


545
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享shared_ptr 来展示原子操作的实际应用。
CPU 的运算速度远快于内存的访问速度(内存访问延迟通常是几十纳秒,而 CPU 周期仅零点几纳秒)。为了弥合这一差距,现代 CPU 引入了多级缓存(L1/L2/L3)。CPU 优先从缓存中读取数据,只有当缓存缺失时才访问内存,从而大幅提升性能。
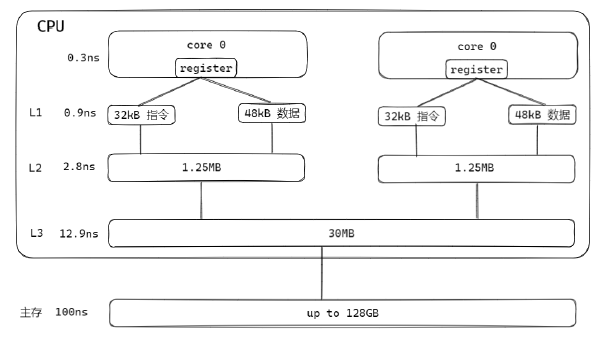
当 CPU 修改缓存中的数据时,并不会立即写回内存,而是采用写回(Write-back)策略:仅当缓存行被替换或显式刷新时才写回内存。这种策略提高了性能,但也带来了缓存不一致问题——多个 CPU 核心各自持有同一内存地址的副本,一个核心的修改可能对其他核心不可见。
为了解决缓存不一致,硬件实现了缓存一致性协议,最常见的是 MESI 协议。每个缓存行被标记为四种状态之一:
总线嗅探机制(Bus Snooping)是 MESI 的核心:每个核心监听总线上的事务,当检测到其他核心读取或写入某个缓存行时,根据当前状态进行响应。例如,当核心 A 修改了一个处于 Shared 状态的缓存行,它会通过总线发出“读并独占”的信号,其他核心的对应缓存行被标记为 Invalid,从而保证数据一致性。这种机制实现了事务串行化,并通过状态机降低了总线带宽的压力。
原子操作(Atomic Operation)是指一个或多个指令的执行过程不可中断,要么全部完成,要么全部不执行,且中间状态对其他线程不可见。常见的原子操作包括读-改-写(RMW)操作,例如 ++、CAS 等。
在多线程环境中,多个线程同时访问同一变量可能导致数据竞争(Data Race)。例如,两个线程同时对 count 执行 count++,在汇编层面可能对应多条指令(读取、加1、写回),线程切换可能破坏操作的完整性,导致最终结果错误。原子操作保证了这些指令作为一个整体执行,避免了数据竞争。
CPU 提供了特定的指令来实现原子性,例如 x86 的 LOCK 前缀可以锁定总线或缓存行,确保多处理器环境中指令的原子执行。现代 CPU 还支持如 cmpxchg(Compare-And-Swap)等原子指令。
CAS(Compare-And-Swap)是一种经典的原子操作,它接受三个参数:内存地址 p、期望值 expected、新值 desired。操作逻辑如下:
if (*p == expected) {
*p = desired;
return true;
} else {
return false;
}
整个过程是原子的,不可被其他线程打断。
C++11 的 <atomic> 库提供了 compare_exchange_weak 和 compare_exchange_strong 方法:
std::atomic<int> value(0);
int expected = 0;
int desired = 1;
bool success = value.compare_exchange_strong(expected, desired);
compare_exchange_strong 保证在 *p == expected 时成功更新,否则返回 false 并将 expected 更新为当前值。compare_exchange_weak 可能因虚假失败而返回 false(某些平台上性能更好),通常用于循环中。ABA 问题是指:线程 1 读取变量值为 A,随后线程 2 将 A 改为 B 又改回 A,此时线程 1 执行 CAS 发现值仍为 A,误认为变量未被修改,从而导致逻辑错误。
常见解决方案:
std::atomic<std::shared_ptr<T>> 或为数据附加一个标记(tag),每次修改递增标记,通过双字 CAS 同时比较值和标记。为了提高性能,编译器和 CPU 可能对指令进行重排(Reordering),只要不改变单线程的语义。但在多线程环境中,重排可能导致其他线程看到“奇怪”的执行顺序,破坏同步逻辑。此外,由于缓存的存在,一个线程的修改何时对其他线程可见也是不确定的。
内存序约束了编译器和 CPU 的重排行为,并规定了多线程间的可见性。它主要解决两个问题:
C++11 定义了六种内存序(std::memory_order),从松到严:
memory_order_relaxed**:只保证原子性,无顺序和可见性保证。用于计数器等不依赖同步的场景。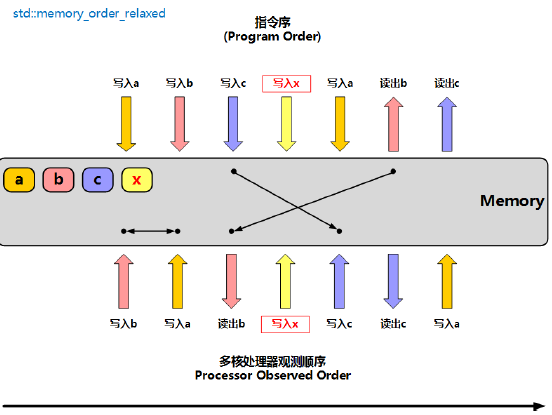
memory_order_consume**(已弃用,不建议使用):针对数据依赖的优化。memory_order_acquire**:用于读操作,保证之后的所有读写操作不会被重排到 acquire 之前,且能看到之前 release 操作写入的数据。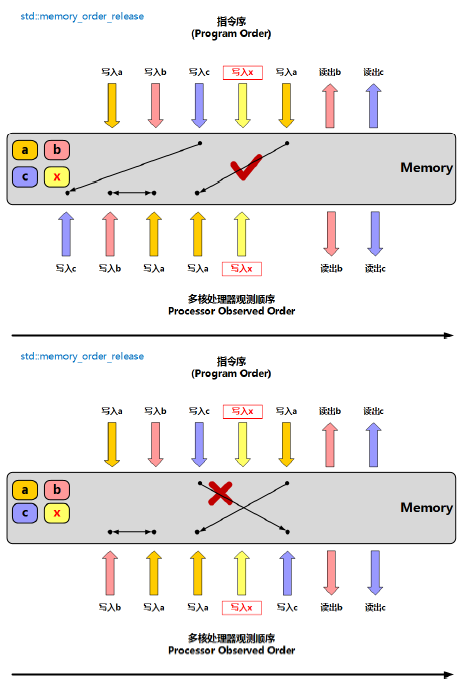
memory_order_release**:用于写操作,保证之前的所有读写操作不会被重排到 release 之后,且对 acquire 操作可见。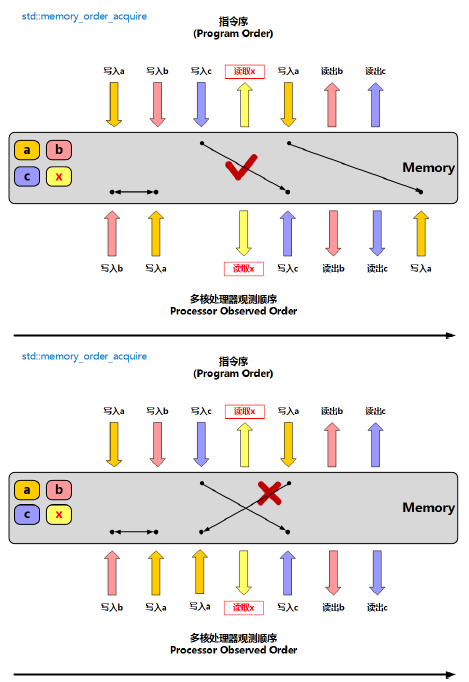
memory_order_acq_rel**:同时具有 acquire 和 release 语义,用于读-改-写操作。memory_order_seq_cst**:最强约束,全局顺序一致,所有线程看到相同的操作顺序,但性能开销最大。典型的使用模式是 Release-Acquire 屏障:一个线程用 release 写入,另一个线程用 acquire 读取,从而建立 happens-before 关系,保证数据同步。
自旋锁是最简单的锁,它通过忙等待(循环检查)实现。使用 CAS 可以轻松实现:
class Spinlock {
std::atomic<bool> flag{false};
public:
void lock() {
while (flag.exchange(true, std::memory_order_acquire)) {
// 自旋等待
}
}
void unlock() {
flag.store(false, std::memory_order_release);
}
};
这里使用 exchange 原子地设置 flag 并返回旧值,若旧值为 true 表示锁已被占用,循环继续。解锁时用 store 释放锁,配合 acquire/release 语义确保同步。
操作系统提供的互斥锁(如 std::mutex)通常比自旋锁更复杂:当锁被占用时,线程会被挂起(阻塞),避免浪费 CPU。其底层实现依赖于系统调用(如 Linux 的 futex)和原子操作。一个简化的 futex 互斥锁可描述为:
state 表示锁状态:0 未锁,1 加锁,2 有等待者。lock():尝试用 CAS 将 0 改为 1,若成功则获得锁;否则原子地增加等待者计数并调用 futex_wait 阻塞。unlock():将状态改回 0,若有等待者则调用 futex_wake 唤醒。虽然实现细节复杂,但其核心仍然是基于原子操作和 CAS。
锁会导致线程阻塞、上下文切换,还可能引发死锁、优先级反转等问题。因此,在高性能场景下,人们倾向于使用无锁数据结构(Lock-Free),它们直接利用原子操作(如 CAS)来避免锁。但无锁编程难度更高,需要仔细处理 ABA 问题和内存序。
1.等待策略:自旋锁用户态忙等待,互斥锁内核态休眠;
2.上下文切换:自选锁无上下文切换,互斥锁有;
3.场景:自旋锁适用于持锁时间短,互斥锁适用于持锁时间长;
shared_ptrstd::shared_ptr 的核心是引用计数,它必须保证多线程环境下计数的增减是安全的。通常,引用计数用 std::atomic<size_t> 实现,并且需要注意内存序的选择。下面我们手写一个简化的 Shared_ptr,并分析其中原子操作的使用。
#pragma once
#include <atomic>
template <typename T>
class Shared_ptr {
public:
Shared_ptr() : ptr_(nullptr), ref_count_(nullptr) {}
explicit Shared_ptr(T *ptr) : ptr_(ptr),
ref_count_(ptr ? new std::atomic<size_t>(1) : nullptr) {}
// 拷贝构造:增加引用计数
Shared_ptr(const Shared_ptr<T>& other)
: ptr_(other.ptr_), ref_count_(other.ref_count_) {
if (ref_count_) {
// 使用 relaxed 即可,因为不需要同步其他内存
ref_count_->fetch_add(1, std::memory_order_relaxed);
}
}
// 拷贝赋值
Shared_ptr<T>& operator=(const Shared_ptr<T>& other) {
if (this != &other) {
release(); // 释放旧资源
ptr_ = other.ptr_;
ref_count_ = other.ref_count_;
if (ref_count_) {
ref_count_->fetch_add(1, std::memory_order_relaxed);
}
}
return *this;
}
// 移动构造:直接转移所有权
Shared_ptr(Shared_ptr<T>&& other) noexcept
: ptr_(other.ptr_), ref_count_(other.ref_count_) {
other.ptr_ = nullptr;
other.ref_count_ = nullptr;
}
// 移动赋值
Shared_ptr<T>& operator=(Shared_ptr<T>&& other) noexcept {
if (this != &other) {
release();
ptr_ = other.ptr_;
ref_count_ = other.ref_count_;
other.ptr_ = nullptr;
other.ref_count_ = nullptr;
}
return *this;
}
~Shared_ptr() { release(); }
T& operator*() const { return *ptr_; }
T* operator->() const { return ptr_; }
T* get() const { return ptr_; }
size_t use_count() const {
return ref_count_ ? ref_count_->load(std::memory_order_acquire) : 0;
}
void reset(T *ptr = nullptr) {
if (ptr != ptr_) {
release();
ptr_ = ptr;
ref_count_ = ptr ? new std::atomic<size_t>(1) : nullptr;
}
}
private:
void release() {
if (ref_count_) {
// 减 1,并检查是否变为 0
if (ref_count_->fetch_sub(1, std::memory_order_acq_rel) == 1) {
delete ptr_;
delete ref_count_;
}
}
}
T *ptr_;
std::atomic<size_t> *ref_count_; // 指向堆上的原子计数器
};
memory_order_relaxed 增加计数。因为只需要保证计数本身原子递增,不涉及其他内存的同步。即使线程 A 在递增后立即释放原指针,由于 ref_count_ 是指向共享内存的指针,其他线程看到的是同一计数器,所以 relaxed 足够安全。release() 函数:使用 fetch_sub(1, memory_order_acq_rel)。为什么需要 acq_rel?fetch_sub 之前的所有操作(如对 ptr_ 的访问)不会被重排到 fetch_sub 之后,确保递减时对象仍然有效。acq_rel 确保了在这之前对 ptr_ 的读写对其他线程(如果有)是可见的,同时后续删除操作不会被提前。relaxed,可能出现:一个线程刚刚把计数减到 0,但另一个线程还没来得及看到新值,就同时尝试减少,导致重复释放。所以必须用更强的内存序保证正确性。use_count() 使用 memory_order_acquire:因为读取计数需要看到其他线程对计数的修改(即前面 release 写的结果)。acquire 确保读取到的是最新值。release() 内部已经处理了内存序。原子操作和内存序是多线程编程的基石,本文从 CPU 缓存架构出发,解释了缓存一致性问题如何催生原子操作,然后深入 CAS 的原理和 ABA 问题的解决,接着讨论了内存序的必要性和 C++ 中的内存序选项,最后通过自旋锁和 shared_ptr 的实现展示了原子操作的实际应用。
https://blog.csdn.net/qq_57951250/article/details/159044302?spm=1011.2124.3001.6209



