
12,305
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享最近本人来开始摸索微调训练,因为需要部署在ollama上面,所以需要转换成.gguf格式,但是部署上了ollama后,发现结果和预期差异很大,所以一步一步往回追溯,最后发现使用convert_hf_to_gguf.py转换后的.gguf模型,使用llama-cli运行时的输出,和预期的差异很大,使用训练数据来测试,结果完全不对。另外部署上ollama后相同的输入数据,答案和上一步直接运行.gguf差异也很大
首先是转成.gguf前最后一步,验证adapter合并后模型模型的代码:
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
pipeline,
BitsAndBytesConfig
)
from peft import PeftModel, PeftConfig
from datasets import load_dataset
import json
import time
# 1. 设置路径
merge_model_path = "/home/ps/pyCode/merged_model" # 原始基础模型
test_data_path = "/home/ps/文档/trainingData" # 测试数据集
# 2. 加载基础模型和分词器
tokenizer = AutoTokenizer.from_pretrained(
merge_model_path,
trust_remote_code=True,
padding_side="right"
)
tokenizer.pad_token = tokenizer.eos_token # 确保设置填充token
# 配置量化(可选,减少显存占用)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
merge_model = AutoModelForCausalLM.from_pretrained(
merge_model_path,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.bfloat16
)
# 4. 创建文本生成管道
text_generator = pipeline(
"text-generation",
model=merge_model,
#device=model.device,
max_new_tokens=256, # 最大生成长度
do_sample=True, # 启用随机采样
temperature=0.7, # 控制随机性 (0-1)
top_p=0.9, # 核采样参数
tokenizer=tokenizer,
eos_token_id=tokenizer.eos_token_id
)
# 加载测试数据集
#test_data = load_dataset("json", data_files=test_data_path+ "/*.json", split="train")
outputs = text_generator([{"role":"system","content":"根据输入的症状描述或诊断症状名,告诉我对应的症状名,对应的贴敷方案"},{"role":"user","content":f"开放性脏器,经常反复感染,是妇科的常见病,多发病。临床上以小腹不适,活动后加重,腰酸,腿酸,白带过多,外阴瘙痒。盆腔炎性疾病包括女性生殖道器官及其周围组织(子宫、附件、盆腔腹膜等组织)。"}],
return_full_text=False, # 不返回输入文本
num_return_sequences=1,
)
# 提取生成的文本
response = outputs[0]['generated_text'].strip()
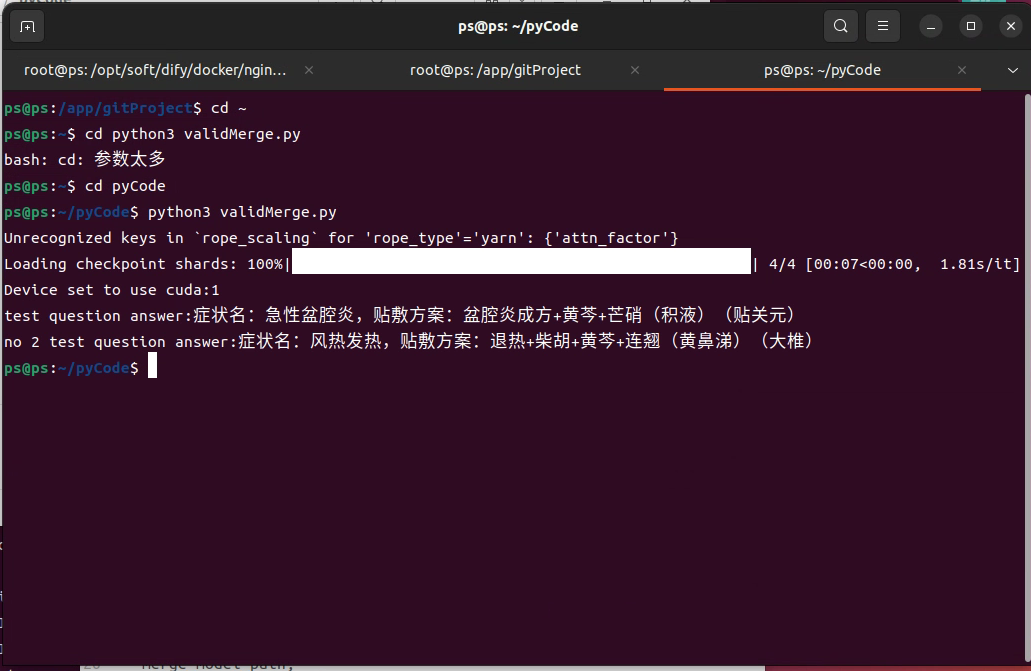
print(f"test question answer:{response}");
outputs = text_generator("<|begin▁of▁sentence|>根据输入的症状描述或诊断症状名,告诉我对应的症状名,对应的贴敷方案<|User|>黏黄鼻涕,舌质红苔黄,眼屎多,四肢暖,头痛,汗出热不解,咽红,大椎湿。发热的3-5天。<|Assistant|>",
return_full_text=False, # 不返回输入文本
num_return_sequences=1,
)
# 提取生成的文本
response = outputs[0]['generated_text'].strip()
print(f"no 2 test question answer:{response}");
第二次的是按照切词器格式直接输入文本来进行测试,这两次都达到了预期,和标准答案完全一致,我这个模型的system固定为:"根据输入的症状描述或诊断症状名,告诉我对应的症状名,对应的贴敷方案"
然后使用llama.cpp进行了模型转换,指令:"python3 convert_hf_to_gguf.py /home/ps/pyCode/merged_model --outtype f16 "
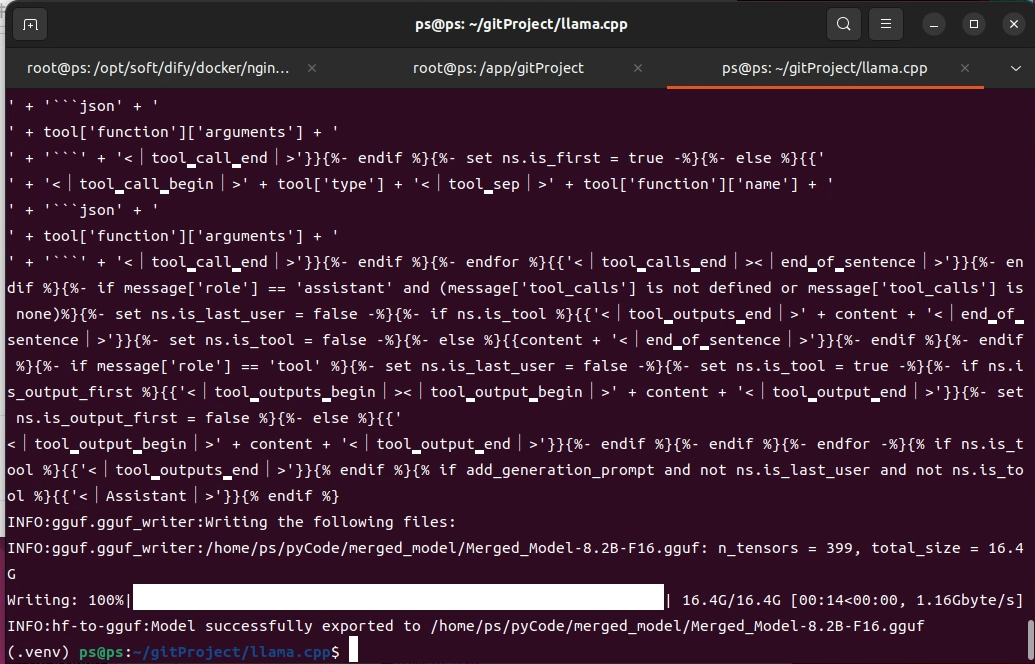
转换成功
最后运行llama-cli指令"/home/ps/gitProject/llama.cpp/build/bin/llama-cli -m Merged_Model-8.2B-F16.gguf --file prompt.txt"
prompt.txt内容如下,就是验证合并模型的第二次输入
运行结果:
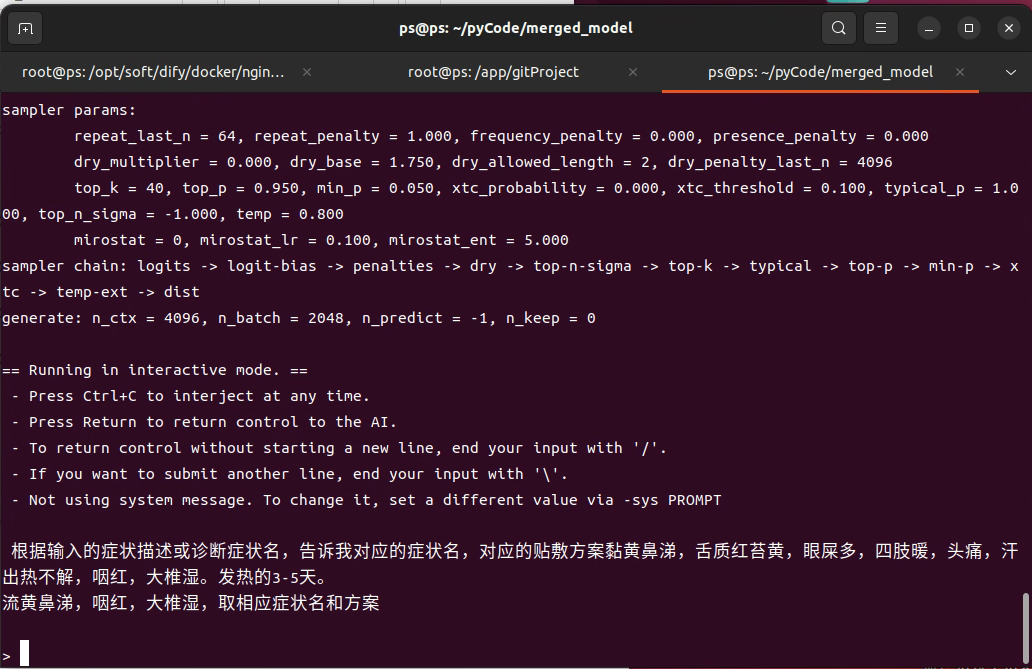
明显不对,这个问题可能是什么原因导致的?
转换的详细log,运行llama-cli的详细log我会放在下面两楼

对了,我基础模型用的是:DeepSeek-R1-Distill-Llama-8B
训练的时候没有加标签,不会不有什么影响?
使用llama-cli运行模型的详细log:
ps@ps:/pyCode/merged_model$ /home/ps/gitProject/llama.cpp/build/bin/llama-cli -m Merged_Model-8.2B-F16.gguf --file prompt.txt22.04) 12.3.0 for x86_64-linux-gnu
build: 5851 (04655063) with cc (Ubuntu 12.3.0-1ubuntu1
main: llama backend init
main: load the model and apply lora adapter, if any
llama_model_loader: loaded meta data with 30 key-value pairs and 399 tensors from Merged_Model-8.2B-F16.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen3
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Merged_Model
llama_model_loader: - kv 3: general.size_label str = 8.2B
llama_model_loader: - kv 4: qwen3.block_count u32 = 36
llama_model_loader: - kv 5: qwen3.context_length u32 = 131072
llama_model_loader: - kv 6: qwen3.embedding_length u32 = 4096
llama_model_loader: - kv 7: qwen3.feed_forward_length u32 = 12288
llama_model_loader: - kv 8: qwen3.attention.head_count u32 = 32
llama_model_loader: - kv 9: qwen3.attention.head_count_kv u32 = 8
llama_model_loader: - kv 10: qwen3.rope.freq_base f32 = 1000000.000000
llama_model_loader: - kv 11: qwen3.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 12: qwen3.attention.key_length u32 = 128
llama_model_loader: - kv 13: qwen3.attention.value_length u32 = 128
llama_model_loader: - kv 14: general.file_type u32 = 1
llama_model_loader: - kv 15: qwen3.rope.scaling.type str = yarn
llama_model_loader: - kv 16: qwen3.rope.scaling.factor f32 = 4.000000
llama_model_loader: - kv 17: qwen3.rope.scaling.original_context_length u32 = 32768
llama_model_loader: - kv 18: general.quantization_version u32 = 2
llama_model_loader: - kv 19: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 20: tokenizer.ggml.pre str = qwen2
llama_model_loader: - kv 21: tokenizer.ggml.tokens arr[str,151936] = ["!", """, "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 22: tokenizer.ggml.token_type arr[i32,151936] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 23: tokenizer.ggml.merges arr[str,151387] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 24: tokenizer.ggml.bos_token_id u32 = 151643
llama_model_loader: - kv 25: tokenizer.ggml.eos_token_id u32 = 151645
llama_model_loader: - kv 26: tokenizer.ggml.padding_token_id u32 = 151645
llama_model_loader: - kv 27: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 28: tokenizer.ggml.add_eos_token bool = false
llama_model_loader: - kv 29: tokenizer.chat_template str = {% if not add_generation_prompt is de...
llama_model_loader: - type f32: 145 tensors
llama_model_loader: - type f16: 254 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = F16
print_info: file size = 15.26 GiB (16.00 BPW)
load: special_eos_id is not in special_eog_ids - the tokenizer config may be incorrect
load: special tokens cache size = 28
load: token to piece cache size = 0.9311 MB
print_info: arch = qwen3
print_info: vocab_only = 0
print_info: n_ctx_train = 131072
print_info: n_embd = 4096
print_info: n_layer = 36
print_info: n_head = 32
print_info: n_head_kv = 8
print_info: n_rot = 128
print_info: n_swa = 0
print_info: is_swa_any = 0
print_info: n_embd_head_k = 128
print_info: n_embd_head_v = 128
print_info: n_gqa = 4
print_info: n_embd_k_gqa = 1024
print_info: n_embd_v_gqa = 1024
print_info: f_norm_eps = 0.0e+00
print_info: f_norm_rms_eps = 1.0e-06
print_info: f_clamp_kqv = 0.0e+00
print_info: f_max_alibi_bias = 0.0e+00
print_info: f_logit_scale = 0.0e+00
print_info: f_attn_scale = 0.0e+00
print_info: n_ff = 12288
print_info: n_expert = 0
print_info: n_expert_used = 0
print_info: causal attn = 1
print_info: pooling type = 0
print_info: rope type = 2
print_info: rope scaling = yarn
print_info: freq_base_train = 1000000.0
print_info: freq_scale_train = 0.25
print_info: n_ctx_orig_yarn = 32768
print_info: rope_finetuned = unknown
print_info: model type = 8B
print_info: model params = 8.19 B
print_info: general.name = Merged_Model
print_info: vocab type = BPE
print_info: n_vocab = 151936
print_info: n_merges = 151387
print_info: BOS token = 151643 '<|begin▁of▁sentence|>'
print_info: EOS token = 151645 '<|end▁of▁sentence|>'
print_info: EOT token = 151645 '<|end▁of▁sentence|>'
print_info: PAD token = 151645 '<|end▁of▁sentence|>'
print_info: LF token = 198 'Ċ'
print_info: FIM PRE token = 151659 '<|fim_prefix|>'
print_info: FIM SUF token = 151661 '<|fim_suffix|>'
print_info: FIM MID token = 151660 '<|fim_middle|>'
print_info: FIM PAD token = 151662 '<|fim_pad|>'
print_info: FIM REP token = 151663 '<|repo_name|>'
print_info: FIM SEP token = 151664 '<|file_sep|>'
print_info: EOG token = 151645 '<|end▁of▁sentence|>'
print_info: EOG token = 151662 '<|fim_pad|>'
print_info: EOG token = 151663 '<|repo_name|>'
print_info: EOG token = 151664 '<|file_sep|>'
print_info: max token length = 256
load_tensors: loading model tensors, this can take a while... (mmap = true)
load_tensors: CPU_Mapped model buffer size = 15623.18 MiB
.......................................................................................
llama_context: constructing llama_context
llama_context: n_seq_max = 1
llama_context: n_ctx = 4096
llama_context: n_ctx_per_seq = 4096
llama_context: n_batch = 2048
llama_context: n_ubatch = 512
llama_context: causal_attn = 1
llama_context: flash_attn = 0
llama_context: freq_base = 1000000.0
llama_context: freq_scale = 0.25
llama_context: n_ctx_per_seq (4096) < n_ctx_train (131072) -- the full capacity of the model will not be utilized
llama_context: CPU output buffer size = 0.58 MiB
llama_kv_cache_unified: CPU KV buffer size = 576.00 MiB
llama_kv_cache_unified: size = 576.00 MiB ( 4096 cells, 36 layers, 1 seqs), K (f16): 288.00 MiB, V (f16): 288.00 MiB
llama_kv_cache_unified: LLAMA_SET_ROWS=0, using old ggml_cpy() method for backwards compatibility
llama_context: CPU compute buffer size = 304.75 MiB
llama_context: graph nodes = 1446
llama_context: graph splits = 1
common_init_from_params: setting dry_penalty_last_n to ctx_size = 4096
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 40
main: chat template is available, enabling conversation mode (disable it with -no-cnv)
*** User-specified prompt will pre-start conversation, did you mean to set --system-prompt (-sys) instead?
main: chat template example:
You are a helpful assistant
<|User|>Hello<|Assistant|>Hi there<|end▁of▁sentence|><|User|>How are you?<|Assistant|>
system_info: n_threads = 40 (n_threads_batch = 40) / 80 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX = 1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | AVX512 = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
main: interactive mode on.
sampler seed: 3503991445
sampler params:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
dry_multiplier = 0.000, dry_base = 1.750, dry_allowed_length = 2, dry_penalty_last_n = 4096
top_k = 40, top_p = 0.950, min_p = 0.050, xtc_probability = 0.000, xtc_threshold = 0.100, typical_p = 1.000, top_n_sigma = -1.000, temp = 0.800
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampler chain: logits -> logit-bias -> penalties -> dry -> top-n-sigma -> top-k -> typical -> top-p -> min-p -> xtc -> temp-ext -> dist
generate: n_ctx = 4096, n_batch = 2048, n_predict = -1, n_keep = 0
== Running in interactive mode. ==
根据输入的症状描述或诊断症状名,告诉我对应的症状名,对应的贴敷方案黏黄鼻涕,舌质红苔黄,眼屎多,四肢暖,头痛,汗出热不解,咽红,大椎湿。发热的3-5天。
流黄鼻涕,咽红,大椎湿,取相应症状名和方案
llama_perf_sampler_print: sampling time = 3.73 ms / 83 runs ( 0.04 ms per token, 22269.92 tokens per second)
llama_perf_context_print: load time = 3262.51 ms
llama_perf_context_print: prompt eval time = 917.59 ms / 63 tokens ( 14.56 ms per token, 68.66 tokens per second)
llama_perf_context_print: eval time = 10956.15 ms / 19 runs ( 576.64 ms per token, 1.73 tokens per second)
llama_perf_context_print: total time = 214823.91 ms / 82 tokens
Interrupted by user
转换成gguf的详细log:
(.venv) ps@ps:~/gitProject/llama.cpp$ python3 convert_hf_to_gguf.py /home/ps/pyCode/merged_model
INFO:hf-to-gguf:Loading model: merged_model
WARNING:hf-to-gguf:Failed to load model config from /home/ps/pyCode/merged_model: The checkpoint you are trying to load has model type qwen3 but Transformers does not recognize this architecture. This could be because of an issue with the checkpoint, or because your version of Transformers is out of date.
WARNING:hf-to-gguf:Trying to load config.json instead
INFO:hf-to-gguf:Model architecture: Qwen3ForCausalLM
WARNING:hf-to-gguf:Failed to load model config from /home/ps/pyCode/merged_model: The checkpoint you are trying to load has model type qwen3 but Transformers does not recognize this architecture. This could be because of an issue with the checkpoint, or because your version of Transformers is out of date.
WARNING:hf-to-gguf:Trying to load config.json instead
INFO:gguf.gguf_writer:gguf: This GGUF file is for Little Endian only
INFO:hf-to-gguf:Exporting model...
INFO:hf-to-gguf:gguf: loading model weight map from 'model.safetensors.index.json'
INFO:hf-to-gguf:gguf: loading model part 'model-00001-of-00004.safetensors'
INFO:hf-to-gguf:token_embd.weight, torch.float16 --> F16, shape = {4096, 151936}
INFO:hf-to-gguf:blk.0.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.0.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.0.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.0.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.0.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.0.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.0.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.0.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.0.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.0.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.0.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.1.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.1.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.1.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.1.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.1.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.1.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.1.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.1.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.1.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.1.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.1.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.2.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.2.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.2.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.2.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.2.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.2.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.2.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.2.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.2.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.2.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.2.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.3.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.3.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.3.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.3.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.3.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.3.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.3.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.3.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.3.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.3.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.3.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.4.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.4.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.4.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.4.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.4.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.4.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.4.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.4.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.4.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.4.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.4.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.5.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.5.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.5.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.5.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.5.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.5.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.5.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.5.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.5.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.5.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.5.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.6.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.6.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.6.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.6.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.6.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.6.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.6.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.6.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.6.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.6.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.6.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.7.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.7.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.7.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.7.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.7.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.7.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.7.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.7.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.7.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.7.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.7.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.8.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.8.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.8.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.8.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.8.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.8.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.8.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.8.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.8.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.8.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.8.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.9.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.9.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.9.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.9.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.9.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.9.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.9.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:gguf: loading model part 'model-00002-of-00004.safetensors'
INFO:hf-to-gguf:blk.10.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.10.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.10.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.10.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.10.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.10.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.10.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.10.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.10.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.10.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.10.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.11.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.11.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.11.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.11.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.11.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.11.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.11.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.11.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.11.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.11.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.11.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.12.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.12.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.12.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.12.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.12.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.12.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.12.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.12.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.12.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.12.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.12.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.13.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.13.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.13.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.13.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.13.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.13.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.13.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.13.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.13.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.13.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.13.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.14.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.14.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.14.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.14.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.14.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.14.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.14.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.14.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.14.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.14.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.14.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.15.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.15.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.15.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.15.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.15.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.15.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.15.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.15.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.15.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.15.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.15.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.16.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.16.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.16.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.16.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.16.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.16.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.16.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.16.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.16.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.16.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.16.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.17.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.17.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.17.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.17.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.17.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.17.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.17.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.17.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.17.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.17.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.17.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.18.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.18.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.18.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.18.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.18.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.18.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.18.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.18.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.18.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.18.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.18.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.19.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.19.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.19.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.19.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.19.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.19.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.19.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.19.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.19.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.19.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.19.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.20.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.20.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.20.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.20.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.20.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.20.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.20.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.20.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.20.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.20.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.20.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.21.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.21.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.21.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.21.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.21.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.21.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.21.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.21.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.21.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.21.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.21.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.22.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.22.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.22.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.22.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.22.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.22.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.9.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.9.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.9.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.9.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:gguf: loading model part 'model-00003-of-00004.safetensors'
INFO:hf-to-gguf:blk.22.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.22.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.22.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.22.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.22.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.23.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.23.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.23.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.23.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.23.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.23.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.23.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.23.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.23.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.23.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.23.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.24.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.24.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.24.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.24.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.24.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.24.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.24.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.24.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.24.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.24.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.24.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.25.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.25.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.25.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.25.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.25.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.25.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.25.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.25.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.25.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.25.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.25.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.26.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.26.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.26.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.26.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.26.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.26.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.26.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.26.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.26.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.26.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.26.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.27.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.27.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.27.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.27.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.27.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.27.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.27.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.27.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.27.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.27.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.27.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.28.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.28.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.28.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.28.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.28.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.28.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.28.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.28.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.28.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.28.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.28.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.29.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.29.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.29.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.29.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.29.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.29.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.29.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.29.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.29.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.29.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.29.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.30.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.30.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.30.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.30.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.30.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.30.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.30.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.30.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.30.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.30.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.30.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.31.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.31.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.31.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.31.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.31.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.31.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.31.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.31.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.31.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.31.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.31.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.32.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.32.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.32.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.32.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.32.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.32.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.32.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.32.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.32.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.32.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.32.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.33.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.33.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.33.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.33.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.33.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.33.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.33.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.33.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.33.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.33.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.33.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.34.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.34.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.34.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.34.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.34.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.34.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.34.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.34.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.34.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.34.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.34.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.35.attn_k.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:blk.35.attn_q.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.35.attn_v.weight, torch.float16 --> F16, shape = {4096, 1024}
INFO:hf-to-gguf:gguf: loading model part 'model-00004-of-00004.safetensors'
INFO:hf-to-gguf:output.weight, torch.float16 --> F16, shape = {4096, 151936}
INFO:hf-to-gguf:blk.35.attn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.35.ffn_down.weight, torch.float16 --> F16, shape = {12288, 4096}
INFO:hf-to-gguf:blk.35.ffn_gate.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.35.ffn_up.weight, torch.float16 --> F16, shape = {4096, 12288}
INFO:hf-to-gguf:blk.35.ffn_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:blk.35.attn_k_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:blk.35.attn_output.weight, torch.float16 --> F16, shape = {4096, 4096}
INFO:hf-to-gguf:blk.35.attn_q_norm.weight, torch.float16 --> F32, shape = {128}
INFO:hf-to-gguf:output_norm.weight, torch.float16 --> F32, shape = {4096}
INFO:hf-to-gguf:Set meta model
INFO:hf-to-gguf:Set model parameters
INFO:hf-to-gguf:gguf: context length = 131072
INFO:hf-to-gguf:gguf: embedding length = 4096
INFO:hf-to-gguf:gguf: feed forward length = 12288
INFO:hf-to-gguf:gguf: head count = 32
INFO:hf-to-gguf:gguf: key-value head count = 8
INFO:hf-to-gguf:gguf: rope theta = 1000000
INFO:hf-to-gguf:gguf: rms norm epsilon = 1e-06
INFO:hf-to-gguf:gguf: file type = 1
INFO:hf-to-gguf:Set model quantization version
INFO:hf-to-gguf:Set model tokenizer
INFO:gguf.vocab:Adding 151387 merge(s).
INFO:gguf.vocab:Setting special token type bos to 151643
INFO:gguf.vocab:Setting special token type eos to 151645
INFO:gguf.vocab:Setting special token type pad to 151645
INFO:gguf.vocab:Setting add_bos_token to False
INFO:gguf.vocab:Setting add_eos_token to False
INFO:gguf.vocab:Setting chat_template to {% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='', is_first_sp=true, is_last_user=false) %}{%- for message in messages %}{%- if message['role'] == 'system' %}{%- if ns.is_first_sp %}{% set ns.system_prompt = ns.system_prompt + message['content'] %}{% set ns.is_first_sp = false %}{%- else %}{% set ns.system_prompt = ns.system_prompt + '
' + message['content'] %}{%- endif %}{%- endif %}{%- endfor %}{{ bos_token }}{{ ns.system_prompt }}{%- for message in messages %}{% set content = message['content'] %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{%- set ns.is_first = false -%}{%- set ns.is_last_user = true -%}{{'<|User|>' + content + '<|Assistant|>'}}{%- endif %}{%- if message['role'] == 'assistant' %}{% if '' in content %}{% set content = content.split('')[-1] %}{% endif %}{% endif %}{%- if message['role'] == 'assistant' and message['tool_calls'] is defined and message['tool_calls'] is not none %}{%- set ns.is_last_user = false -%}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{%- endif %}{%- set ns.is_first = false %}{%- set ns.is_tool = false -%}{%- set ns.is_output_first = true %}{%- for tool in message['tool_calls'] %}{%- if not ns.is_first %}{%- if content is none %}{{'<|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '
' + 'json' + ' ' + tool['function']['arguments'] + ' ' + '' + '<|tool▁call▁end|>'}}{%- else %}{{content + '<|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '
' + 'json' + ' ' + tool['function']['arguments'] + ' ' + '' + '<|tool▁call▁end|>'}}{%- endif %}{%- set ns.is_first = true -%}{%- else %}{{'
' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '
' + 'json' + ' ' + tool['function']['arguments'] + ' ' + '' + '<|tool▁call▁end|>'}}{%- endif %}{%- endfor %}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- if message['role'] == 'assistant' and (message['tool_calls'] is not defined or message['tool_calls'] is none)%}{%- set ns.is_last_user = false -%}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + content + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{{content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_last_user = false -%}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + content + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'
<|tool▁output▁begin|>' + content + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_last_user and not ns.is_tool %}{{'<|Assistant|>'}}{% endif %}
INFO:gguf.gguf_writer:Writing the following files:
INFO:gguf.gguf_writer:/home/ps/pyCode/merged_model/Merged_Model-8.2B-F16.gguf: n_tensors = 399, total_size = 16.4G
Writing: 100%|██████████████████████████| 16.4G/16.4G [00:15<00:00, 1.09Gbyte/s]


