C++ Character Constants
Character constants are one or more members of the “source character set,” the character set in which a program is written, surrounded by single quotation marks ('). They are used to represent characters in the “execution character set,” the character set on the machine where the program executes.
Microsoft Specific
For Microsoft C++, the source and execution character sets are both ASCII.
END Microsoft Specific
There are three kinds of character constants:
Normal character constants
Multicharacter constants
Wide-character constants
Note Use wide-character constants in place of multicharacter constants to ensure portability.
Character constants are specified as one or more characters enclosed in single quotation marks. For example:
char ch = 'x'; // Specify normal character constant.
int mbch = 'ab'; // Specify system-dependent
// multicharacter constant.
wchar_t wcch = L'ab'; // Specify wide-character constant.
Note that mbch is of type int. If it were declared as type char, the second byte would not be retained. A multicharacter constant has four meaningful characters; specifying more than four generates an error message.
Syntax
character-constant :
'c-char-sequence'
L'c-char-sequence'
c-char-sequence :
c-char
c-char-sequence c-char
c-char :
any member of the source character set except the single quotation mark ('), backslash (\), or newline character
escape-sequence
escape-sequence :
simple-escape-sequence
octal-escape-sequence
hexadecimal-escape-sequence
simple-escape-sequence : one of
\' \" \? \\
\a \b \f \n \r \t \v
octal-escape-sequence :
\octal-digit
\octal-digit octal-digit
\octal-digit octal-digit octal-digit
hexadecimal-escape-sequence :
\xhexadecimal-digit
hexadecimal-escape-sequence hexadecimal-digit
Microsoft C++ supports normal, multicharacter, and wide-character constants. Use wide-character constants to specify members of the extended execution character set (for example, to support an international application). Normal character constants have type char, multicharacter constants have type int, and wide-character constants have type wchar_t. (The type wchar_t is defined in the standard include files STDDEF.H, STDLIB.H, and STRING.H. The wide-character functions, however, are prototyped only in STDLIB.H.)
The only difference in specification between normal and wide-character constants is that wide-character constants are preceded by the letter L. For example:
char schar = 'x'; // Normal character constant
wchar_t wchar = L'\x81\x19'; // Wide-character constant
Table 1.2 shows reserved or nongraphic characters that are system dependent or not allowed within character constants. These characters should be represented with escape sequences.
Table 1.2 C++ Reserved or Nongraphic Characters
Character ASCII
Representation ASCII
Value Escape Sequence
Newline NL (LF) 10 or 0x0a \n
Horizontal tab HT 9 \t
Vertical tab VT 11 or 0x0b \v
Backspace BS 8 \b
Carriage return CR 13 or 0x0d \r
Formfeed FF 12 or 0x0c \f
Alert BEL 7 \a
Backslash \ 92 or 0x5c \\
Question mark ? 63 or 0x3f \?
Single quotation mark ' 39 or 0x27 \'
Double quotation mark " 34 or 0x22 \"
Octal number ooo — \ooo
Hexadecimal number hhh — \xhhh
Null character NUL 0 \0
If the character following the backslash does not specify a legal escape sequence, the result is implementation defined. In Microsoft C++, the character following the backslash is taken literally, as though the escape were not present, and a level 1 warning (“unrecognized character escape sequence”) is issued.
Octal escape sequences, specified in the form \ooo, consist of a backslash and one, two, or three octal characters. Hexadecimal escape sequences, specified in the form \xhhh, consist of the characters \x followed by a sequence of hexadecimal digits. Unlike octal escape constants, there is no limit on the number of hexadecimal digits in an escape sequence.
Octal escape sequences are terminated by the first character that is not an octal digit, or when three characters are seen. For example:
wchar_t och = L'\076a'; // Sequence terminates at a
char ch = '\233'; // Sequence terminates after 3 characters
Similarly, hexadecimal escape sequences terminate at the first character that is not a hexadecimal digit. Because hexadecimal digits include the letters a through f (and A through F), make sure the escape sequence terminates at the intended digit.
Because the single quotation mark (') encloses character constants, use the escape sequence \' to represent enclosed single quotation marks. The double quotation mark (") can be represented without an escape sequence. The backslash character (\) is a line-continuation character when placed at the end of a line. If you want a backslash character to appear within a character constant, you must type two backslashes in a row (\\). (SeePhases of Translation in the Preprocessor Reference for more information about line continuation.)
scanf Width Specification
width is a positive decimal integer controlling the maximum number of characters to be read from stdin. No more than width characters are converted and stored at the corresponding argument. Fewer than width characters may be read if a white-space character (space, tab, or newline) or a character that cannot be converted according to the given format occurs before width is reached.
The optional prefixes h, l, I64, and L indicate the “size” of the argument (long or short, single-byte character or wide character, depending upon the type character that they modify). These format-specification characters are used with type characters in scanf or wscanf functions to specify interpretation of arguments as shown in the Table R.7. The type prefixes h, l, I64, and L are Microsoft extensions and are not ANSI-compatible. The type characters and their meanings are described in Table R.8.
Table R.7 Size Prefixes for scanf and wscanf Format-Type Specifiers
To Specify Use Prefix With Type Specifier
double l e, E, f, g, or G
long int l d, i, o, x, or X
long unsigned int l u
short int h d, i, o, x, or X
short unsigned int h u
__int64 I64 d, i, o, u, x, or X
Single-byte character with scanf h c or C
Single-byte character with wscanf h c or C
Wide character with scanf l c or C
Wide character with wscanf l c, or C
Single-byte – character string with scanf h s or S
Single-byte – character string with wscanf h s or S
Wide-character string with scanf l s or S
Wide-character string with wscanf l s or S
Following are examples of the use of h and l with scanffunctions and wscanf functions:
scanf( "%ls", &x ); // Read a wide-character string
wscanf( "%lC", &x ); // Read a single-byte character
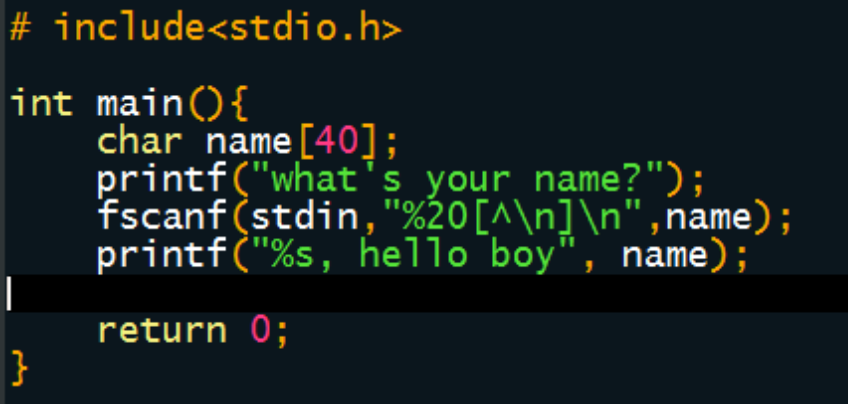
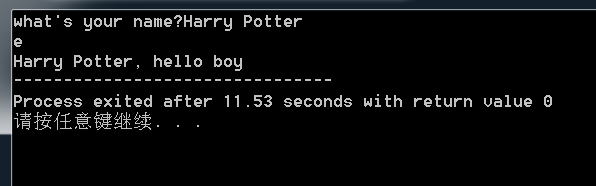
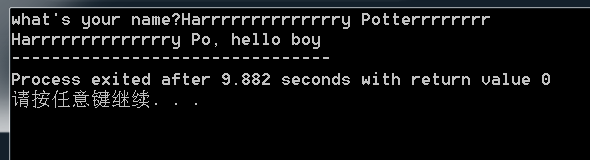
To read strings not delimited by space characters, a set of characters in brackets ([ ]) can be substituted for the s (string) type character. The corresponding input field is read up to the first character that does not appear in the bracketed character set. If the first character in the set is a caret (^), the effect is reversed: The input field is read up to the first character that does appear in the rest of the character set.
Note that %[a-z] and %[z-a] are interpreted as equivalent to %[abcde...z]. This is a common scanf function extension, but note that the ANSI standard does not require it.
To store a string without storing a terminating null character ('\0'), use the specification %nc where n is a decimal integer. In this case, the c type character indicates that the argument is a pointer to a character array. The next n characters are read from the input stream into the specified location, and no null character ('\0') is appended. If n is not specified, its default value is 1.
The scanf function scans each input field, character by character. It may stop reading a particular input field before it reaches a space character for a variety of reasons:
The specified width has been reached.
The next character cannot be converted as specified.
The next character conflicts with a character in the control string that it is supposed to match.
The next character fails to appear in a given character set.
For whatever reason, when the scanf function stops reading an input field, the next input field is considered to begin at the first unread character. The conflicting character, if there is one, is considered unread and is the first character of the next input field or the first character in subsequent read operations on stdin.



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享