13,189
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享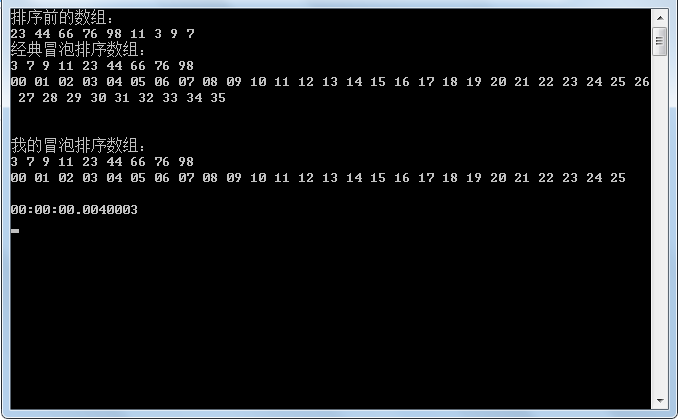
int temp = 0, 次 = 0;
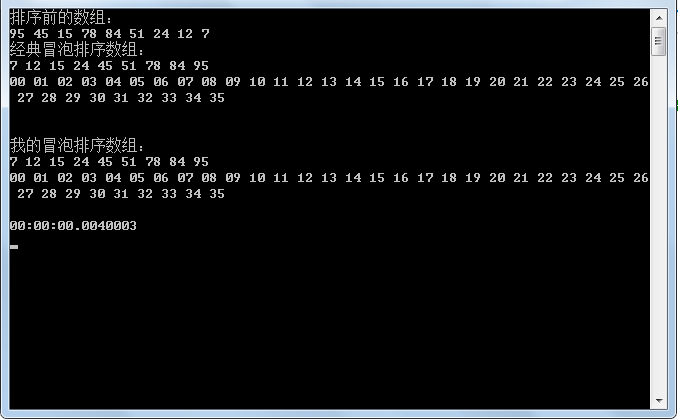
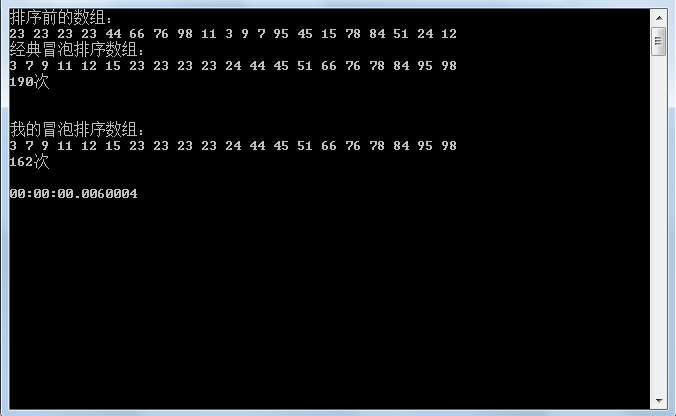
int[] arr = { 23, 23, 23, 23, 44, 66, 76, 98, 11, 3, 9, 7, 95, 45, 15, 78, 84, 51, 24, 12 };
Console.WriteLine("排序前的数组:");
foreach (int item in arr)
Console.Write(item + " ");
Console.WriteLine();
for (int i = 0; i < arr.Length - 1; i++)
{
for (int j = 0; j < arr.Length - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
}
次++;
}
}
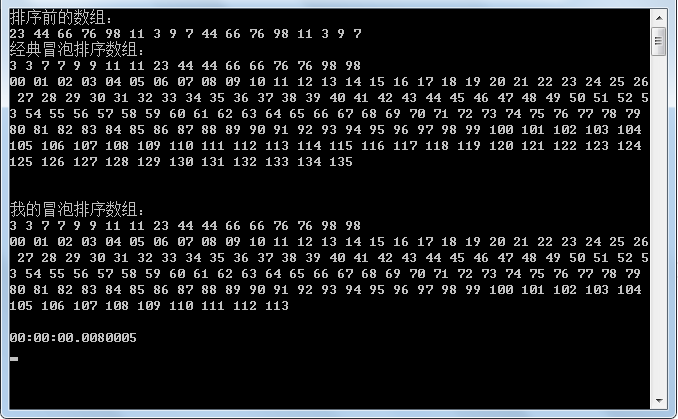
Console.WriteLine("经典冒泡排序数组:");
foreach (int item in arr)
Console.Write(item + " ");
Console.WriteLine("\n" + 次 + "次\n");
arr = new int[] { 23, 23, 23, 23, 44, 66, 76, 98, 11, 3, 9, 7, 95, 45, 15, 78, 84, 51, 24, 12 };
次 = 0;
for (int i = 0; i < arr.Length - 1; i++)
{
if (arr[i] > arr[i + 1])
{
temp = arr[i + 1];
for (int j = i; j >= 0; j--)
{
if (arr[j] > arr[j + 1])
{
arr[j + 1] = arr[j];
arr[j] = temp;
}
次++;
}
}
}
Console.WriteLine("\n我的冒泡排序数组:");
foreach (int item in arr)
Console.Write(item + " ");
Console.WriteLine("\n" + 次 + "次\n");






 突然想问问你,这位龙泉寺的长老,你可认得?
突然想问问你,这位龙泉寺的长老,你可认得?
int temp = 0; List <int> 随机数组 = new List <int>();
foreach (var aa in new int[100]) { 随机数组.Add(new Random().Next(1, 99)); System.Threading.Thread.Sleep(40); }
int[] arr = { 23, 23, 23, 23, 44, 66, 76, 98, 98, 98, 98, 11, 3, 9, 7, 95, 45, 15, 78, 84, 51, 24, 12, 23, 23, 23, 44, 66, 76, 98, 98, 98, 98, 11, 3, 9, 7, 95, 45, 15, 78, 84, 51, 24, 12 };
arr = 随机数组.ToArray();
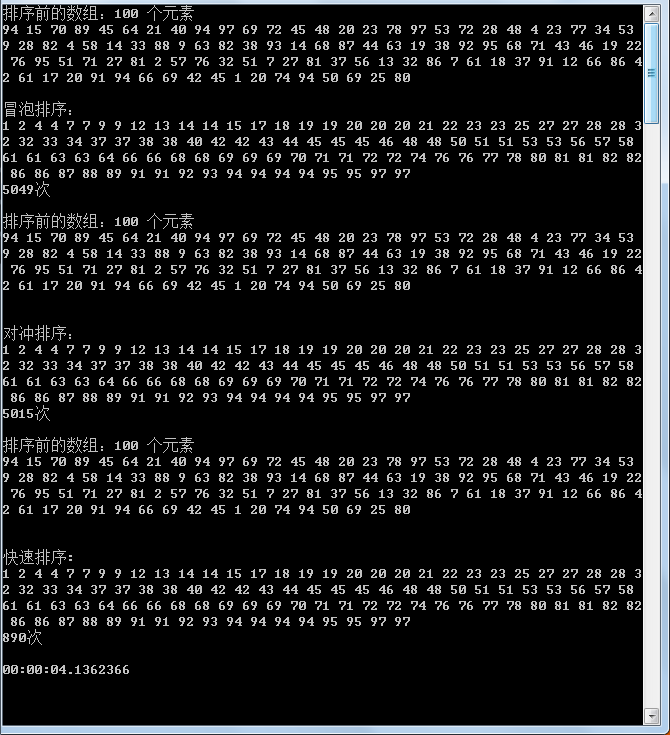 第二次小到大排序数组,
第二次小到大排序数组,
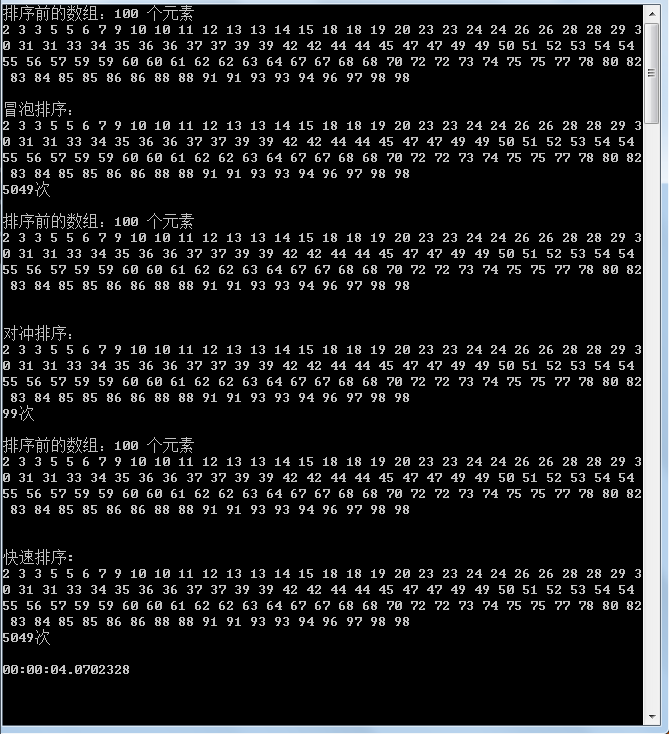 第三次大到小排序数组
第三次大到小排序数组
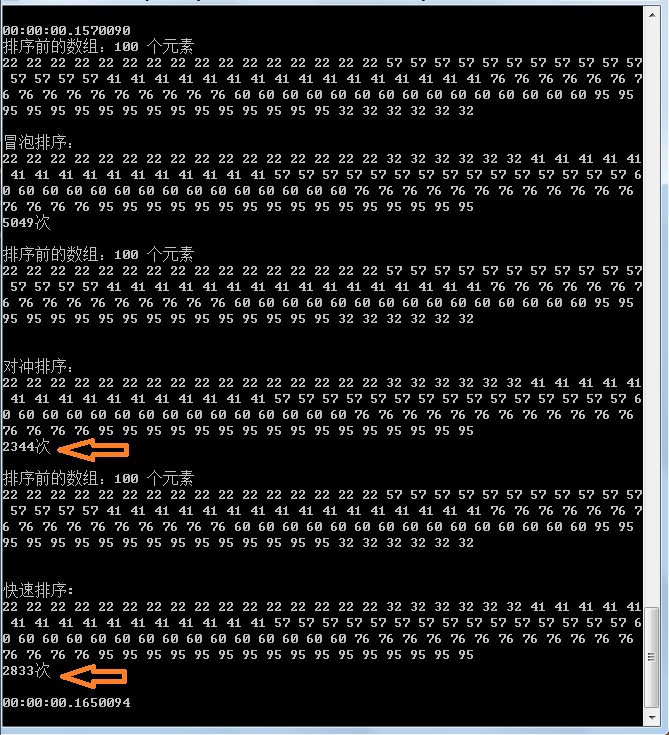
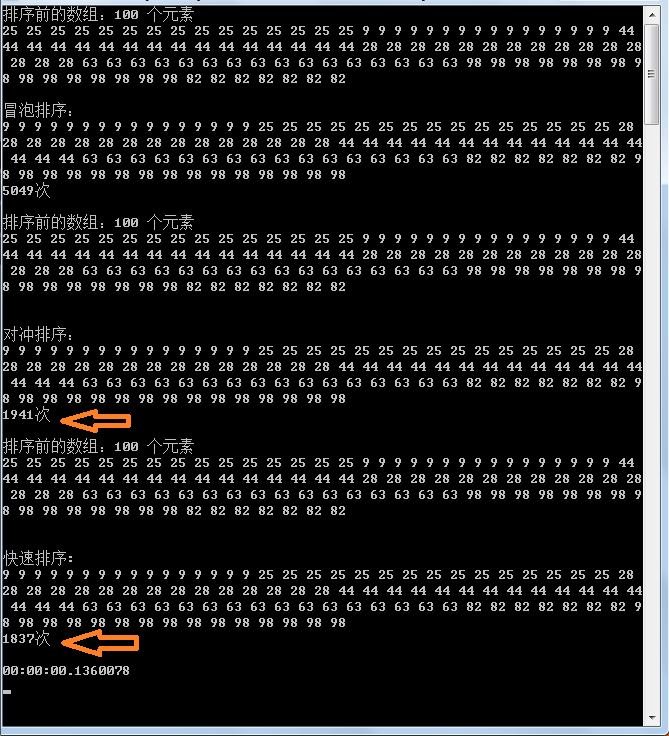
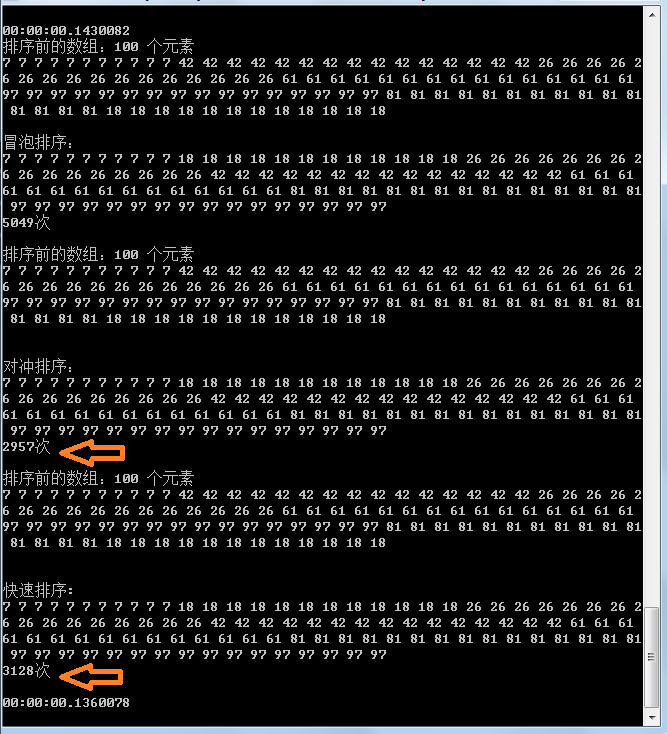
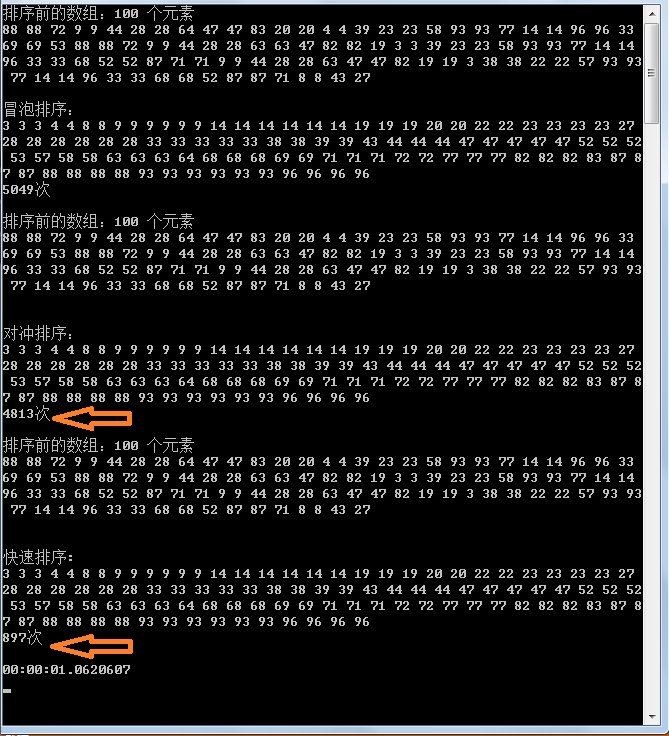
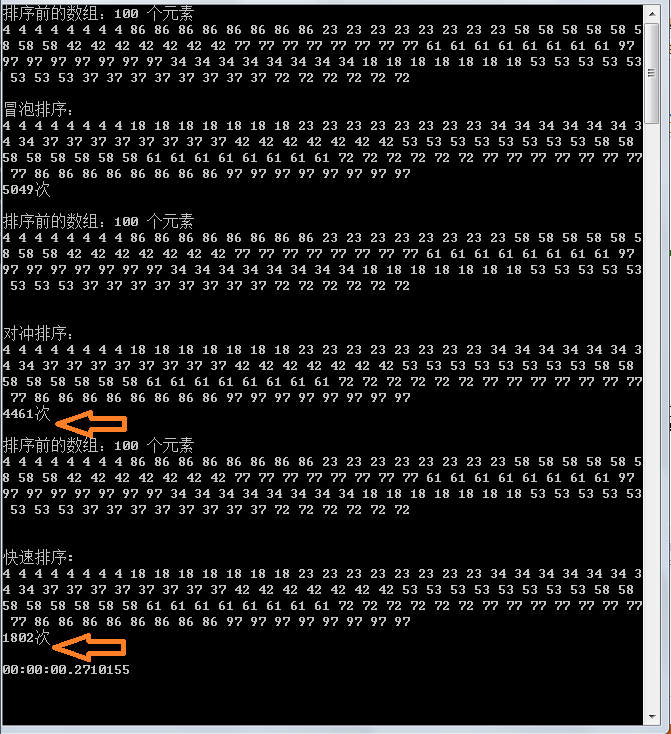
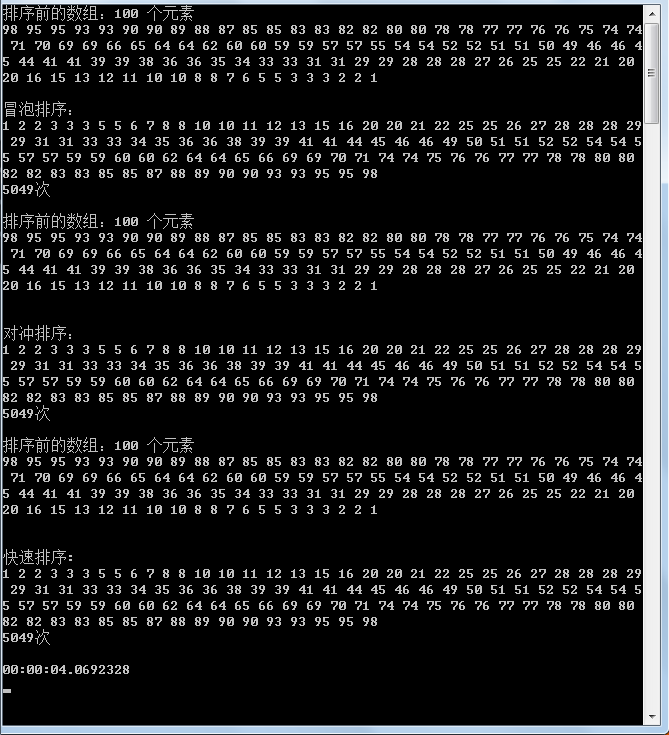 事实胜于雄辩,用事实说话,可以看到:
快速排序确实对随机数组效率很好,但对于有序数组无论大小序效率一样
冒泡排序似乎无关痛痒
我的排序暂时给不同名称叫对冲吧,因为设计它的动作外环向下内环向上,可以看到对同向顺序数组和方向的不同表现以及随机数组的表现,假若随机数组中顺向越多则效率越好,推测其具有线性特征.
事实胜于雄辩,用事实说话,可以看到:
快速排序确实对随机数组效率很好,但对于有序数组无论大小序效率一样
冒泡排序似乎无关痛痒
我的排序暂时给不同名称叫对冲吧,因为设计它的动作外环向下内环向上,可以看到对同向顺序数组和方向的不同表现以及随机数组的表现,假若随机数组中顺向越多则效率越好,推测其具有线性特征.