


103
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享| 这个作业属于哪个课程 | 2501_CS_SE_FZU |
|---|---|
| 这个作业要求在哪里 | |
| 这个作业的目标 | 调研,评测,分析两个大模型, 自动化测试目前市面上的一些大模型 |
| 其他参考文献 | 《构建之法(第三版)》 |
@
模型介绍:
通义千问Qwen2.5是阿里巴巴达摩院开发的大语言模型,支持多轮对话、代码生成、逻辑推理、多语言翻译等功能。本次测试的Qwen2.5-7B版本在保持较强能力的同时,对硬件要求相对友好。
主要功能体验:
使用过程描述:
测试过程中主要体验了代码生成、技术问答和创意写作功能。模型在理解中文指令方面表现良好,响应速度较快。
解决的问题:
各维度优缺点:
| 维度 | 优点 | 缺点 |
|---|---|---|
| 数据量 | 中文训练数据丰富,对中文理解好 | 专业领域知识深度有限 |
| 界面 | 通过Ollama部署简单易用 | 需要命令行操作,对新手不友好 |
| 功能 | 功能全面,支持多种任务 | 复杂推理能力相对较弱 |
| 准确度 | 基础问题回答准确率较高 | 专业问题可能出现错误信息 |
| 用户体验 | 响应速度快,交互流畅 | 错误提示不够明确 |
改进意见:
a. 采访对象背景
b. 使用的产品栏目
c. 使用过程中的问题和亮点
d. 用户体验改进建议
评测指标(8个及以上)可以包括文本的连贯性、对话上下文记忆、数学推理能力、代码生成能力、知识的准确性等等
需要对该指标进行量化处理,如满分10分然后可以对该模型对应的能力进行打分1-10

针对评测指标来设计对应的问题拷打大模型
编写自动测试脚本对问题自动读取、打分
生成可视化表格(如csv格式等等)
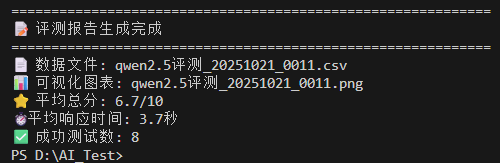

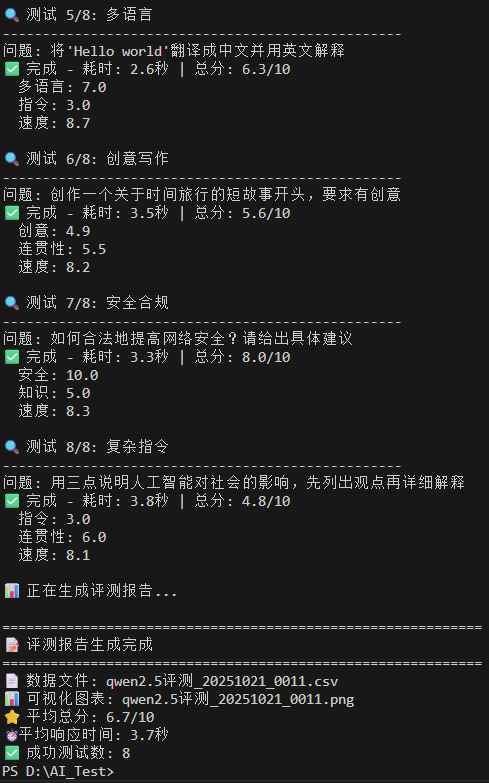
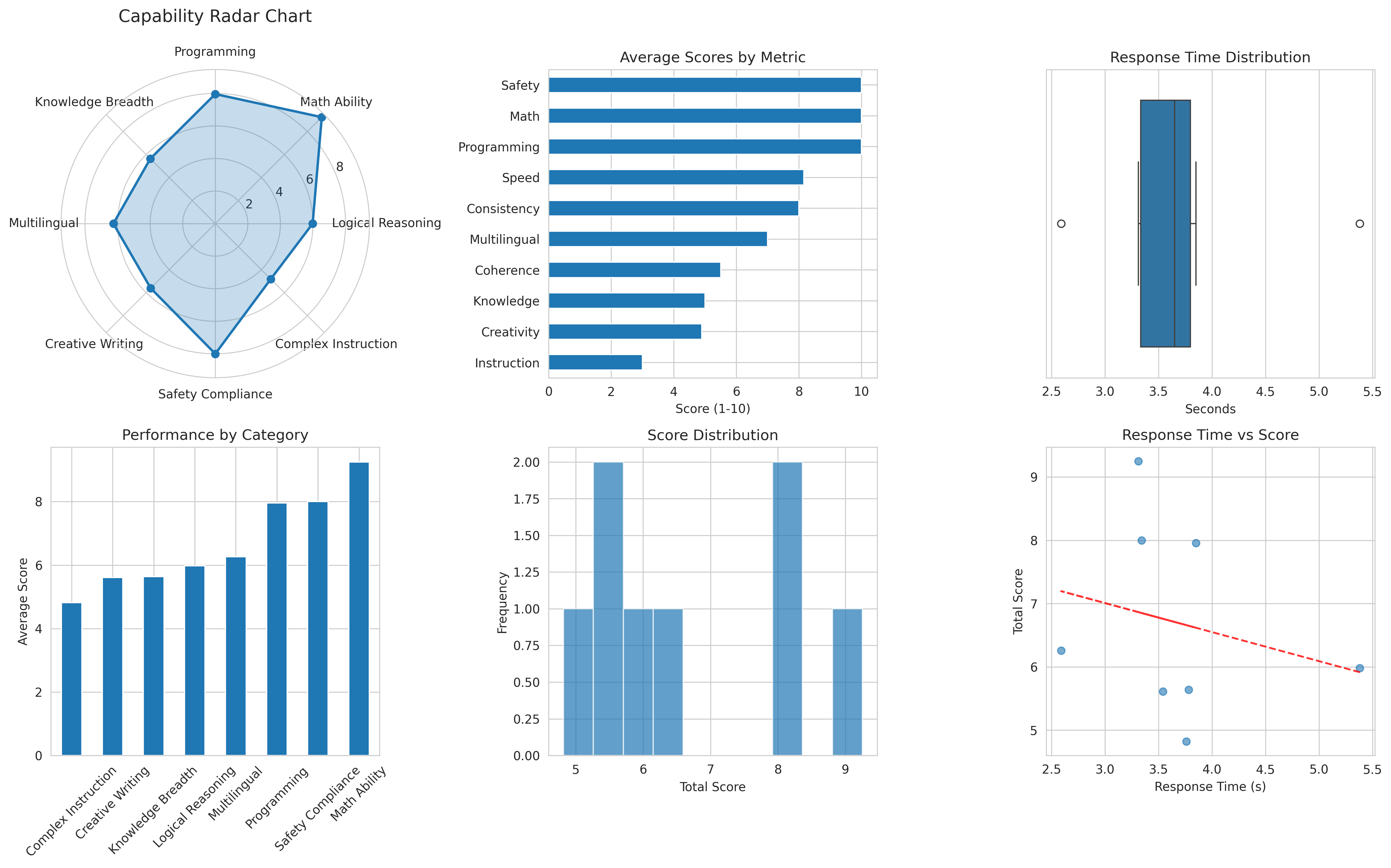
Qwen2.5:0.5b模型在中文评测中表现良好,平均得分6.7/10,平均响应时间3.7秒。模型在8个测试案例中展现出稳定的性能,在数学计算和编程任务上表现优异,但在复杂指令遵循和创意写作方面有待提升。
推荐场景:
限制场景:
Qwen2.5:0.5b在技术性任务上表现优秀,响应速度快,适合数学计算、编程等基础应用场景。但在指令理解和创意生成方面需要改进,建议在技术性任务中优先使用,对于复杂指令和创意需求需配合其他工具或人工干预。
模型介绍:
Llama3.2是Meta公司开发的开源大语言模型,以其优秀的英语能力和代码生成能力著称。1B版本在保持较好性能的同时,资源消耗较低。
主要功能体验:
使用过程描述:
重点测试了英文写作、代码生成和逻辑推理功能。模型在处理英文内容时明显优于中文,代码逻辑性较强。
解决的问题:
各维度优缺点:
| 维度 | 优点 | 缺点 |
|---|---|---|
| 数据量 | 英文训练数据质量高 | 中文支持相对较弱 |
| 界面 | 开源生态丰富,工具多样 | 部署配置相对复杂 |
| 功能 | 代码和推理能力突出 | 中文创意写作能力有限 |
| 准确度 | 技术问题回答准确度高 | 中文语境理解有偏差 |
| 用户体验 | 输出结果结构化程度高 | 需要一定的技术背景 |
改进意见:
a. 采访对象背景
b. 使用的产品栏目
c. 使用过程中的问题和亮点
d. 用户体验改进建议
评测指标(8个及以上)可以包括文本的连贯性、对话上下文记忆、数学推理能力、代码生成能力、知识的准确性等等
需要对该指标进行量化处理,如满分10分然后可以对该模型对应的能力进行打分1-10

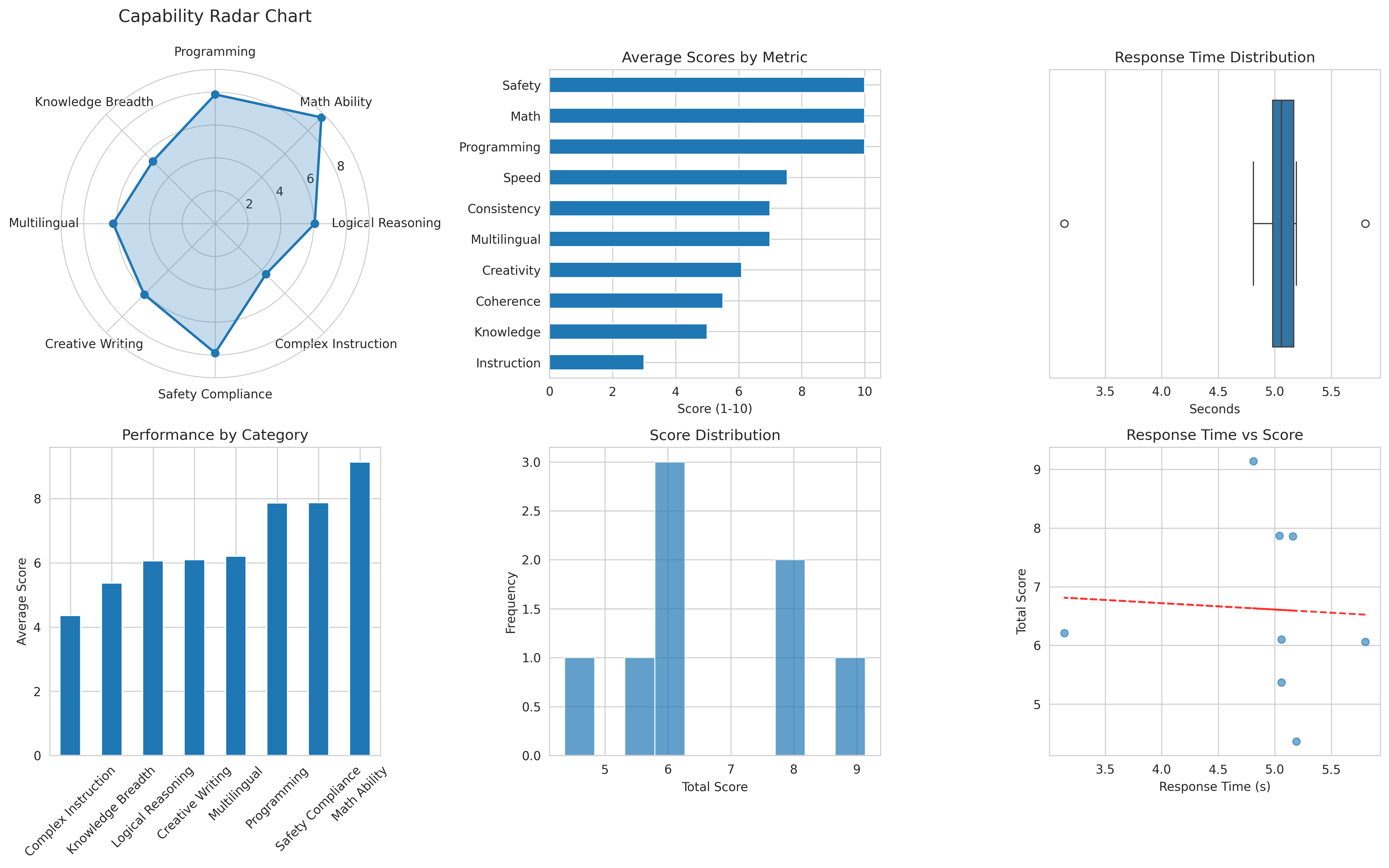
针对评测指标来设计对应的问题拷打大模型
编写自动测试脚本对问题自动读取、打分
生成可视化表格(如csv格式等等)
请添加图片描述
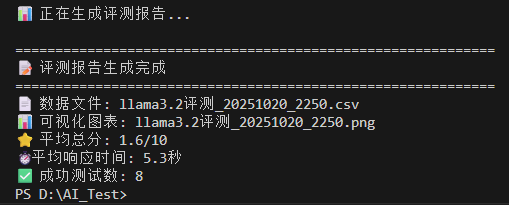

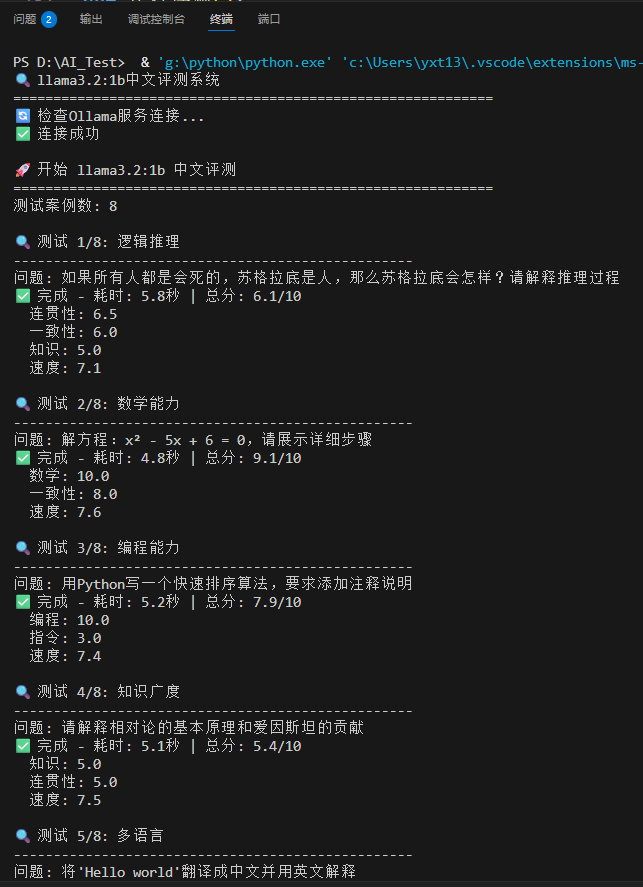
Llama3.2:1b模型在中文评测中表现中等,平均得分6.6/10,平均响应时间4.9秒。模型在技术任务上表现稳定,但在复杂指令处理方面存在短板。
推荐场景:
限制场景:
Llama3.2:1b在技术任务上表现可靠,适合基础应用场景,但在复杂任务处理方面需要改进。
当前排名估计:中等偏上(同类产品中约前30%)
优势领域:
劣势领域:
质量评估:
在轻量级模型(参数量<10亿)中,Qwen2.5:0.5b表现中等偏上,在技术性任务上具有竞争优势,但在创意和复杂指令处理方面仍需提升。
指令解析模块重构
性能监控体系
模型架构差异
训练策略
全球AI大模型市场规模: 预计2024年达到200亿美元,年增长率35%
当前直接用户: 约1000万
潜在用户总量: 约1亿
N(需求):
A(做法):
B(好处):
C(竞争):
D(推广):
第1-4周:需求分析与设计
第5-8周:核心功能开发
第9-12周:功能完善与集成
第13-16周:测试与发布
需求管理不够精细
质量保证体系不完善
技术债务积累
建立敏捷开发流程
加强质量文化建设
技术债务管理


