分页查询大数据量越往后越慢如何解决及索引如何构建比较合理?
数据库:mytable,目前记录130万左右;
字段:id-ID主键已加索引,version-版本,h_fid-单位ID,hs_fid-部门ID, fid-用户ID, login_time-登录时间(yyyyMMddHHmmss,比如:20130626170722), state-状态, hs_name-部门名字, name-用户名字
以前用MySQL数据库,百来万条数据库在表中,相同的查询条件,跳转到最后一页时,除了第一次查询有点点慢(2秒以内),如再进行查询相同页数的记录时,几乎不花什么时间,都是在几个纳秒以内;
由于客户扩容本项目,改用了Oracle数据库,现在发现,查询前面几页时,速度还行,越往后查越慢,直接跳转到最后一页时,简直弱爆了,都有30秒左右,查询语句如下:
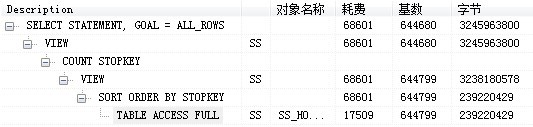
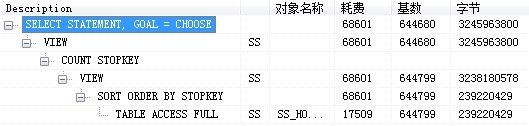
select * from ( select row_.*, rownum rownum_ from ( select t.id as id_1, t.version as ver_1, t.h_fid as h_fid_1, t.hs_fid as hs_fid_1, t.fid as fid_1, t.login_time as log_1, t.state as sta_1,t.h_name as hs_name_1,t.name as name_1 from wf.mytable t where t.state=1 and t.h_fid='5a4ca4a22a74f721012a7dcf16890013' order by t.ss_fid, t.ss_hs_fid, t.login_time) row_ where rownum <= 1000720) where rownum_ > 1000701
这个语句只是查询具体记录信息,按理还需要一个select count (*) from (select t.id as id_1, t.version as ver_1, t.h_fid as h_fid_1, t.hs_fid as hs_fid_1, t.fid as fid_1, t.login_time as log_1, t.state as sta_1,t.h_name as hs_name_1,t.name as name_1 from wf.mytable t where t.state=1 and t.h_fid='5a4ca4a22a74f721012a7dcf16890013' order by t.ss_fid, t.ss_hs_fid, t.login_time),才能够得出记录总数,最分页用,这个语句也是耗时大概8秒左右
先说明一个问题,现在项目用的是Hibernate3.0,分页用的是setFirstResult(),setMaxResults(),以上的查询分页语句是Hibernate框架自行构造;
故有以下问题:
1、需要怎么优化数据库配置才能够缓解这种延时现象吗?比如是否需要给数据库配置默认初始内存和缓存大小之类的。
2、如果需要加索引,按照这样的查询语句该如何构建索引比较合理,是否需要组合索引?
3、Hibernate是否需要启用二级缓存(估计该问题不应该在这个版块中提,只作为引子而已)
期待大侠的赐招,小生在下有礼,先谢过!



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享