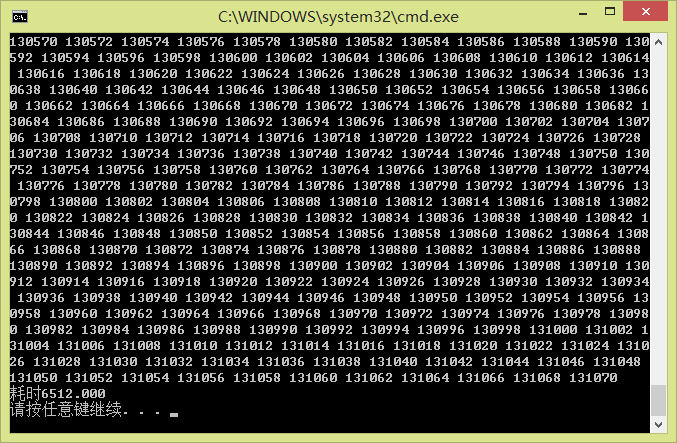
这是没用cuda的
#include <stdio.h>
#include<time.h>
int main()
{
void fun(long int N);
clock_t start, finish;
start = clock();
fun(65536);
finish = clock();
printf("耗时%.3lf\n", (double)finish - start);
return 0;
}
void fun(long int N)
{
long int h_a[65536];long int h_b[65536]; long int h_c[65536];
for (long long int i = 0; i < N; i++)
{
h_a[i] = i;
h_b[i] = i;
h_c[i] = 0;
}
for (long int j = 0; j < N; j++)
{
h_c[j] = h_a[j] + h_b[j] ;
printf("%ld ", h_c[j]);
}
printf("\n");
}
这是用了cuda的

cuda代码如下
#include<time.h>
#include <malloc.h>
#include <stdio.h>
#include <cuda_runtime.h>
/* 运行在GPU端的程序 */
__global__ void vectorADD(int* a, int* b, int* c)
{
int index = threadIdx.x+blockIdx.x*blockDim.x;//获得当前线程的序号
if (index < 65536)
c[index] = a[index]+ b[index] ;
}
int main()
{
clock_t start, finish;
start = clock();
void fun(int N);
fun(65536);
finish = clock();
printf("耗时%.3lf\n", (double)finish - start);
return 0;
}
void fun(int N)
{
/* 本地开辟三个数组存放我们要计算的内容 */
int* h_a = (int*)malloc(N * sizeof(int));
int* h_b = (int*)malloc(N * sizeof(int));
int* h_c = (int*)malloc(N * sizeof(int));
/* 初始化数组A, B和C */
for (int i = 0; i<N; i++)
{
h_a[i] = i;
h_b[i] = i;
h_c[i] = 0;
}
/* 计算N个int型需要的空间 */
int size = N * sizeof(int);
/* 在GPU上分配同样大小的三个数组 */
int* d_a;
int* d_b;
int* d_c;
cudaMalloc((void**)&d_a, size);
cudaMalloc((void**)&d_b, size);
cudaMalloc((void**)&d_c, size);
/* 把本地的数组拷贝进GPU内存 */
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_c, h_c, size, cudaMemcpyHostToDevice);
/* 定义一个GPU运算块 由 10个运算线程组成 */
dim3 DimBlock = 128;
/* 通知GPU用10个线程执行函数vectorADD */
vectorADD <<<512, DimBlock >>>(d_a, d_b, d_c);
/* 将GPU运算完的结果复制回本地 */
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
/* 释放GPU的内存 */
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
/* 验证计算结果 */
for (int j = 0; j<N; j++)
printf("%d ", h_c[j]);
printf("\n");
}



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



