


590
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享cudaStream_t *stream1 = (cudaStream_t*)malloc(nStream * sizeof(cudaStream_t));
for (unsigned int i = 0; i<nStream; i++)
HANDLE_ERROR(cudaStreamCreate(&(stream1[i])));
cufftHandle plan1[nStream];
for (unsigned int i = 0; i<nStream; i++)
{
cufftSafeCall(cufftPlan1d(&plan1[i], nChannel, CUFFT_C2C, dataSteam));
cufftSafeCall(cufftSetStream(plan1[i], stream1[i]));
}
for (unsigned int i = 0; i < nStream; i++)
{
HANDLE_ERROR(cudaMemcpyAsync(dXX + (dataSteam * nChannel + iniValue)*i,
xx + dataSteam * nChannel * i, (dataSteam * nChannel + iniValue)*
sizeof(Complex), cudaMemcpyHostToDevice, stream1[i]));
}
for (unsigned int i = 0; i < nStream; i++)
{
cudaMakevv(dXX + i *(dataSteam * nChannel + iniValue), dHH, dVV +
(nStream - 1 - i) * dataSteam * nChannel, stream1[i]);//此函数为一个核函数
}
for (unsigned int i = 0; i < nStream; i++)
{
cufftSafeCall((cufftExecC2C(plan1[i], (cufftComplex *)(dVV +
(nStream - 1 - i) * dataSteam * nChannel), (cufftComplex *)(dVV + (nStream - 1 - i) *
dataSteam * nChannel), CUFFT_FORWARD)));
}
for (unsigned int i = 0; i < nStream; i++)
{
HANDLE_ERROR(cudaMemcpyAsync(yy2 + 64 * 9 + (nStream - 1 - i)*dataSteam * nChannel,
dVV + (nStream - 1 - i)*dataSteam * nChannel, dataSteam * nChannel * sizeof(Complex),
cudaMemcpyDeviceToHost, stream1[i]));
}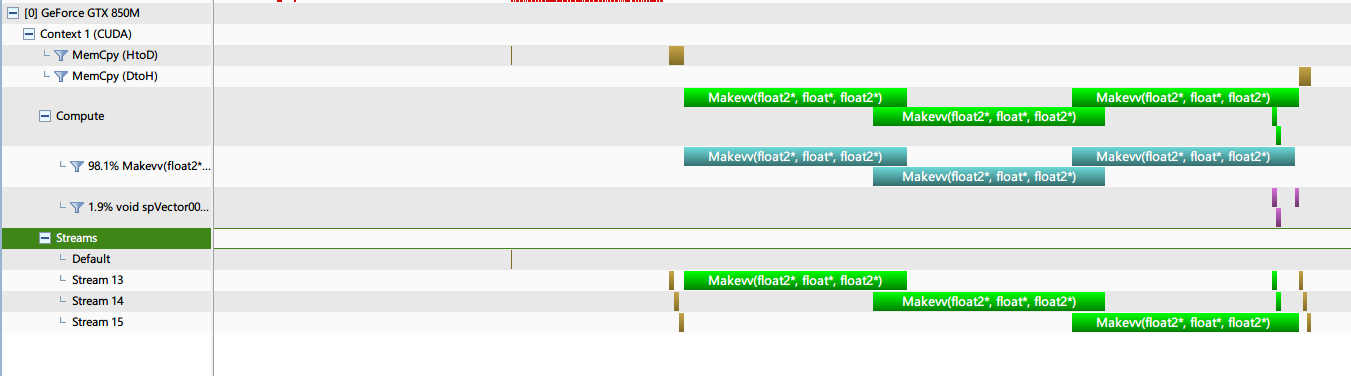
cudaStream_t *stream1 = (cudaStream_t*)malloc(nStream * sizeof(cudaStream_t));
for (unsigned int i = 0; i<nStream; i++)
HANDLE_ERROR(cudaStreamCreate(&(stream1[i])));
cufftHandle plan1[nStream];
for (unsigned int i = 0; i<nStream; i++)
{
cufftSafeCall(cufftPlan1d(&plan1[i], nChannel, CUFFT_C2C, dataSteam));
cufftSafeCall(cufftSetStream(plan1[i], stream1[i]));
}
for (unsigned int i = 0; i < nStream; i++)
{
HANDLE_ERROR(cudaMemcpyAsync(dXX + (dataSteam * nChannel + iniValue)*i,
xx + dataSteam * nChannel * i, (dataSteam * nChannel + iniValue)*
sizeof(Complex), cudaMemcpyHostToDevice, stream1[i]));
cudaMakevv(dXX + i *(dataSteam * nChannel + iniValue), dHH, dVV +
(nStream - 1 - i) * dataSteam * nChannel, stream1[i]);
cufftSafeCall((cufftExecC2C(plan1[i], (cufftComplex *)(dVV +
(nStream - 1 - i) * dataSteam * nChannel), (cufftComplex *)(dVV + (nStream - 1 - i) *
dataSteam * nChannel), CUFFT_FORWARD)));//在GPU上执行
HANDLE_ERROR(cudaMemcpyAsync(yy2 + 64 * 9 + (nStream - 1 - i)*dataSteam * nChannel,
dVV + (nStream - 1 - i)*dataSteam * nChannel, dataSteam * nChannel * sizeof(Complex),
cudaMemcpyDeviceToHost, stream1[i]));
}

