

求助:KEGG官方工具KofamKOALA的版本问题!!
社区首页 (3628)
 我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3628
我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3628
请编写您的帖子内容
社区频道(7)
显示侧栏
卡片版式
全部
问答
软件
机器学习
文献分享
博文收录
Ada助手


215
评分
回复


Ubuntu 服务器安装远程 Rstudio(图文详解)
文章目录一、环境二、安装三、常用操作重启关闭启动检测配置文件查看状态四、配置`rserver.conf` 配置清单`rsession.conf` 配置清单一、环境系统:Debian 10 / Ubuntu 18 / Ubuntu 20R版本:> 3.0二、安装sudo apt-get install r-basesudo apt-get install gdebi-corewget https://download2.rstudio.org/server/bionic/amd64/rst
复制链接 扫一扫
分享

112
评分
回复

用 Zotero 高效管理文献(图文详解)
一、下载与安装下载网址:https://www.zotero.org/download注册网址:https://www.zotero.org/user/register二、同步设置这一步极其重要,是 Zotero 强大功能的起点,我们可以将感兴趣的论文的 PDF,文献信息存放在云端,结合PDF 阅读器,甚至可以把 PDF 上的笔记一起保存到云端。当有需要的时候,可以从浏览器,电脑,手机,平板来访问这些信息。1、进入首选项2、输入刚刚注册信息,登录电脑版 Zotero,点击设置同步3、同步
复制链接 扫一扫
分享

110
评分
回复
JS 中 Json 数据的快速排序
主角为 `sort(sortby)`参数 `sortby` 是一个比较函数,该函数要比较两个值(a,b),返回值用来描述两个值的大小,具体规则为:- a < b,返回负值,排序后, a 在 b 之前- a = b,返回 0- a > b,返回正值,排序后, a 在 b 之后
复制链接 扫一扫
分享
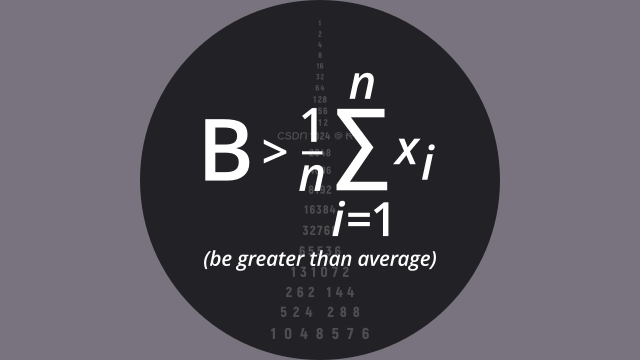
336
评分
回复

生物信息学导师推荐(持续更新)
本系列会持续更新,帮助大家找到更适合自己的导师,注意排名不分先后,接下来我们开始介绍:陈润生])单位:中国科学院生物物理研究所方向:长非编码RNA以及编码小肽的系统发现和功能机制研究成果:参加人类基因组1%和水稻基因组工作草图的研究;非编码RNA数据库NONCODE主页:http://people.ucas.ac.cn/~runshengchen邮箱: crs@ibp.ac.cn刘小乐单位:Harvard Medical School方向:表观遗传,癌症,发育成果:MACS(Mod
复制链接 扫一扫
分享

114
评分
回复
Python 中变量的多种复制方法(常规拷贝,浅拷贝,深拷贝)
常规拷贝大家常用的变量复制方法,用“=”就行。但是!但是!但是!在我们复制字典和列表时会和我们预想的不一致接下来,做个小实验常规拷贝在原始变量 x 的改变后,因为共用同一个内存地址,因此会直接放到被复制的变量 y 上,导致“不知情”的情况下导致 y 变量在没有操作的情况下改变。浅拷贝解决办法就是使用浅拷贝浅拷贝会将两个变量分别放在不同的内存地址,解决了常规拷贝的缺点。深拷贝但是,对于字典或列表中有嵌套的情况,浅拷贝同样不会生效。这时候就需要用的深拷贝。可以看到,深拷贝可以解决
复制链接 扫一扫
分享

124
评分
回复
图解机器学习:分类模型性能评估指标
人间出现一种怪病,患病人群平时正常,但偶尔暴饮暴食,这种病从外观和现有医学手段无法分辨。为了应对疫情,准备派齐天大圣去下界了解情况。
复制链接 扫一扫
分享

159
评分
回复
数据库涉及大量数据查询时的注意事项
避免频繁连接和关闭数据库,这样会导致IO访问次数太频繁。设计表时要建立适当的索引,尤其要在 where 及 order by 涉及的列上建立索引避免全表扫描,以下情况会导致放弃索引直接进行全部扫描避免在 where 子句中使用!=或<>操作符避免在 where 子句中对字段进行 null 值判断select id from table where num is null解决方法:建表时设置默认值0,也就是将null用0填充,然后查询:select id fr..
复制链接 扫一扫
分享

112
评分
回复
axios 使用详解
一、安装cnpm install axios二、使用三种写法// 第一种写法axios.get('/query?name=tom').then(function (response) { console.log(response);}).catch(function (error) { console.log(error);});// 第二种写法axios.get('/query', { params: { name: 'tom' }})
复制链接 扫一扫
分享



157
评分
回复
白墨的生物信息自学之路
进入21世纪后,组学数据井喷式产出,随之而来的问题是如何处理这些数据,挖掘背后隐藏的价值。人们想到利用包括计算机,物理学,数学,统计学在内学科的优势去解析这些大数据,随之催生出一门新的交叉学科,这就是生物信息学。这门学科为生物进化,物种分类,育种技术,药物设计等领域起到巨大的推动作用。不仅使我们更加全面的认识生命,而且随之带来了丰厚的社会效益。这里记录了我学习生物信息时,在平坦道路上曲折前行的步伐。可以为打算学,正在学生物信息的同学提供一些参考,少走一些弯路。让我们一起披荆斩棘,乘风破浪。这.
复制链接 扫一扫
分享
为您搜索到以下结果:







