问一个老生常谈的问题,oracle何时走索引,今天遇到一个奇怪的问题,查询一个表最近七天内的数据,数据量2w条左右,全表的数据量达到50多w,根据分析的很,数据量远远没有达到1/3,如果建了索引,应该会走索引才对,可这就奇怪了,它偏偏不走索引,但是加了order by之后,它就能走索引了,更奇怪的事是加了order by再加一个没有索引的条件,它又不会走索引了,感觉直接上sql说得清楚些,如下:
全部的数据量:

符合条件的数据量:

查询最近七天的数据不会自动走索引(create_time上建了索引)(执行计划):

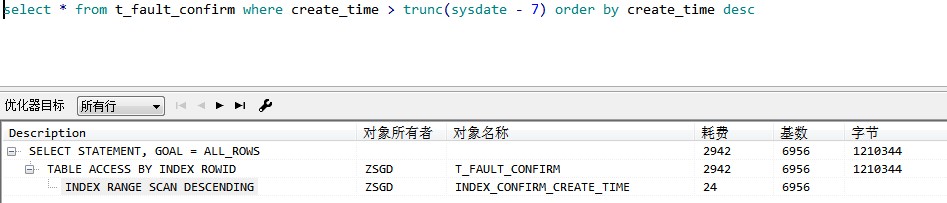
加了orderby之后能走索引:
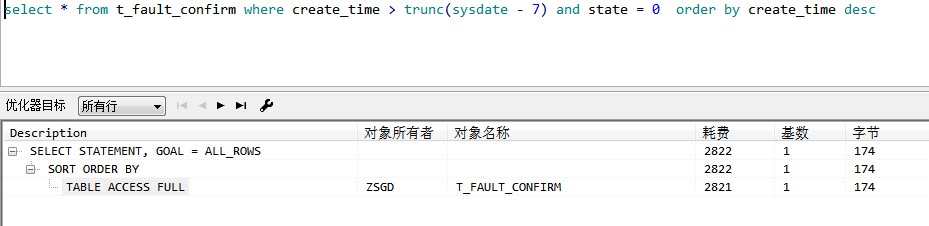
再加一个没有索引的条件,又变成了不会走索引:
我知道可以使用hint让它强制走索引,但是我想了解一下oracle优化器是怎么思考,有木有大虾能解释一下不,小弟不胜感激


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





