现在在学习hadoop(自学)。看的速度很慢,也不是很全面。遇到了一个问题。在看网上的例子的时候关于mapreduce 的二次排序。就是
1 3
2 1
3 2
1 1
1 5
2 6
6 1
5 3
7 8
6 2
5 1 这样的一组数据,排序完了是
1 1
1 3
1 5
2 1
。。。。。。
这种的。(相信你们都写过)
自己写的自定义KEY实现了WritableComparable ,在里边写一个内部类实现WritableComparator 。写完了也不明白
WritableComparable 里边的compare什么时候调用,WritableComparator 里边的compare什么时候调用。就像下面这样。
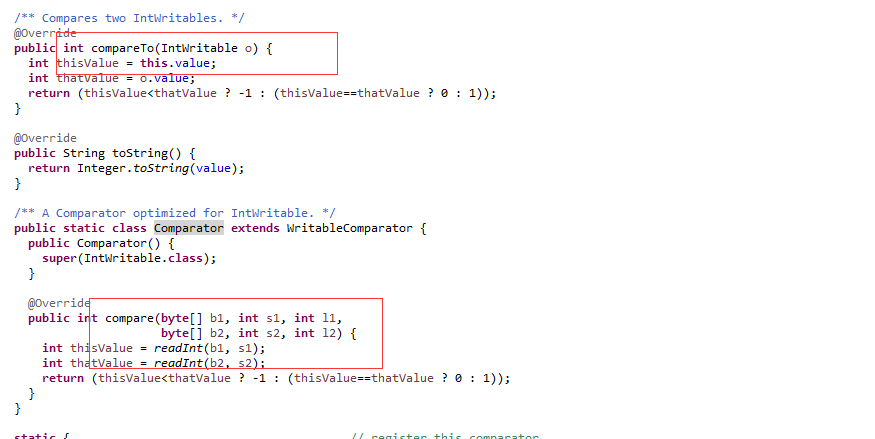
这是IntWritable源码。
排序和分组是先排序还是先分组呢。排序调用的那个方法,分组调用的哪个方法。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


