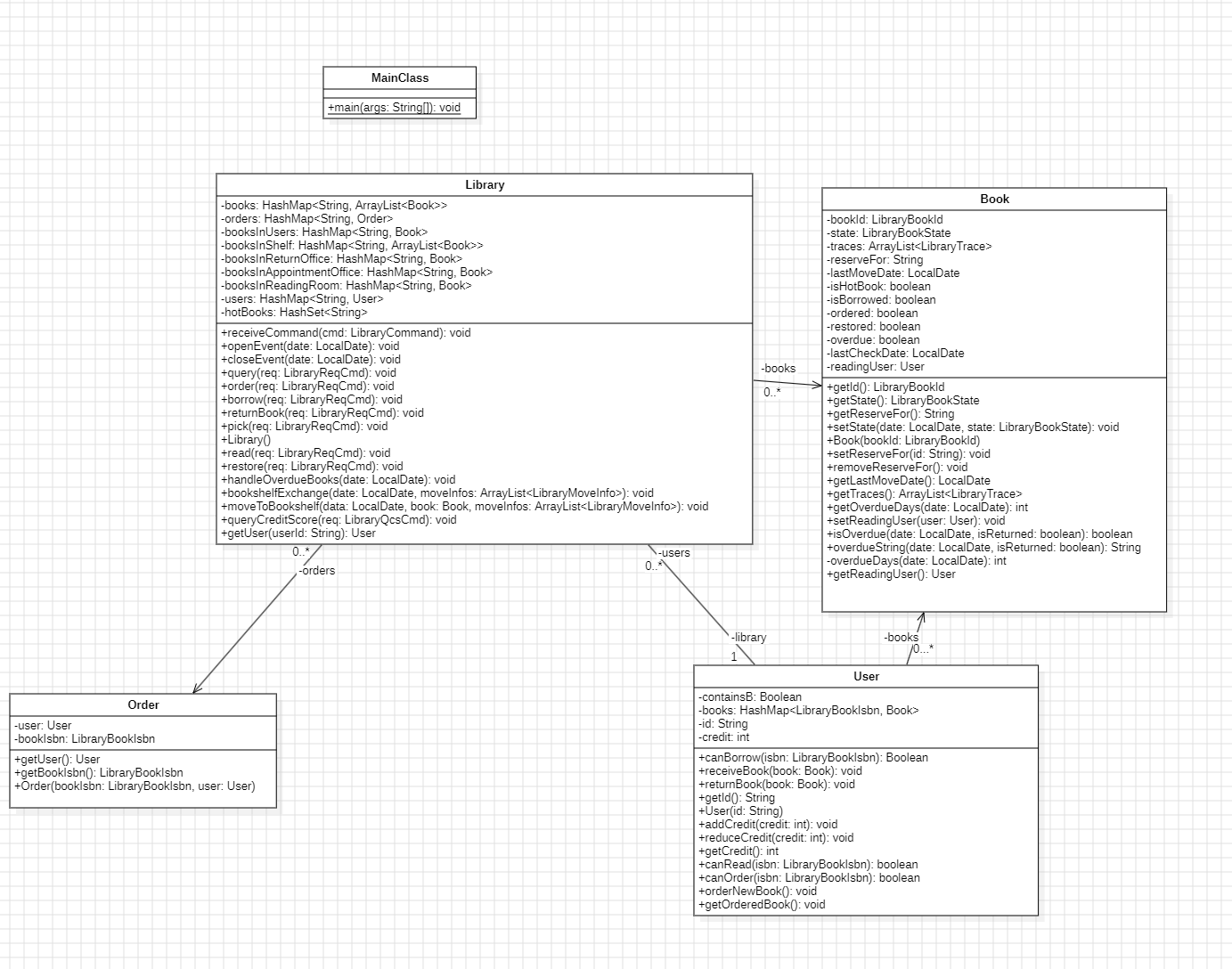
类图看似简单,其实内部还是有一定的思考的。
本单元目标是实现一个图书管理系统,需要模拟图书的位置,开馆闭馆和用户借阅等一系列规则。在架构设计方面,本单元最值得一提的是关于图书馆的不同部位(书架,归还处,预约处,用户)应当怎么管理。
一个比较清晰的方案是,将不同的地方单独建类,每个类提供方法进行书籍的移动。
这个方法最为直观,但是可以优化:由于这四个地方具有很多公共方法,因此可以直接建立一个 bookContainer 作为这四个方法的父类进行管理。
这个方法最大的优点是:架构清晰,可迭代性强。
但是考虑到 bookContainer 这样一个容器类,其没有很复杂的方法需要实现(例如 U1 Poly 的 mul),其主要方法都是一些 getter 和 setter ,那么为容器单独建类反而相对冗余,不如直接使用 HashMap,在 Library 内部统一管理。
关于图书的位置,我并没有设计单独的类来管理,而是直接在 Library 中创建了多个容器来管理其位置。这样省略了非常多的代码量,能够以简洁的代码完成任务。
本次迭代增加了热门书架,阅读和归还的相关内容,实现也较为简单,只需增加新的 booksInHotBookshelf ,并增加对于 HashSet<LibraryBookIsbn> hotBook 等相关逻辑即可。
第三次迭代增加了信用分相关的规则体系,实现也较为简单。值得一提的地方是关于逾期书籍的扣分实现,个人推荐的方式是维护“上一次扣分的时间”,计算两次对于逾期的扣分量,计算实际的 delta 来扣除分数。
我并没有在建模的第一步使用大模型来辅助,而在一些具体的函数细节上使用 copilot 来补全函数细节。关于大模型辅助架构设计方面,由于大模型的智力已经非常高,在使用时不需要太多的提示词,我们只需将任务内容丢给大模型,可以让大模型从顶层开始建模,一步一步完善细节。
在最初的设计时,没有过多的考虑如何为后续的实现留出迭代的接口,没有归约到统一的 Poly 形式,导致在第二次迭代时进行了一次重构。在第二次迭代时,为了防止以后的重构,对于引入的函数功能,单独创立了函数管理类,将功能很好的封装了起来,使用效果非常好。
第二单元架构设计使用了生产者-消费者的模式,并保留了第一单元对于特定功能单独分离的经验,将 strategy 单独设为一类,在后续迭代中这个架构设计使得增量开发极为舒适,具有很强的高内聚低耦合的特征。
第三单元由课程组直接给定了架构,这里略掉。
第四单元的架构设计看似非常简单,其实也是权衡后的结果,曾想到的 bookContainer 继承方案确实是一个高内聚低耦合的方案,但是对于一些简化的问题,强行按照教条来反而也没必要,通过适当的简化反而能写的更加顺心,更加方便迭代。
整个 OO 四个单元我都采取了评测机来编写,但是第一单元和二三四单元之间,我的数据生成思维得到了一些递进。
由于整个OO过程中我都做了很好的测试,整个OO课程中,我没有因为WA错任何点,仅有两个TLE。
评测机的数据生成器采用纯随机的方式,导致一些极端样例(如递归程度较深)几乎不可能随机到,自己代码关于这方面却存在一些漏洞,导致在互测的时候被同房 hack
二,三、四单元开始使用基于策略的数据生成器,通过预设几种数据生成策略,让数据生成器每次从中随机选择一个,大大增加了测试覆盖率,二三次单元仅因TLE错两个点(一次是电梯效率问题,一次是Unit3 的TLE)。整体还是很不错的。
战斗,爽!
在整个OOpre和OO的过程中,我的收获是相当大的,之前从来没有什么架构设计的思维,现在已经培养的相对很完善了,对于面向对象的理解也已经很深刻了,深刻的体会到了其在开发中的优点。
感觉从来没有一门课能像OO让我这么尽兴了,也没想到过自己最终能拿到强测+互测总失分只有33分左右的好成绩。
整个OO过程中我都是采用相当保守的策略,适当的舍弃性能分,来保证正确性。事实证明这是相当正确的,为了微不足道的性能分需要付出相当大的工作量,甚至可能引入新的bug,没有必要人云亦云跟着别人一起卷性能。
感觉OO是我上过最好的绝世好课,也希望我能当上OO助教,再陪伴OO一年~

