社区
Spark
帖子详情
hadoop jobhistory问题。求大神
鲨鱼吃辣椒
2017-09-07 05:43:22
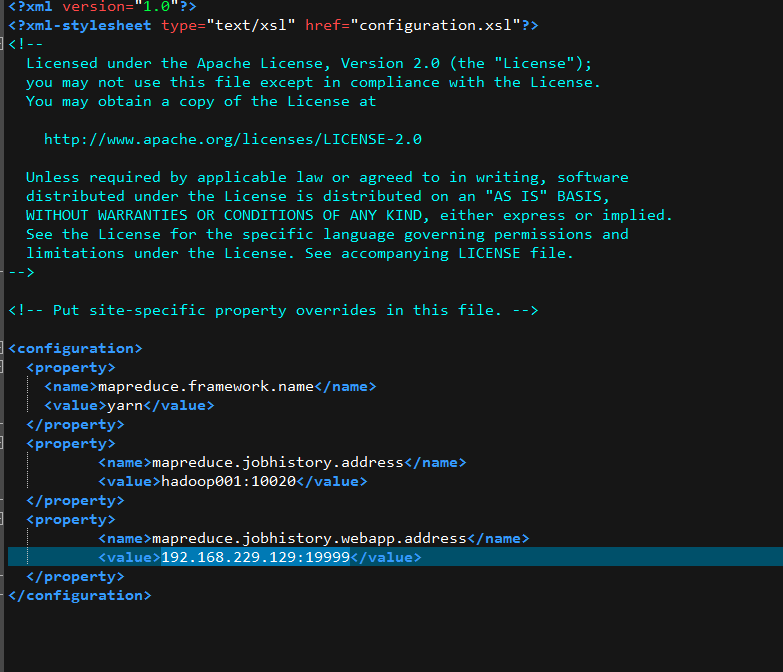
jobhistory server正常启动,端口未占用,我配置的端口19999,访问192.168.229.129:19999拒绝
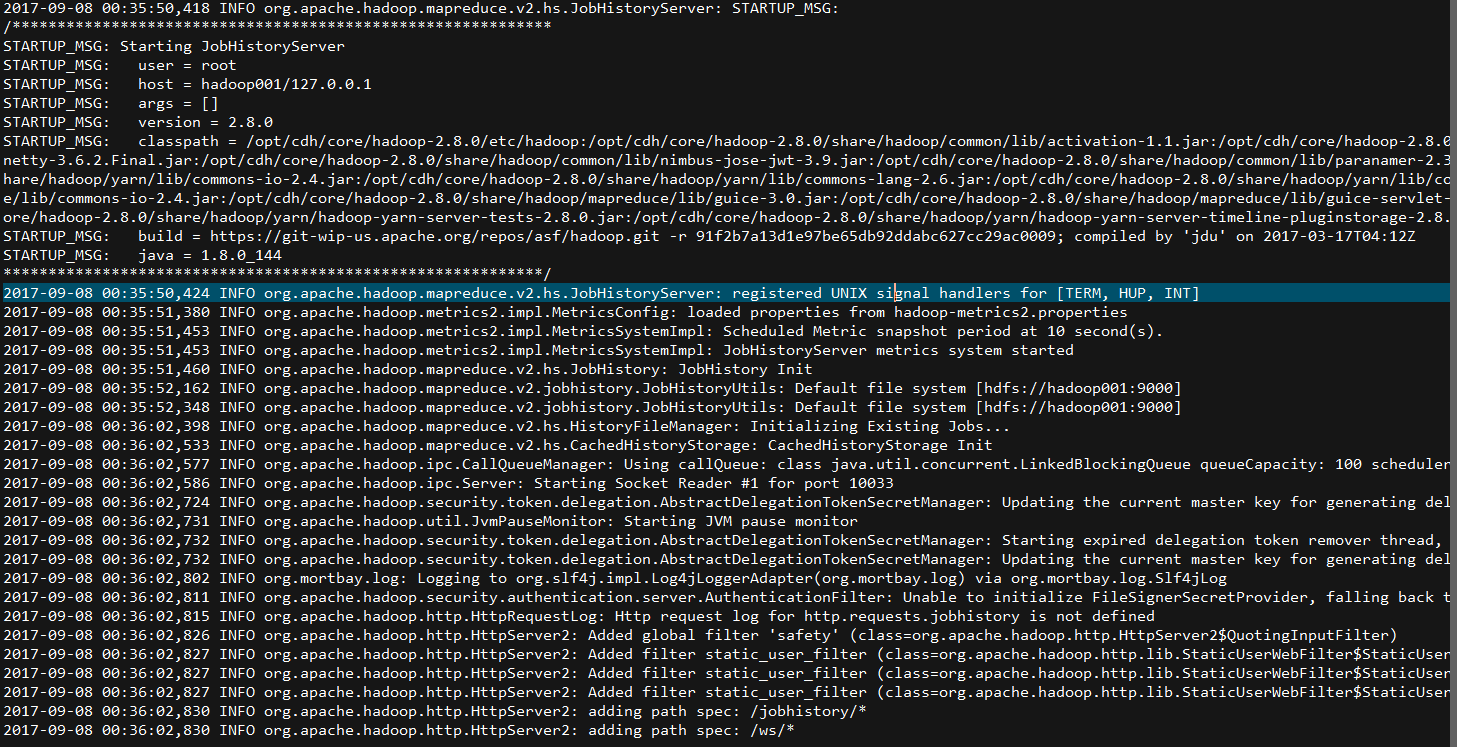
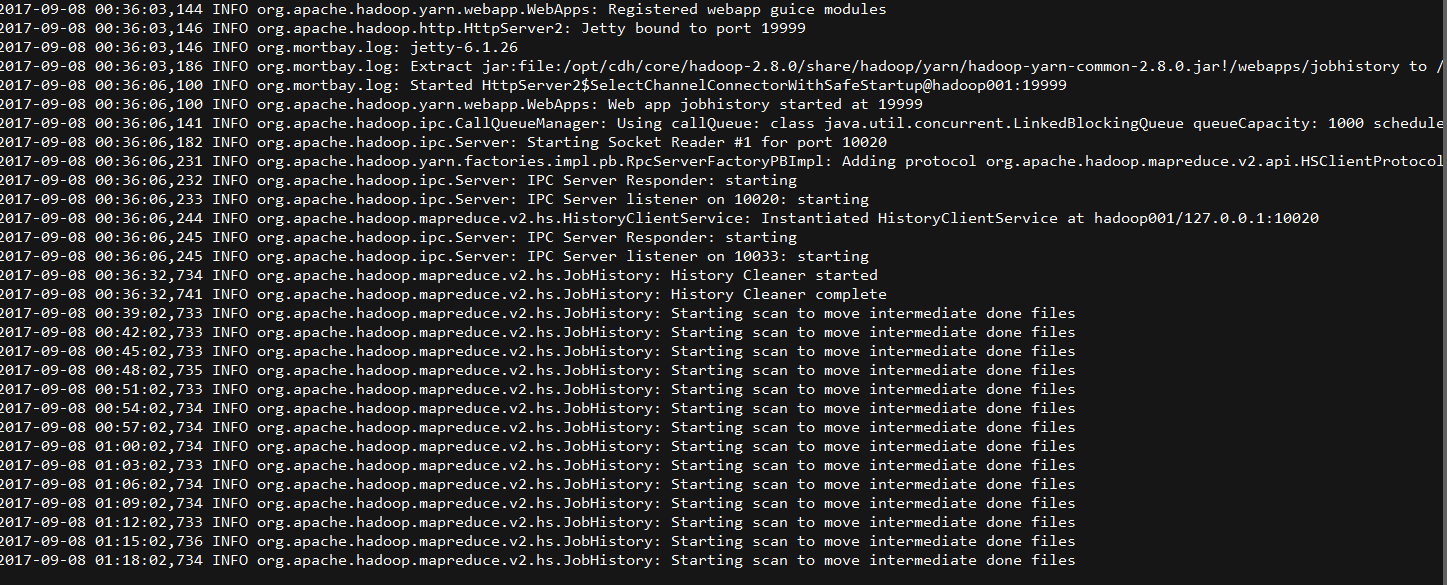
日志在下面:
...全文
709
回复
打赏
收藏
hadoop jobhistory问题。求大神
jobhistory server正常启动,端口未占用,我配置的端口19999,访问192.168.229.129:19999拒绝 日志在下面:
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
job
history
无法显示
最近楼主在运维
hadoop
集群时,发现无法打开
job
history
的页面,这导致查找作业运行失败的原因时会相当的蛋疼。楼主对照着各路
大神
的帖子,反复对比关于
job
history
的各个配置参数,觉着都没有什么
问题
。 逐步定位
问题
: 一、查看
job
history
的进程是否是以
hadoop
的超级用户启动: 进程活着,是以
hadoop
的超级用户启动的。 二、查看
job
history
的日志: 在.
Hadoop
-2.7.3集群搭建中遇到的
问题
总结
0 前言:1)
Hadoop
集群搭建参照前一篇博文
Hadoop
集群安装配置教程 2)集群有三个节点:Master、Slave1、Slave2,其中Master只作namenode,其余两个从节点做datanode1 搭建过程中常用
Hadoop
指令:1)启动
Hadoop
指令:start-all.sh mr-
job
history
-daemon.sh start
history
server启动成功过程lo
hadoop
2.7.1安装部署错误,
求
大神
指导
环境,三台虚拟机,centos6.5,jdk 1.7.0_71,
hadoop
版本
hadoop
2.7.1 三台机分别配置/etc/sysconfig/network 为 NETWORKING=yes HOSTNAME=master NETWORKING=yes HOSTNAME=master2 NETWORKING=yes HOSTNAME=master3 配置/etc/h
hadoop
学习使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、
hadoop
的作用?
hadoop
是什么?
hadoop
能做什么?
hadoop
能为我司做什么?二、
hadoop
的配置1.引入库2.读入数据
问题
及解决解决办法:1、操作
Hadoop
时,改变了配置文件,报错ls: Call From
hadoop
01/192.168.1.128 to
hadoop
01:9000 failed on connection总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:随着人工智能的不断发
本地用HDFS的javaAPI访问云服务器
Hadoop
过程及
问题
(总结)
之前写了一篇在云服务器上搭建
Hadoop
单节点的文章,实现了浏览器查看
Hadoop
相关的界面,文章链接如下: CDH版
Hadoop
云服务器的单节点和集群安装(附CDH自编译版本) 如果要在本地通过用HDFS的JavaAPI访问云服务器上的
Hadoop
服务,之前的配置是不行的,下面就写一下: 1.开始及遇到
问题
从上篇文章的配置开始讲起:涉及到服务地址,core-site.xml、hdfs-site...
Spark
1,261
社区成员
1,169
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

