



39
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享基于语言查询的视频片段定位任务(Temporal Language Grounding):该任务是给定一个视频和一段描述语句,通过融合视觉和语言两种模态的信息,在视频中定位出语言所描述内容的视频片段。随着高清摄像头的普及以及网络媒体的快速发展,每天都会出现大量各式各样的视频,自动化的视频处理技术就被广泛应用在公共场合下的安全监控、社交媒体上视频内容的审核中,作为视觉-文本的跨模态任务,基于语言查询的视频片段定位也受到了越来越多的关注。
一方面,已有的视频片段定位方法通常只考虑了视频片段和整个句子的关系,而忽略了视频片段和句子中每个词语这种更加细致的关系,这样就不能全面地交互视觉和语言的信息,上交和云从联合团队的研究者们提出了一种coarse-and-fine的交互方式,从粗粒度和细粒度的角度同时考虑了视频片段-句子层面和关系和视频片段-词语层面的关系。另一方面,现有的工作往往忽视了不同视频片段之间的关系,或者仅仅采用了几层卷积网络的堆叠,存在计算量大、有噪声影响等缺点,本文的研究者们提出了一种稀疏连接的图网络,仅仅考虑了起始或者终止时间相同的视频片段,高效地建模了不同视频片段之间的关系,帮助模型更好地区分视觉上相似的视频片段。

论文地址:https://arxiv.org/abs/2110.05717
代码地址:https://github.com/Huntersxsx/RaNet
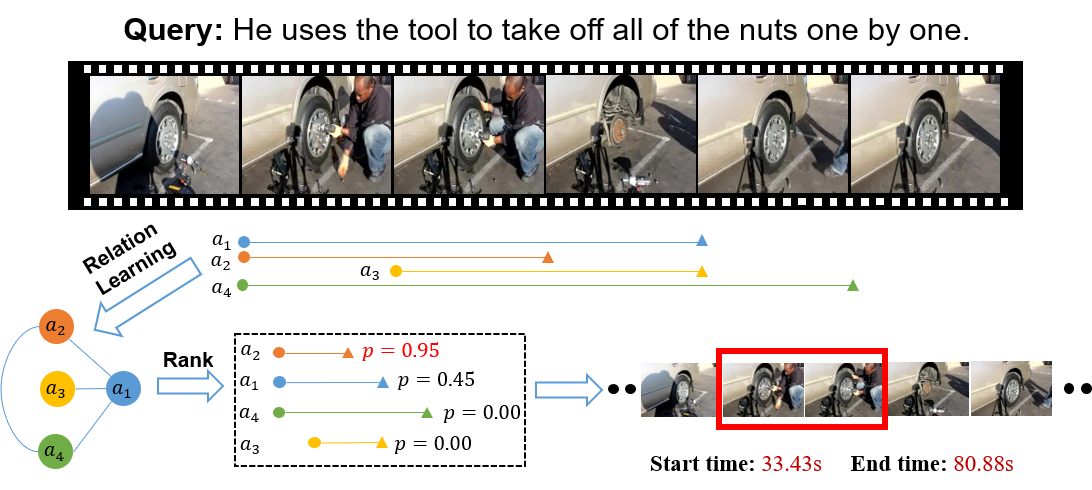
研究者们认为,基于语言查询的视频片段定位任务(Temporal Language Grounding),在某种程度上和自然语言理解中的多项选择阅读理解任务(Multi-choice Reading Comprehension)类似,可以把给定的视频、查询语言以及候选的视频片段分别类比为阅读理解中的文章、问题和候选答案。在将问题转化为阅读理解任务之后,研究者们提出了RaNet来解决该问题。
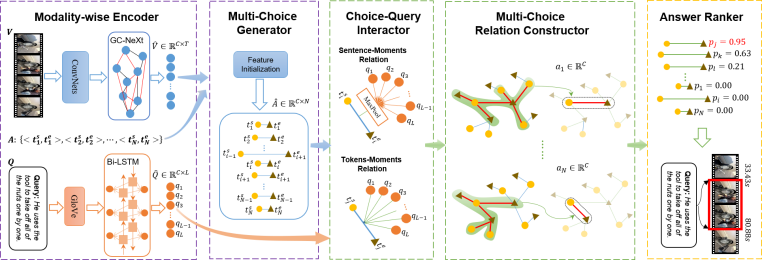
RaNet一共包含5个部分:(1)多模态的特征编码模块;(2)候选视频片段的生成模块;(3)候选视频片段和查询语句的交互模块;(4)不同视频片段的关系构建模块;(5)结果选择模块。
- 特征编码模块中,研究者们采用了在时序动作检测(Temporal Action Localization)中表现优异的GC-NeXt来获取视频序列中的时序信息,使用双向的LSTM来获取语言信息的长时间依赖。
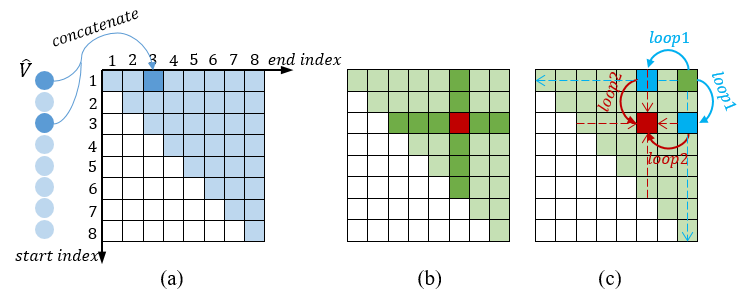
- 候选视频片段生成模块中,研究者们借鉴了之前工作2D-TAN的方式,构建了一个二维的时序网格图,每一个小网格都代表一个候选视频片段,其特征是由起始时间帧的特征和终止时间帧的特征串联而得。
- 视觉语言交互模块中,研究者们同时构建了视频片段-句子层面的关系和视频片段-单词层面的关系。对于视频片段和句子的关系,研究者们之间对语言特征进行max-pooling,然后和视频片段特征进行点乘。对于视频片段和单词的关系,研究者们通过语言特征和视频片段特征首先构建出一个注意力权重矩阵,然后再与视频片段特征交互,动态地生成query-aware的视频片段表征。这种粗粒度和细粒度结合的方式能够充分地交互视觉和语言两种模态之间的信息。
- 视频片段关系构建模块中,研究者们将每个候选视频片段视作图的点,将这些视频片段之间的关系视作图的边,构建了视频片段关系的图网络模型。考虑到重叠比较高的视频片段关联性更强,研究者们在构建图时仅考虑了和当前候选视频片段具有相同起始时间或者终止时间的视频片段,在网格图中就是一种十字架的形式。这样构建图的方式不仅可以减少不相关视频片段带来的噪声影响,还能有效提高模型的效率。
- 结果选择模块中,研究者们采用一个卷积层和sigmoid激活层为每个候选视频片段进行打分,根据得分从大到小排序,选择top-1或者top-5作为最终的预测视频片段。
最后,研究者们使用了alignment loss对模型进行了训练:
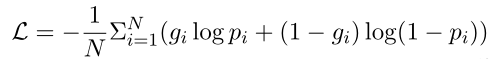
研究者们通过大量的实验验证了RaNet对于基于语言查询的视频片段定位任务的有效性。
本文在3个常见数据集TACoS、Charades-STA、ActivityNet Captions上,采用了Rank n@m评价指标,与以往的工作进行了对比,在3个数据集上基本都取得了SOTA的表现。
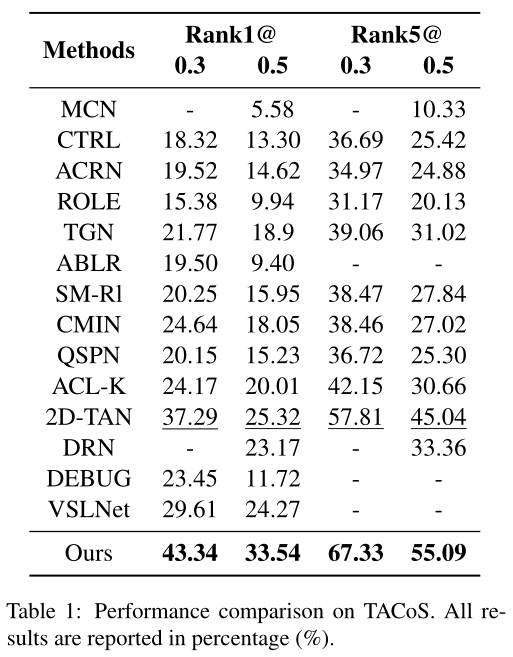
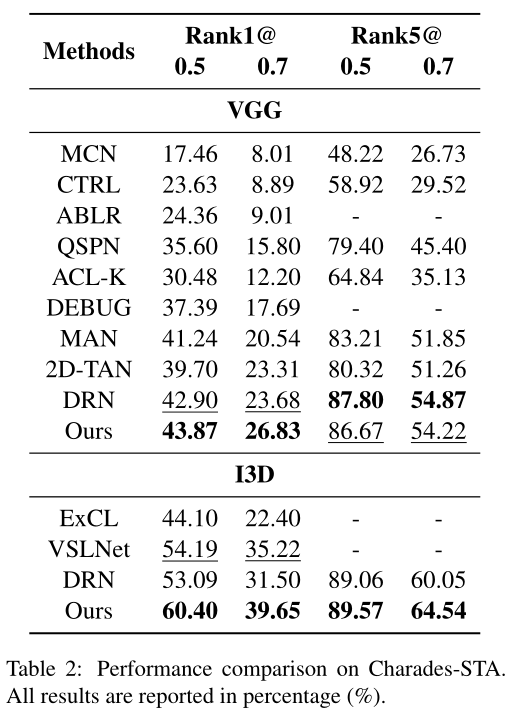
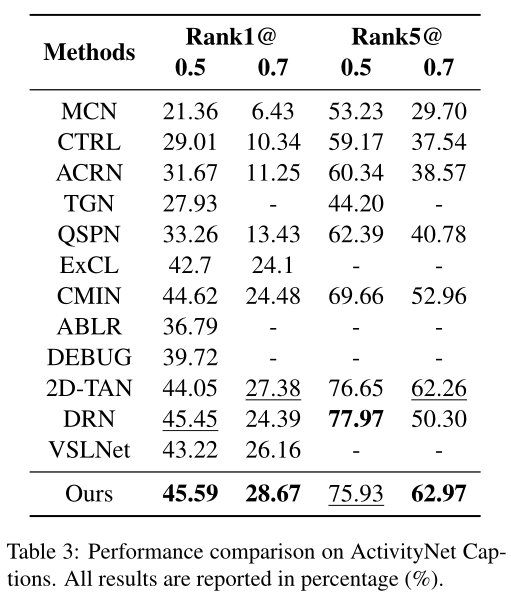
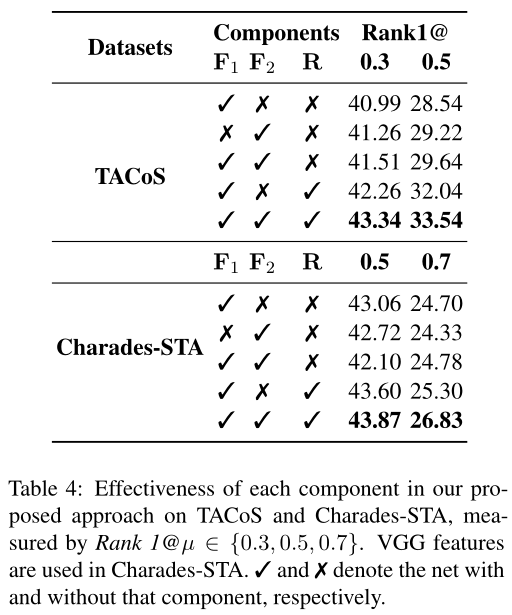
为了突显出模型中每个模块的重要性,研究者们做了消融实验,从结果来看,同时考虑视频片段和句子的关系,以及视频片段和单词的关系,比单独考虑这两者带来的收益要多。当同时构建不同视频片段之间的关系时,模型能够更加精准地对视频片段进行定位。
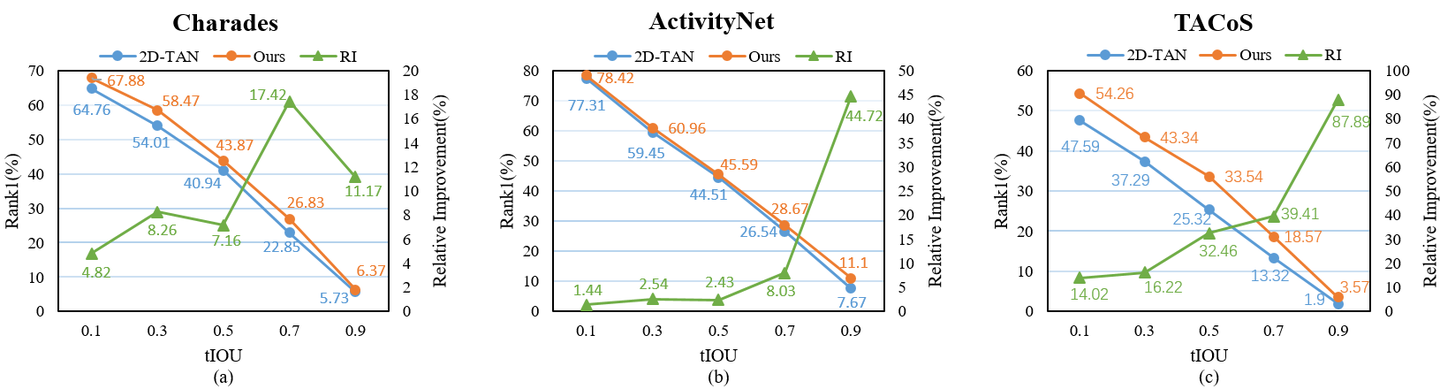
研究者们还与之前SOTA模型2D-TAN比较了在不同IoU上的相对提升率,可以发现,在越高的IoU上,本文的RaNet提升得更加明显。
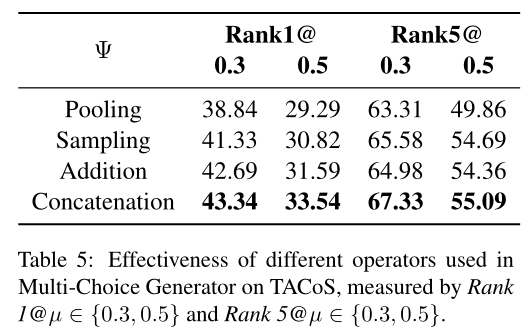
研究者们比较了Pooling、Sampling、Addition、Concatenation这四种不同的视频片段特征的生成方式,实验发现更加关注边界特征的Concatenation操作表现更好。
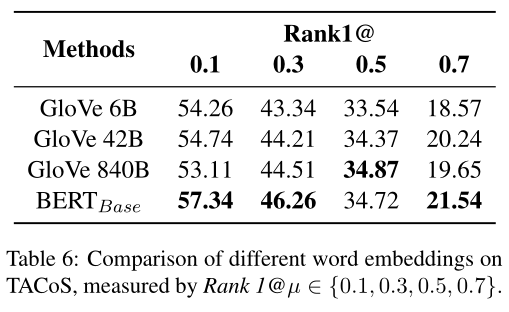
不同word embeddings的影响:
为了探寻不同的词向量编码对实验结果对的影响,研究者们还比较了不同word embeddings的表现,发现越强的语言表征更有益于模型精准地定位视频片段。
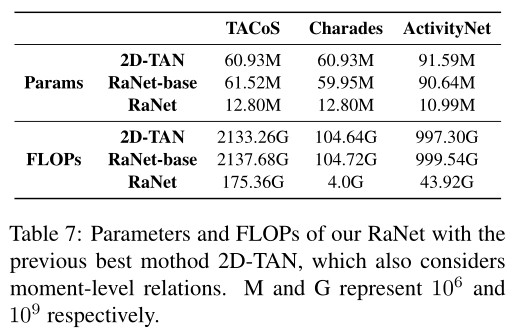
研究者们还展示了模型在TACoS数据集上的参数量和FLOPs,并和之前的2D-TAN模型进行了对比,由于在构建视频片段关系的模块中本文采用的是稀疏连接的图网络模型,所以参数量大大减小,效率得到了提升。
最后,研究者们还通过可视化的例子展现了模型的能力。

针对基于语言查询的视频片段定位这个任务,上交-云从的联合研究团队提出了探索多层关系的RaNet,将视频片段定位类比为自然语言处理中的多项选择阅读理解,同时建模了视频片段-句子层面和视频片段-单词层面的关系,并且提出了一种稀疏连接的图网络高效地建模了不同视频片段之间的关系,在公开数据集上取得了SOTA表现,更多的技术细节请参考[RaNet: arxiv paper](https://arxiv.org/abs/2110.05717)。
参考文献
[1] Songyang Zhang, Houwen Peng, Jianlong Fu, and Jiebo Luo. 2020b. Learning 2d temporal adjacent networks for moment localization with natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12870–12877.
[2] Mengmeng Xu, Chen Zhao, David S. Rojas, Ali Thabet, and Bernard Ghanem. 2020. G-tad: Sub-graph localization for temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
[3] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. 2019. Ccnet: Criss-cross attention for semantic segmentation. In
2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 603–612.
