27,580
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

- ALTER PROC [dbo].[Insert]
- @Tid Int
- AS
- BEGIN
-
- IF NOT EXISTS(SELECT 1 FROM Table WHERE TId = @Tid)
- BEGIN
- INSERT INTO Table (INSERTDATE,TID ) VALUES (GETDATE(), @Tid);
- END
- END
- if exists(select 1 from sys.objects where type='U' and name ='testlock1')
- drop table testlock1
- --建表
- create table testlock1
- (
- id int,
- Createdate datetime,
- )
- --建立索引
- create index index_1 on testlock1(id)
- --建立存储过程插入数据
- create proc ups_TestLock
- @i int
- as
- begin
- begin try
- begin tran
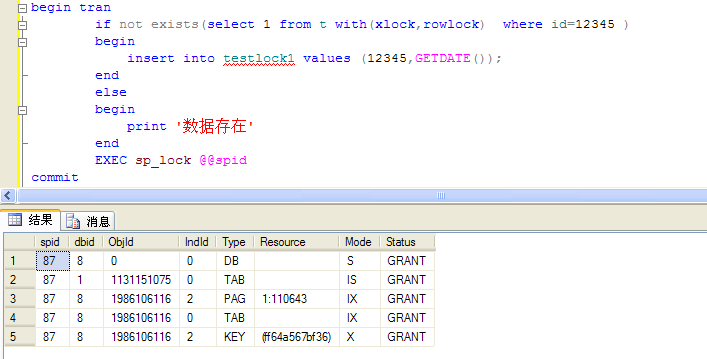
- if not exists(select 1 from t where id=@i )
- begin
- insert into testlock1 values (@i,GETDATE());
- end
- commit
- end try
- begin catch
- rollback
- end catch
- end
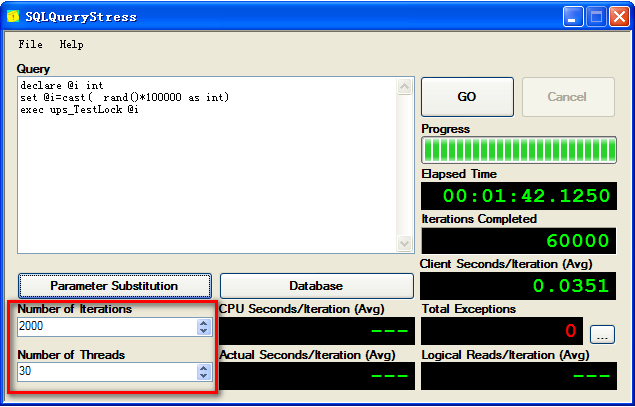
- declare @i int
- set @i=cast( rand()*100000 as int)--生成一个100000以内的随机数
- exec test_p @i
- alter proc ups_TestLock
- @i int
- as
- begin
- begin try
- begin tran
- if not exists(select 1 from t with(xlock,rowlock) where id=@i )--注意这里加上<span style="font-family: Arial, Helvetica, sans-serif;">xlock,rowlock,行级排它锁</span>
- begin
- insert into testlock1 values (@i,GETDATE());
- end
- commit
- end try
- begin catch
- rollback
- end catch
- end
- drop index index_1 on testlock1
- create unique index index_1 on testlock1(id)
- if exists(select 1 from sys.objects where type='U' and name ='testlock1')
- drop table testlock1
- --建表
- create table testlock1
- (
- id int,
- Createdate datetime,
- SessionID varchar(50)
- )
- --建立索引
- create index index_1 on testlock1(id)
- alter proc ups_TestLock
- @i int
- as
- begin
- begin try
- begin tran
- if not exists(select 1 from testlock1 with(xlock,rowlock) where id=@i )
- begin
- insert into testlock1 values (@i,GETDATE(),@@spid);--这里插入一列回话ID
- end
- commit
- end try
- begin catch
- rollback
- end catch
- end
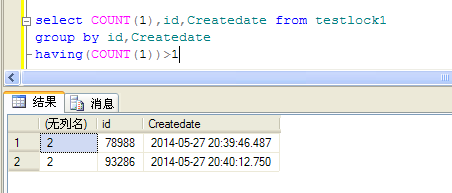
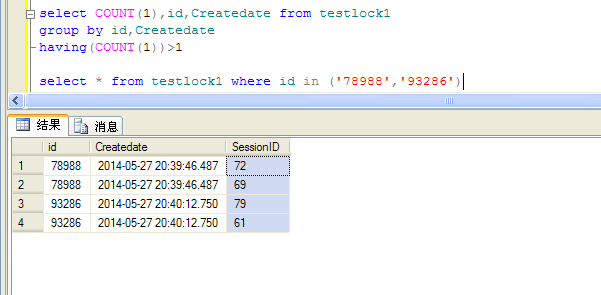
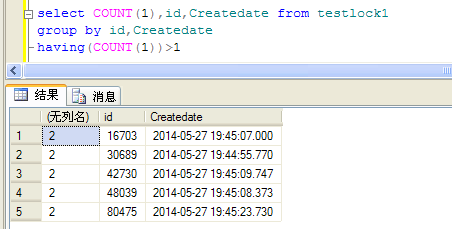
- select COUNT(1),id,Createdate from testlock1
- group by id,Createdate
- having(COUNT(1))>1