
动画详解Transformer模型以及变形模型
社区首页 (3674)
 我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3674
我加入的社区 我管理的社区 官方推荐社区
76
其他社区
3674
请编写您的帖子内容
社区频道(1)
显示侧栏
卡片版式
动画详解Transformer模型以及变形模型
最新发布
最新回复
标题
阅读量
内容评分
精选
1789
5.0
10


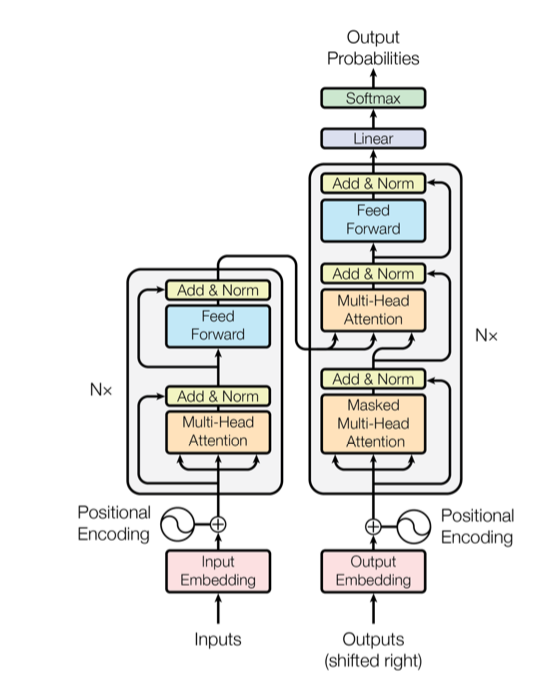
动画详解Transformer模型以及变形模型
课程名称适应人群动画详解Transformer模型以及变形模型1、适合对人工智能领域感兴趣 2、适合对transformer模型感兴趣的入门者 3、想学习transformer模型的初学者 4、对transformer模型有疑问者 5、想入门NLP领
复制链接 扫一扫
分享




为您搜索到以下结果:
4
社区成员
94
社区内容
 发帖
发帖 与我相关
与我相关 我的任务
我的任务

动画详解Transformer模型以及变
头条 人工智能研究所 ,计算机视觉,NLP
复制链接 扫一扫
 分享
分享确定
社区描述
头条 人工智能研究所 ,计算机视觉,NLP transformernlp 个人社区
社区管理员
加入社区
获取链接或二维码

- 近7日
- 近30日
- 至今
加载中
社区公告
暂无公告