

17,134
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享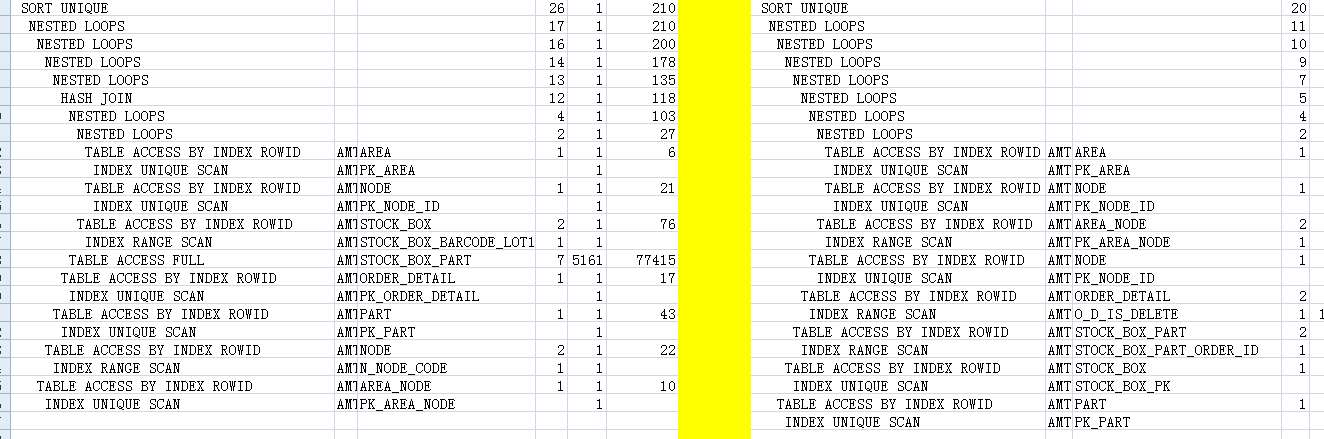



SELECT DISTINCT STOCK_BOX.ID AS ID,
STOCK_BOX.NODE_ID AS STORAGE_NODE_ID,
STOCK_BOX.NODE_ID AS FROM_NODE,
STOCK_BOX.BUSINESS_ID,
STOCK_BOX.BOX_BARCODE AS BOX_CODE,
STOCK_BOX.LOT1 AS LOTS,
STOCK_BOX.LENGTH AS LENGTH,
STOCK_BOX.HEIGHT AS HEIGHT,
STOCK_BOX.WIDTH AS WIDTH,
STOCK_BOX.WEIGHT AS WEIGHT,
STOCK_BOX_PART.PART_ID AS PART_ID,
STOCK_BOX_PART.QTY AS QUANTITY,
PART.PART_CODE AS PART_CODE,
PART.PART_NAME AS PART_NAME,
FN.NODE_CODE AS FROM_NODE_CODE,
FN.NODE_NAME AS FROM_NODE_NAME,
TN.ID AS TO_NODE,
TN.NODE_NAME AS TO_NODE_NAME,
ORDER_DETAIL.ID as DETAIL_ID
from STOCK_BOX_PART
INNER JOIN STOCK_BOX
ON STOCK_BOX.ID = STOCK_BOX_PART.STOCK_BOX_ID
INNER JOIN PART
ON STOCK_BOX_PART.PART_ID = PART.ID
JOIN NODE FN
ON FN.ID = STOCK_BOX.NODE_ID
JOIN ORDER_DETAIL ------------数据量大
ON ORDER_DETAIL.ID = STOCK_BOX_PART.ORDER_DETAIL_ID
AND ORDER_DETAIL.IS_DELETE = 'N'
JOIN NODE TN
ON TN.NODE_CODE = ORDER_DETAIL.RECEIVE_NODE_CODE
AND TN.IS_DELETE = 'N'
JOIN AREA_NODE
ON AREA_NODE.NODE_ID = TN.ID
JOIN AREA
ON AREA.ID = AREA_NODE.AREA_ID
AND AREA.IS_DELETE = 'N'
AND AREA_NODE.IS_DELETE = 'N'
AND AREA.ID in (4) -----------删掉这里的area.id 条件,查询结果返回area.id,在程序中判断
WHERE STOCK_BOX.IS_DELETE = 'N'
AND PART.IS_DELETE = 'N'
AND STOCK_BOX.NODE_ID = 2149
AND STOCK_BOX.BUSINESS_ID = '3'
AND STOCK_BOX.BOX_BARCODE = '33333333333333333333'
SELECT SDATA.*, PART.PART_CODE
FROM (select DISTINCT STOCK_BOX.ID AS ID,
STOCK_BOX.NODE_ID AS STORAGE_NODE_ID,
STOCK_BOX.NODE_ID AS FROM_NODE,
STOCK_BOX.BUSINESS_ID,
STOCK_BOX.BOX_BARCODE AS BOX_CODE,
STOCK_BOX.LOT1 AS LOTS,
STOCK_BOX.LENGTH AS LENGTH,
STOCK_BOX.HEIGHT AS HEIGHT,
STOCK_BOX.WIDTH AS WIDTH,
STOCK_BOX.WEIGHT AS WEIGHT,
STOCK_BOX_PART.PART_ID AS PART_ID,
STOCK_BOX_PART.QTY AS QUANTITY,
/* PART.PART_CODE AS PART_CODE,
PART.PART_NAME AS PART_NAME,*/
FN.NODE_CODE AS FROM_NODE_CODE,
FN.NODE_NAME AS FROM_NODE_NAME,
/* TN.ID AS TO_NODE,
TN.NODE_NAME AS TO_NODE_NAME,*/
STOCK_BOX_PART.ORDER_DETAIL_ID as DETAIL_ID
from STOCK_BOX
INNER JOIN STOCK_BOX_PART
ON STOCK_BOX.ID = STOCK_BOX_PART.STOCK_BOX_ID
JOIN NODE FN
ON FN.ID = STOCK_BOX.NODE_ID
WHERE STOCK_BOX.IS_DELETE = 'N'
AND STOCK_BOX.NODE_ID = 100
AND STOCK_BOX.BUSINESS_ID = '3'
AND STOCK_BOX.BOX_BARCODE = '00000000300003058664') SDATA----这里每次查询结果只会有一条
JOIN PART
ON (SDATA.PART_ID = PART.ID)
JOIN ORDER_DETAIL
ON ORDER_DETAIL.ID = SDATA.DETAIL_ID
JOIN NODE TN
ON TN.NODE_CODE = ORDER_DETAIL.RECEIVE_NODE_CODE
AND TN.IS_DELETE = 'N'
JOIN AREA_NODE
ON AREA_NODE.NODE_ID = TN.ID
JOIN AREA
ON AREA.ID = AREA_NODE.AREA_ID
WHERE AREA.IS_DELETE = 'N'
AND AREA.IS_DELETE = 'N'
AND AREA_NODE.IS_DELETE = 'N'
AND ORDER_DETAIL.IS_DELETE = 'N'
AND AREA.ID in (25)




