云计算(Cloud Computing)是一种基于互联网的计算方式,通过这种方式,共享的软硬 件资源和信息可以按需提供给计算机和其他设备。云其实是网络、互联网的一种比喻说 法。云计算有狭义云计算和广义云计算两种概念:
---
狭义云计算 指IT基础设施的交付和使用模式,指通过网络以按需、易扩展的方式获得所需资源。
---
广义云计算 指服务的交付和使用模式,指通过网络以按需、易扩展的方式获得所需服务。这种 服务可以是IT、软件、互联网相关,也可是其他服务。
下图-云计算示意图:
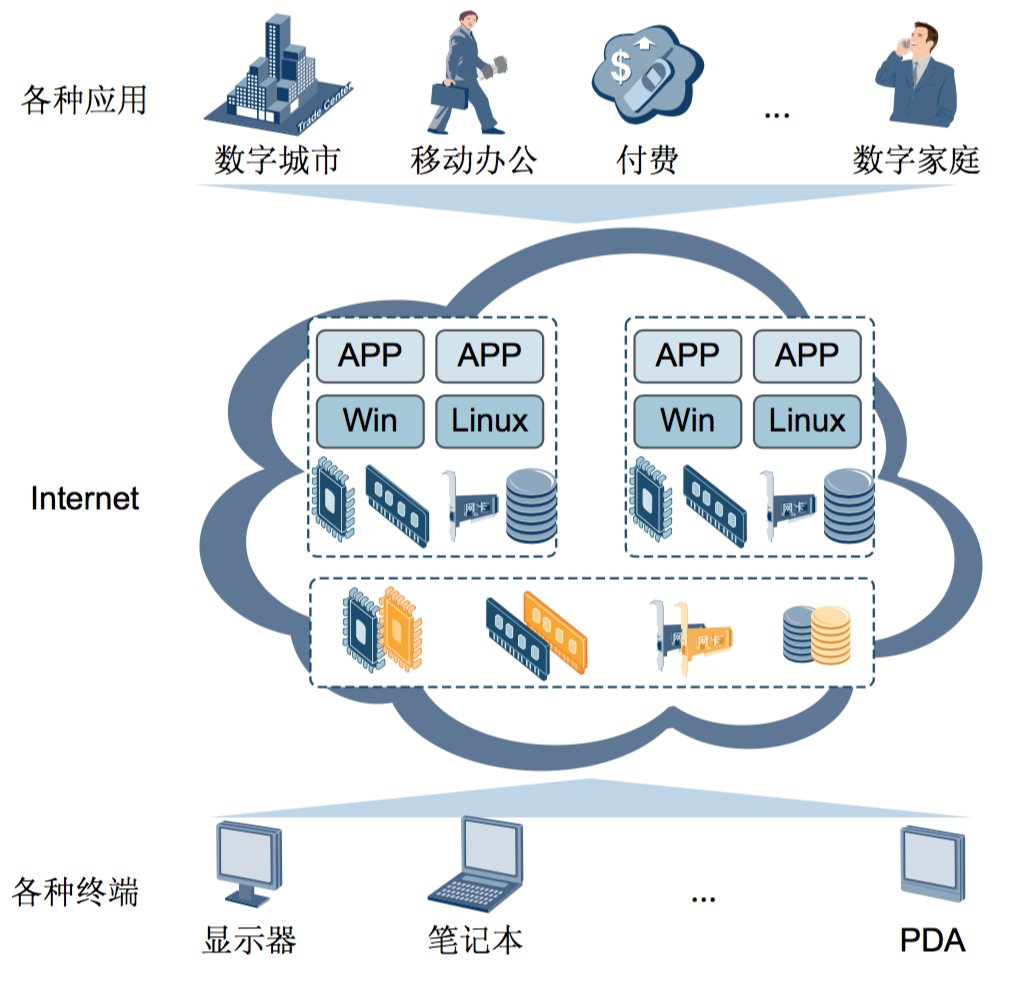
云计算的核心思想是通过统一管理和调度计算资源池中的资源,向用户提供服务。计算 资源池由大量用网络连接的计算资源构成。提供资源的网络被称为云。云中的资源在使 用者看来是可以无限、随时扩展的,并且可以随时获取,按需使用,按使用付费。
云分类
目前看来,云主要有以下几种分类。随着云计算的不断发展,可能会产生更多种类的
云。
l 公有云
公有云通常指第三方提供商为用户提供的能够使用的云。公有云一般可通过Internet 使用,可能是免费或成本低廉的。这种云有许多实例,可在当今整个开放的公有网 络中提供服务。
l 私有云
私有云为一个企业单独使用而构建,提供对数据、安全性和服务质量的最有效控 制。私有云可由企业的IT部门或云平台业务提供商搭建。企业可以在搭建的云平台 基础上部署自己的网络或应用服务。私有云可部署在企业的数据中心中,也可统一 部署在云平台业务提供商的机房。
l 混合云
混合云是公有云和私有云两种服务方式的结合。由于安全和控制原因,并非所有的 企业信息都能放置在公有云上,因此大部分已经应用云计算的企业将会使用混合云 模式。混合云为其他目的的弹性需求提供了很好的基础。比如私有云可以把公有云 作为灾难转移的平台,在需要的时候使用它。
l 移动云
移动云把虚拟化技术应用于手机和平板电脑。适用于移动3G设备终端(手机或平板电脑)使用企业应用系统资源,它是云计算移动虚拟化中非常重要的一部分。
l 行业云
行业云是一种云平台。它由行业内或某个区域内起主导作用或者掌握关键资源的组 织建立和维护,以公开或者半公开的方式向行业内部或相关组织和公众提供有偿或 无偿服务。
行业云又可以分为金融云、政府云、教育云、电信云、医疗云、工业云、云制造等。
服务模式
云计算包括三个层次的服务:
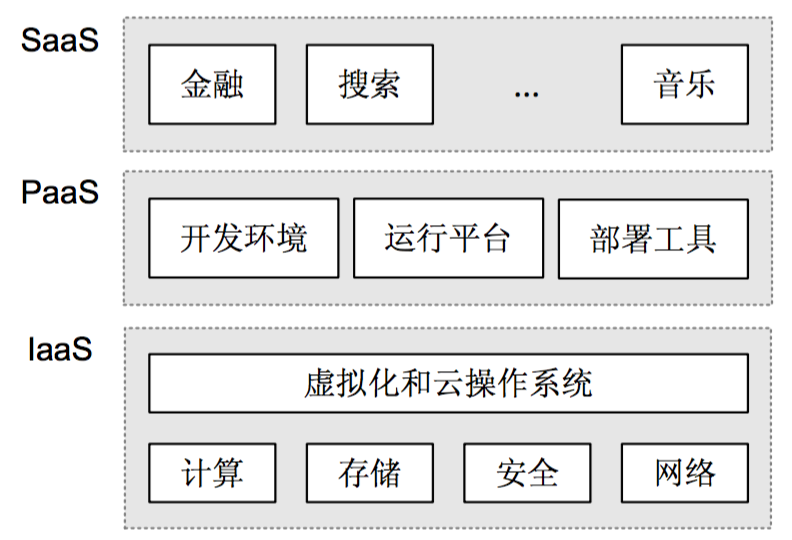
各服务模式之间没有必然联系,也不相互依赖。各服务模式的简单说明如下:
l 基础设施即服务IaaS(Infrastructure as a Service)
提供给客户的服务是对所有设施的利用,包括处理、存储、网络和其他基本的计算 资源。客户能够部署和运行任意软件,包括操作系统和应用程序。客户不管理或控 制任何云计算基础设施,但能控制操作系统的选择、储存空间、部署的应用,也有 可能获得有限制的网络组件(例如防火墙、负载均衡器等)的控制。
l 平台即服务PaaS(Platform as a Service)
提供给客户的服务是把客户开发或收购的应用程序部署到供应商的云计算基础设施 上。客户不需要管理或控制底层的云基础设施,包括网络、服务器、操作系统、存 储等,但客户能控制部署的应用程序,也可能控制运行应用程序的托管环境配置。
l 软件即服务SaaS(Software as a Service)
提供给客户的服务是运营商运行在云计算基础设施上的应用程序,用户可以在各种设备上通过瘦客户端界面访问。客户不需要管理或控制任何云计算基础设施。
应用
云计算技术的应用领域日趋广泛。云计算广泛应用于通信、娱乐、社保、医疗、科研、
教育、就业、安全等领域。
较为常见的云计算应用类型包括:
l 软件应用:通过Web浏览器向用户提供单一的软件应用。用户不需要事先购买服务 器设备或是软件授权。厂商仅提供应用,其成本与常规的软件服务模式相比,要低 得多。
l 公用/效用计算:为客户提供所需的存储资源和虚拟化服务器等应用。帮助企业用 户创建虚拟的数据中心,或帮助企业将内存、I/0、存储和计算容量通过网络集成为 虚拟资源池来使用。通过这些手段,根据客户的需求及时产生适当的资源,并进行 基础设施管理以及根据某个应用进行收费。
l WEB服务:WEB服务厂商通过提供API(Application Programming Interface)来让 开发人员开发Internet应用,而不是自己提供功能全面的应用软件。
l 平台应用:将开发环境作为服务来提供给用户。用户可以在供应商的基础架构上创 建和运行自己的应用软件,并通过网络直接从供应商的服务器上传递给其他用户。
l 管理服务:提供给IT管理人员使用,用于其管理IT应用的服务,如电子邮件的病毒扫描服务、应用软件监控服务等。
l 服务商业平台:提供交互性服务平台,使客户可以通过自主设定来获得特定的服务,常用于商业贸易领域。
l 云计算集成:将不同的云计算服务整合后再提供给用户。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


 整个IT界是时候考虑引入遗忘功能了。
整个IT界是时候考虑引入遗忘功能了。



