



545
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享MessageBuffer 实现。
简单来说,用户态网络缓冲区是在应用程序的地址空间中维护的一块内存区域,用于临时存放待发送或已接收的网络数据。它位于用户态,与内核中的 socket 缓冲区相对应。
在典型的网络编程中,我们直接使用 read/recv 和 write/send 系统调用。这些调用操作的是内核 socket 缓冲区,而用户态缓冲区则作为应用层与内核层之间的第二级缓存,能够有效解决数据边界、流量控制等问题。

TCP 是面向字节流的协议,它只保证字节的顺序,不保护消息边界。当应用层发送多个数据包时,它们可能在接收端被合并成一个大的数据块(粘包),也可能被拆分成多个小块(拆包)。例如,发送方依次调用 send("hello") 和 send("world"),接收方一次 recv 可能读到 "helloworld",也可能只读到 "hel" 和 "loworld"。
用户态接收缓冲区可以暂存所有到达的数据,直到应用层能够从缓冲区中解析出一个完整的消息,从而解决粘包/拆包问题。
当数据到达的速度超过应用程序处理的速度时,内核 socket 接收缓冲区可能会被填满。如果继续让数据堆积在内核,会导致对方 TCP 窗口关闭,甚至丢包重传。用户态接收缓冲区可以作为更大的缓存,吸收瞬时的流量高峰,给应用层更多的时间处理数据。
TCP 发送数据时,受限于 TCP 窗口大小、拥塞控制等因素,一次 send 调用可能无法将全部数据发出。例如,应用层想发送 1MB 数据,但内核 socket 发送缓冲区只有 256KB 空闲,那么 send 可能只发送了 256KB(在非阻塞模式下返回部分发送字节数,或阻塞直到有空间)。用户态发送缓冲区可以暂存未发送完的数据,等待 socket 可写时继续发送。
当应用层产生数据的速度快于网络发送的速度(例如网卡带宽限制、对方接收窗口较小),用户态发送缓冲区可以暂存数据,避免应用层阻塞或丢失数据。
用户态网络缓冲区主要解决了 数据边界识别 和 流量平滑 两个问题。它的设计通常包含以下关键点:
TCP 粘包无法避免,但应用层可以通过协议设计来界定消息边界。常见方法有:
例如 HTTP 协议使用 \r\n\r\n 分隔头部,或者使用自定义的结束符(如 \n)。接收方不断从缓冲区中查找分隔符,找到一个完整的消息就取出处理。
在每个消息前面加上固定长度的字段(例如 2 字节或 4 字节),表示消息体的长度。接收方先读取长度字段,再根据长度读取相应字节的消息体。这是最常用的方法,效率高且简单。
了解内核如何处理网络包,有助于我们设计更高效的用户态缓冲区。

ksoftirqd 处理软中断。它从 Ring Buffer 中取出数据帧,封装成 sk_buff(Socket Buffer)结构,并交给协议栈。epoll_wait),内核会唤醒它。应用通过 read/recv 系统调用将数据从内核 socket 缓冲区拷贝到用户态缓冲区。send/write,将用户数据拷贝到内核分配的 sk_buff 中,并放入 socket 的发送队列。sk_buff,将其映射到 Ring Buffer 的 DMA 区域,然后通知网卡发送。sk_buff(对于 TCP,会保留一份副本用于重传,直到收到 ACK 才释放)。sk_buff(重传副本)。下面是一个基于 std::vector<uint8_t> 实现的用户态缓冲区类 MessageBuffer,它结合了定长缓冲区和环形缓冲区的优点,并支持动态扩容。代码中使用了 readv 系统调用来高效地从 socket 接收数据,避免额外的数据拷贝。
#pragma once
#include <cstddef>
#include <vector>
#include <cstdint>
#include <cstring>
#include <errno.h>
#include <sys/uio.h>
class MessageBuffer {
public:
MessageBuffer() : read_pos_(0), write_pos_(0) {
buffer_.resize(4096); // 默认初始大小为 4096 字节
}
explicit MessageBuffer(std::size_t initial_size) : read_pos_(0), write_pos_(0) {
buffer_.resize(initial_size);
}
// 禁止拷贝构造和赋值,允许移动
MessageBuffer(const MessageBuffer&) = delete;
MessageBuffer& operator=(const MessageBuffer&) = delete;
MessageBuffer(MessageBuffer&& other) noexcept {
buffer_ = std::move(other.buffer_);
read_pos_ = other.read_pos_;
write_pos_ = other.write_pos_;
other.read_pos_ = 0;
other.write_pos_ = 0;
}
MessageBuffer& operator=(MessageBuffer&& other) noexcept {
if (this != &other) {
buffer_ = std::move(other.buffer_);
read_pos_ = other.read_pos_;
write_pos_ = other.write_pos_;
other.read_pos_ = 0;
other.write_pos_ = 0;
}
return *this;
}
uint8_t* GetBasePointer() { return buffer_.data(); }
uint8_t* GetReadPointer() { return buffer_.data() + read_pos_; }
uint8_t* GetWritePointer() { return buffer_.data() + write_pos_; }
void ReadComplete(std::size_t n) { read_pos_ += n; }
void WriteComplete(std::size_t n) { write_pos_ += n; }
std::size_t GetActiveSize() const { return write_pos_ - read_pos_; }
std::size_t GetFreeSize() const { return buffer_.size() - write_pos_; }
std::size_t GetTotalSize() const { return buffer_.size(); }
// 将有效数据移到缓冲区头部,释放尾部空间
void Normalize() {
if (read_pos_ > 0) {
std::size_t active_size = GetActiveSize();
if (active_size > 0) {
std::memmove(buffer_.data(), buffer_.data() + read_pos_, active_size);
}
read_pos_ = 0;
write_pos_ = active_size;
}
}
// 确保至少有 n 字节可用空间
void EnsureFreeSpace(std::size_t n) {
// 如果总空闲空间(总大小 - 有效数据)小于 n,则扩容
if (GetTotalSize() - GetActiveSize() < n) {
Normalize(); // 先归一化,减少扩容量
buffer_.resize(GetTotalSize() + std::max(n, buffer_.size() / 2));
} else if (GetFreeSize() < n) {
// 总空间足够,但尾部空间不足,执行归一化
Normalize();
}
}
// 写入数据
void Write(const uint8_t* data, std::size_t n) {
EnsureFreeSpace(n);
std::memcpy(GetWritePointer(), data, n);
WriteComplete(n);
}
// 从 socket 接收数据,利用 readv 分散读,避免数据拷贝
int Recv(int fd, int *err) {
char extra[65535]; // 用于接收超过当前缓冲区尾部长度的数据(例如 UDP 最大报文)
struct iovec vec[2];
vec[0].iov_base = GetWritePointer();
vec[0].iov_len = GetFreeSize();
vec[1].iov_base = extra;
vec[1].iov_len = sizeof(extra);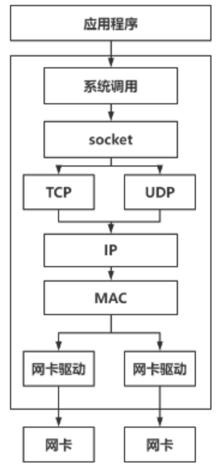
int n = readv(fd, vec, 2);
if (n < 0) {
*err = errno;
return -1;
}
if (n == 0) {
*err = ECONNRESET; // 对端关闭连接
return 0;
}
std::size_t written = static_cast<std::size_t>(n);
if (written <= GetFreeSize()) {
WriteComplete(written);
return written;
} else {
// 数据超过当前缓冲区尾部剩余空间,先填满尾部,剩余部分存入 extra
std::size_t extra_size = written - GetFreeSize();
WriteComplete(GetFreeSize()); // 写满原缓冲区尾部
Write(reinterpret_cast<uint8_t*>(extra), extra_size); // 将 extra 中的数据写入(可能触发扩容)
return written;
}
}
private:
std::vector<uint8_t> buffer_;
std::size_t read_pos_;
std::size_t write_pos_;
};
EnsureFreeSpace 在空间不足时,先归一化,再按需扩容(增加 max(n, 当前大小/2)),避免频繁小量扩容。Recv 使用 readv 将数据读到两个缓冲区:首先是当前缓冲区的空闲尾部,如果一次读入的数据超过尾部空闲,多余部分暂存到栈上的 extra 数组,然后再通过 Write 写入缓冲区(可能触发扩容)。这避免了动态分配临时缓冲区的开销,也避免了数据丢失。MessageBuffer 放入容器(如每个连接一个 buffer)时减少拷贝。用户态网络缓冲区是高性能网络编程中不可或缺的组件。它填补了内核 socket 缓冲区与应用层之间的空白,解决了粘包和速度不匹配的问题。通过理解 Linux 内核的数据包收发流程,我们可以更精准地设计缓冲区的大小和操作方式。本文给出的 MessageBuffer 实现简洁高效,适合集成到网络库中。
https://blog.csdn.net/qq_57951250/article/details/159047501?spm=1011.2124.3001.6209



