


6
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享AGGREGATE、FACTORY 和 REPOSITORY 是 DDD 中管理领域对象复杂生命周期的三个核心战术模式,它们三位一体,共同协作,将领域模型从概念转化为可工作的软件。
我们可以用一个生动的比喻来理解它们的关系:
想象一个高度组织化的汽车制造厂:
- AGGREGATE(聚合) 就像一条条装配线。它规定了组装一辆完整的汽车(聚合根)需要哪些零件(实体和值对象),并确保组装过程中的规则(不变条件)被遵守,比如“安装了发动机才能安装变速箱”。它是一个一致性边界。
- FACTORY(工厂) 就像专业的部件组装车间。当装配线需要一台复杂的、组装好的发动机时,它不会自己去收集活塞、曲轴等零件。它会向发动机车间(工厂)下订单,由这个车间专门负责根据蓝图(业务规则)组装出一台合格的发动机。它负责处理复杂的创建逻辑。
- REPOSITORY(仓储) 就像整个工厂的自动化立体仓库。装配线需要一辆半成品汽车时,它不会自己跑到一堆零件里去找。它只需向仓库(仓储)提供订单号(聚合根ID),仓库就会自动将整辆汽车(整个聚合)从货架上取出并送到线上。同样,当汽车组装完成,也是由仓库将其整体存放到指定位置。它提供了全局访问入口和持久化抽象。
DDD 的核心是通过构建一个反映领域知识的软件模型,来应对业务的复杂性。这个模型不是一堆散乱的概念,而是一个有机的整体,其中对象之间存在着丰富的关联。
这就带来了挑战:
AGGREGATE、FACTORY 和 REPOSITORY 就是为了解决这些挑战而生的“三板斧”。
AGGREGATE(聚合) - 定义边界与规则
没有聚合,模型就是一片混乱的海洋,你无法确定修改一个对象会影响到谁。
FACTORY(工厂) - 负责复杂对象的“诞生”
工厂是聚合生命的起点,它确保聚合“出生”时就健康强壮。
REPOSITORY(仓储) - 负责对象的“持久化生命”
orders.Add(newOrder)),可以随时从中获取或存储聚合。仓储是聚合在内存世界和持久化世界之间的桥梁,它让聚合可以“永生”。
下图清晰地展示了三者在领域对象生命周期中的核心作用与协作关系:
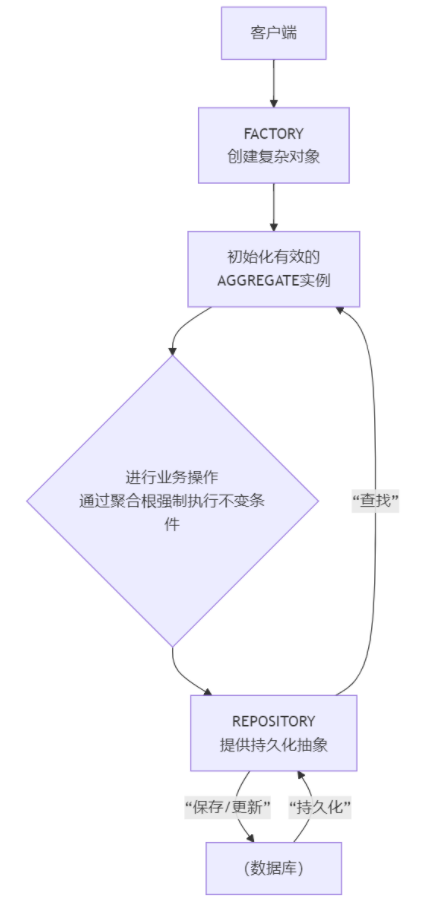
它们共同实现了 DDD 的核心目标:创建一个边界清晰、规则明确、并且能够与技术设施解耦的领域模型。没有聚合,边界就会模糊;没有工厂,复杂聚合的创建会污染业务代码;没有仓储,领域模型就会与数据库紧耦合。这三者缺一不可,是实践 DDD 战术建模最关键的基石。

