大侠们,帮帮忙,分析分析这段代码, :)
int small_push(small_piece **freed, small_piece ***used, void *ptr1, size_t size1)
{
small_piece *piece;
if ((*freed) == 0)
return 0;
piece = (*freed);
(*freed) = (*freed)->next;
piece->next = (*used)[size1];
piece->block = ptr1;
(*used)[size1] = piece;
return 1;
}
void *small_pop(handle_mm *mm, size_t size)
{
small_piece *piece;
if (mm->small->cache[size] == 0)
return 0;
piece = mm->small->cache[size];
mm->small->cache[size] = mm->small->cache[size]->next;
piece->next = mm->small->piece_pck;
mm->small->piece_pck = piece;
return piece->block;
}
为什么两次,数量级(100万),调用的效率不同?
以下是初始化链表生成代码如下:
//Build Link List
small->piece_pck = &small->piece_pck_s[0];
small->piece_pck->next = 0;
for (i = 1; i<total_pck; i++)
{
piece = &small->piece_pck_s[i];
piece->next = small->piece_pck;
small->piece_pck = piece;
}
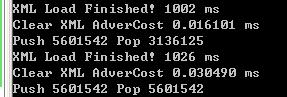
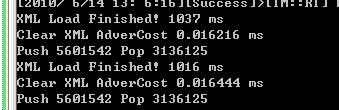
第一次调用,是最快的, 耗时在 0.015 ms, 第二次完全一样的调用, 耗时在 0.030 ms左右, 第三次,比第二次快了一点,但是没有第一次快。
我把链表复原,即重新Build之后,效率又同第一次一样, 内存地址读取的时间为什么会变化?明明操作全部一样,效率缺变化了,现在可以排除操作系统的碎片因素,我尝试过汇编,但是直接的感觉不是代码的效率, 请各位大侠帮忙分析分析,问题在哪儿?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享