在使用scala编写spark程序时,用到avro格式数据,其中数据的类型用GenericRecord,在转化为RDD时,我想将GenericRecord做为元素存入列表,然后转化为RDD,结果在跑的时候报错,说GenericRecord没有序列化,希望各位能共同探讨下。
代码:
object sparktest {
//初始化Spark配置及上下文
val conf = new SparkConf().setAppName("local").setAppName("My App")
val sc = new SparkContext(conf)
//转化最后结果的输出结果格式,方便之后操作
//传入的参数是二元组,第一个元素是String类型,第二个元素为Int类型,配合处理结果,返回类型为String
def trans(line:Tuple2[String,Int]):String = {
//处理结果返回结构为 www.baidu.com 5
return line._1 + "\t" + line._2
}
def main(args:Array[String]): Unit ={
var beg = System.currentTimeMillis()
//创建数据读取,因为模式中的type为record,所以用GenericDatumReader,并指定数据类型为GenericRecord
val datumReader = new GenericDatumReader[GenericRecord]()
//创建文件读取,指定数据类型为GenericRecord,并指定文件路径,传入数据读取
val reader = new DataFileReader[GenericRecord](new File(args(0)),datumReader)
//定义记录变量,类型为GenericRecord
var dns = null:GenericRecord
//定义需要处理部分,类型为AnyRef,因为用从记录变量中取得待处理部分的类型为AnyRef,否则无法承接
var line=null:AnyRef
//定义ArrayBuffer,主要需要其append函数,并且其可以转化为RDD
val a = new ListBuffer[GenericRecord]()
//遍历读取数据,取出需要部分,动态添加到Buffer中
while(reader.hasNext){
dns = reader.next(dns)
a.append(dns)
}
//将ArrayBuffer转化为RDD,可以将其转化为任意集合类型再转化为RDD,也可以直接转化为RDD
val rdd = sc.parallelize(a)
//简单处理
val r1 = rdd.map(line => (line.get(args(1)).toString().split("\\|")(1),1)).reduceByKey((x,y) => (x+y)).map(line => trans(line))
//保存文件
r1.saveAsTextFile(args(2))
println((System.currentTimeMillis() - beg)/1000)
}
}
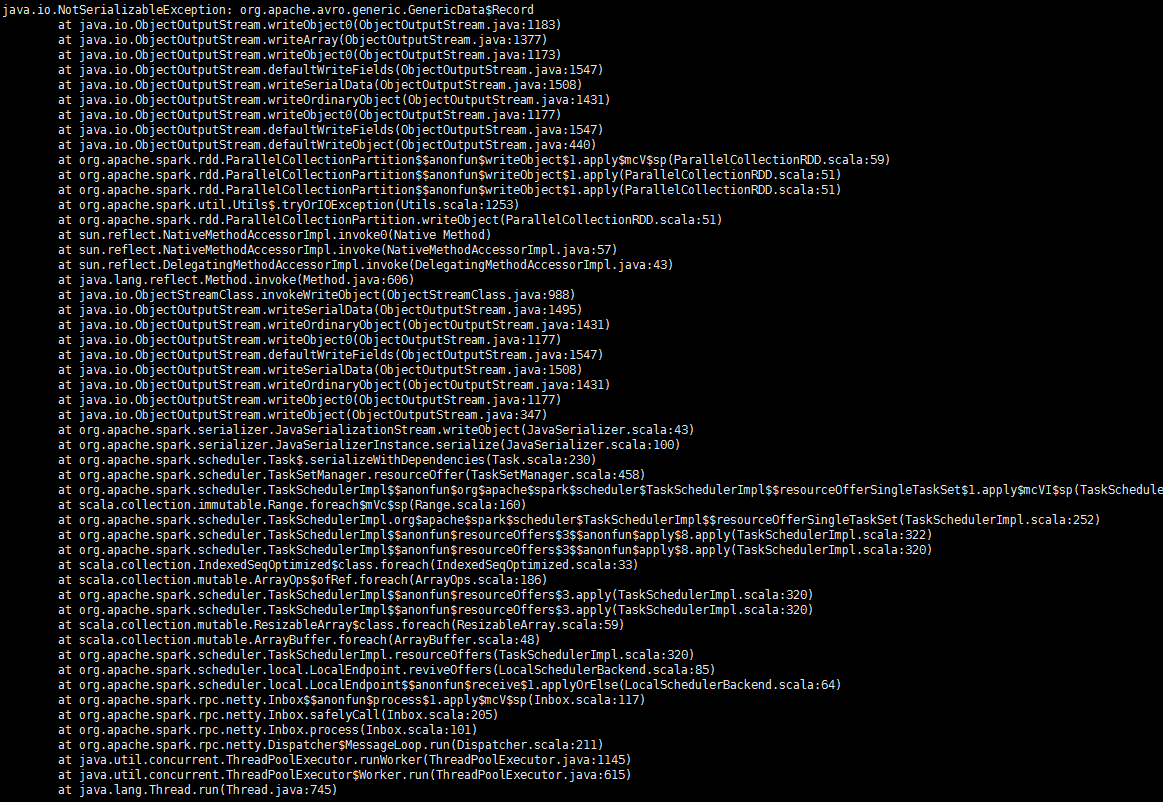
报错:






 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
