



70,026
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


void
2914__libc_free (void *mem)
2915{
2916 mstate ar_ptr;
2917 mchunkptr p; /* chunk corresponding to mem */
2918
2919 void (*hook) (void *, const void *)
2920 = atomic_forced_read (__free_hook);
2921 if (__builtin_expect (hook != NULL, 0))
2922 {
2923 (*hook)(mem, RETURN_ADDRESS (0));
2924 return;
2925 }
2926
2927 if (mem == 0) /* free(0) has no effect */
2928 return;
2929
2930 p = mem2chunk (mem);
2931
2932 if (chunk_is_mmapped (p)) /* release mmapped memory. */
2933 {
2934 /* see if the dynamic brk/mmap threshold needs adjusting */
2935 if (!mp_.no_dyn_threshold
2936 && p->size > mp_.mmap_threshold
2937 && p->size <= DEFAULT_MMAP_THRESHOLD_MAX)
2938 {
2939 mp_.mmap_threshold = chunksize (p);
2940 mp_.trim_threshold = 2 * mp_.mmap_threshold;
2941 LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2,
2942 mp_.mmap_threshold, mp_.trim_threshold);
2943 }
2944 munmap_chunk (p);
2945 return;
2946 }
2947
2948 ar_ptr = arena_for_chunk (p);
2949 _int_free (ar_ptr, p, 0);
2950}
#define mem2chunk(mem) ((mchunkptr)((char*)(mem) - 2*SIZE_SZ))
ar_ptr = (((p)-> size & 0x4) ?
((heap_info *) ((unsigned long) (p) & ~((10 * 10) - 1)))->ar_ptr : &main_arena);
#define PREV_INUSE 0x1
#define IS_MMAPPED 0x2
#define NON_MAIN_ARENA 0x4
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
#define chunksize(p) ((p)->size & ~(SIZE_BITS))
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
struct malloc_chunk {
size_t prev_size;
size_t size;
struct malloc_chunk *fd;
struct malloc_chunk *bk;
struct malloc_chunk *fd_nextsize;
struct malloc_chunk *bk_nextsize;
};
typedef struct malloc_chunk *mchunkptr;
int main(int argc, char *argv[])
{
void *mem;
mchunkptr p;
int ret;
int i;
for(i = 0; i < 10; ++i) {
mem = malloc(ret = rand() % 1024);
p = ((mchunkptr) ((char *) (mem) - 2 * (sizeof(size_t))));
printf("malloc size : %d; chunk size : %d\n", ret, p->size & ~0x7);
free(mem);
}
exit(0);
}


44* Why use this malloc?
45
46 This is not the fastest, most space-conserving, most portable, or
47 most tunable malloc ever written. However it is among the fastest
48 while also being among the most space-conserving, portable and tunable.
49 Consistent balance across these factors results in a good general-purpose
50 allocator for malloc-intensive programs.
51
52 The main properties of the algorithms are:
53 * For large (>= 512 bytes) requests, it is a pure best-fit allocator,
54 with ties normally decided via FIFO (i.e. least recently used).
55 * For small (<= 64 bytes by default) requests, it is a caching
56 allocator, that maintains pools of quickly recycled chunks.
57 * In between, and for combinations of large and small requests, it does
58 the best it can trying to meet both goals at once.
59 * For very large requests (>= 128KB by default), it relies on system
60 memory mapping facilities, if supported.
2878void *
2879__libc_malloc (size_t bytes)
2880{
2881 mstate ar_ptr;
2882 void *victim;
2883
2884 void *(*hook) (size_t, const void *)
2885 = atomic_forced_read (__malloc_hook);
2886 if (__builtin_expect (hook != NULL, 0))
2887 return (*hook)(bytes, RETURN_ADDRESS (0));
2888
2889 arena_get (ar_ptr, bytes);
2890
2891 if (!ar_ptr)
2892 return 0;
2893
2894 victim = _int_malloc (ar_ptr, bytes);
2895 if (!victim)
2896 {
2897 LIBC_PROBE (memory_malloc_retry, 1, bytes);
2898 ar_ptr = arena_get_retry (ar_ptr, bytes);
2899 if (__builtin_expect (ar_ptr != NULL, 1))
2900 {
2901 victim = _int_malloc (ar_ptr, bytes);
2902 (void) mutex_unlock (&ar_ptr->mutex);
2903 }
2904 }
2905 else
2906 (void) mutex_unlock (&ar_ptr->mutex);
2907 assert (!victim || chunk_is_mmapped (mem2chunk (victim)) ||
2908 ar_ptr == arena_for_chunk (mem2chunk (victim)));
2909 return victim;
2910}
2911libc_hidden_def (__libc_malloc)
void *p = chunk2mem (victim);
alloc_perturb (p, bytes);
return p;
#define chunk2mem(p) ((void*)((char*)(p) + 2*SIZE_SZ))
struct malloc_chunk {
1112
1113 INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
1114 INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
1115
1116 struct malloc_chunk* fd; /* double links -- used only if free. */
1117 struct malloc_chunk* bk;
1118
1119 /* Only used for large blocks: pointer to next larger size. */
1120 struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
1121 struct malloc_chunk* bk_nextsize;
1122};
/*
1126 malloc_chunk details:
1127
1128 (The following includes lightly edited explanations by Colin Plumb.)
1129
1130 Chunks of memory are maintained using a `boundary tag' method as
1131 described in e.g., Knuth or Standish. (See the paper by Paul
1132 Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a
1133 survey of such techniques.) Sizes of free chunks are stored both
1134 in the front of each chunk and at the end. This makes
1135 consolidating fragmented chunks into bigger chunks very fast. The
1136 size fields also hold bits representing whether chunks are free or
1137 in use.
1138
1139 An allocated chunk looks like this:
1140
1141
1142 chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1143 | Size of previous chunk, if allocated | |
1144 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1145 | Size of chunk, in bytes |M|P|
1146 mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1147 | User data starts here... .
1148 . .
1149 . (malloc_usable_size() bytes) .
1150 . |
1151nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1152 | Size of chunk |
1153 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1154
1155
1156 Where "chunk" is the front of the chunk for the purpose of most of
1157 the malloc code, but "mem" is the pointer that is returned to the
1158 user. "Nextchunk" is the beginning of the next contiguous chunk.
1159
1160 Chunks always begin on even word boundaries, so the mem portion
1161 (which is returned to the user) is also on an even word boundary, and
1162 thus at least double-word aligned.
1163
1164 Free chunks are stored in circular doubly-linked lists, and look like this:
1165
1166 chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1167 | Size of previous chunk |
1168 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1169 `head:' | Size of chunk, in bytes |P|
1170 mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1171 | Forward pointer to next chunk in list |
1172 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1173 | Back pointer to previous chunk in list |
1174 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1175 | Unused space (may be 0 bytes long) .
1176 . .
1177 . |
1178nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1179 `foot:' | Size of chunk, in bytes |
1180 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
1181
1182 The P (PREV_INUSE) bit, stored in the unused low-order bit of the
1183 chunk size (which is always a multiple of two words), is an in-use
1184 bit for the *previous* chunk. If that bit is *clear*, then the
1185 word before the current chunk size contains the previous chunk
1186 size, and can be used to find the front of the previous chunk.
1187 The very first chunk allocated always has this bit set,
1188 preventing access to non-existent (or non-owned) memory. If
1189 prev_inuse is set for any given chunk, then you CANNOT determine
1190 the size of the previous chunk, and might even get a memory
1191 addressing fault when trying to do so.
1192
1193 Note that the `foot' of the current chunk is actually represented
1194 as the prev_size of the NEXT chunk. This makes it easier to
1195 deal with alignments etc but can be very confusing when trying
1196 to extend or adapt this code.
1197
1198 The two exceptions to all this are
1199
1200 1. The special chunk `top' doesn't bother using the
1201 trailing size field since there is no next contiguous chunk
1202 that would have to index off it. After initialization, `top'
1203 is forced to always exist. If it would become less than
1204 MINSIZE bytes long, it is replenished.
1205
1206 2. Chunks allocated via mmap, which have the second-lowest-order
1207 bit M (IS_MMAPPED) set in their size fields. Because they are
1208 allocated one-by-one, each must contain its own trailing size field.
1209
1210*/
1211




typedef struct
{
unsigned int size; // 申请到的内存大小
unsigned int flag; // 若为1表示申请状态
unsigned int totoal; // 当前申请的总数,不一定是用户申请的,可能还包含系统申请的部分
unsigned int reserved; // 未知
}_mem_control_block;
unsigned char *ptr;
unsigned char *p;
int size;
int i;
_mem_control_block *memctrl;
while(1)
{
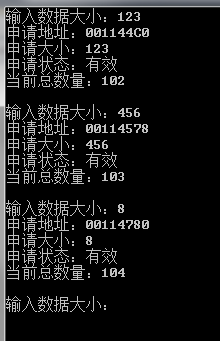
printf("输入数据大小:");
scanf("%d", &size);
ptr = new unsigned char[size];
p = ptr;
/*for(i = 0; i <= 16; i++)
{
printf("Address %p value:0x%X(%d)\r\n", p, *p, *p);
p --;
}
delete(ptr);
*/
//delete(ptr); 测试
memctrl = (_mem_control_block *)(p - sizeof(_mem_control_block));
printf("申请地址:%p\r\n", p);
printf("申请大小:%d\r\n", memctrl->size);
printf("申请状态:%s\r\n", memctrl->flag == 1? "有效":"无效");
printf("当前总数量:%d\r\n",memctrl->totoal);
printf("\r\n");
}
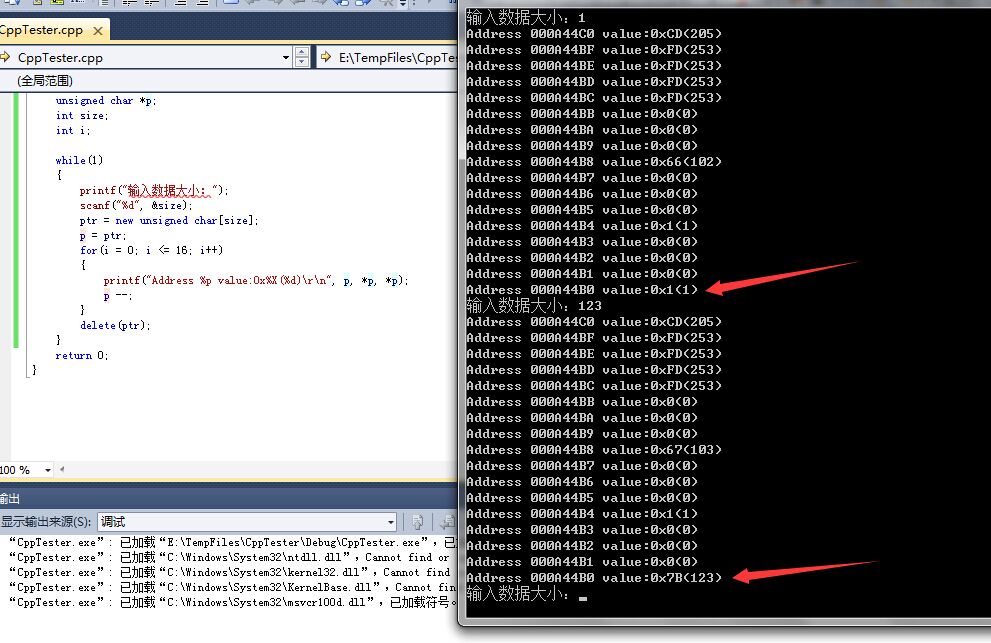
printf("输入数据大小:");
scanf("%d", &size);
ptr = new unsigned char[size];
p = ptr;
for(i = 0; i <= 16; i++)
{
printf("Address %p value:0x%X(%d)\r\n", p, *p, *p);
p --;
}
delete(ptr);




extern "C" _CRTIMP size_t __cdecl _msize_dbg (
void * pUserData,
int nBlockUse
)
{
size_t nSize;
_CrtMemBlockHeader * pHead;
/* validation section */
_VALIDATE_RETURN(pUserData != NULL, EINVAL, -1);
/* verify heap before getting size */
if (check_frequency > 0)
if (check_counter == (check_frequency - 1))
{
_ASSERTE(_CrtCheckMemory());
check_counter = 0;
}
else
check_counter++;
_mlock(_HEAP_LOCK); /* block other threads */
__try {
/*
* If this ASSERT fails, a bad pointer has been passed in. It may be
* totally bogus, or it may have been allocated from another heap.
* The pointer MUST come from the 'local' heap.
*/
_ASSERTE(_CrtIsValidHeapPointer(pUserData));
/* get a pointer to memory block header */
pHead = pHdr(pUserData);
/* verify block type */
_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));
/* CRT blocks can be treated as NORMAL blocks */
if (pHead->nBlockUse == _CRT_BLOCK && nBlockUse == _NORMAL_BLOCK)
nBlockUse = _CRT_BLOCK;
/* The following assertion was prone to false positives - JWM */
/* if (pHead->nBlockUse != _IGNORE_BLOCK) */
/* _ASSERTE(pHead->nBlockUse == nBlockUse); */
nSize = pHead->nDataSize;
}
__finally {
_munlock(_HEAP_LOCK); /* release other threads */
}
return nSize;
}

