社区
Spark
帖子详情
[spark]WordCount问题,输出结果总是不对,求帮忙
晚秋_梦依在
2016-01-07 05:29:33
进入spark-shell,进行测试:输入,
然后执行:
,输出结果总是1,无语,折腾了我好久,已疯,希望大神们帮个忙!!!下面是我的hdfs文件:
,
从最后一图看,单词数那么多,怎么也不是一个啊
...全文
353
3
打赏
收藏
[spark]WordCount问题,输出结果总是不对,求帮忙
进入spark-shell,进行测试:输入, 然后执行:,输出结果总是1,无语,折腾了我好久,已疯,希望大神们帮个忙!!!下面是我的hdfs文件: ,从最后一图看,单词数那么多,怎么也不是一个啊
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
部落酋长
2016-03-09
打赏
举报
回复
你这个语句就是读取这个文件,文件只有一行 textFile就是默认以回车换行符作为默认分割,因此输出值为1 val words = readmeFile.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
晚秋_梦依在
2016-03-06
打赏
举报
回复
如图,计算的是行数,不是单词数
wangbiao1150
2016-01-08
打赏
举报
回复
你好,你这样统计的并不是单词的个数,而是rdd的个数,你需要这样做:val words = readmeFile.flatMap(_.split(" ")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) wordCounts.print() 这样才是统计单词的个数。 可以加入spark技术交流群366436387,共同交流学习。
Spark
大数据处理 之 从
Word
Count
看
Spark
大数据处理的核心机制(2)
在上一篇文章中,我们讲了
Spark
大数据处理的可扩展性和负载均衡,今天要讲的是更为重点的容错处理,这涉及到
Spark
的应用场景和RDD的设计来源。
Spark
的应用场景
Spark
主要针对两种场景: 机器学习,数据挖掘,图应用中常用的迭代算法(每一次迭代对数据执行相似的函数) 交互式数据挖掘工具(用户反复查询一个数据子集)
Spark
在
spark
-submit外,还提供了
spark
-shel...
从
Word
Count
看
Spark
大数据处理的核心机制(2)
本文转自http://mp.weixin.qq.com/s?__biz=MzA5MTcxOTk5Mg==&mid=208059053&idx=3&sn=1157ab5db7bc2783e812e3dc14a0b92e&scene=18#rd,所有权力归原作者所有。 在上一篇文章中,我们讲了
Spark
大数据处理的可扩展性和负载均衡,今天要讲的是更为重点的容错处理,这涉及到
Spark
的应用场
Spark
入门
本篇是介绍
Spark
的入门系列文章,希望能帮你初窥
Spark
的大门。 一、
Spark
概述 1 首先回答什么是
Spark
?
Spark
是一种基于内存的快速,通用,可扩展的大数据计算引擎。 那有的同学可能会问,大数据计算引擎,MapReduce不就是吗?为什么又来个
Spark
? 其中最大的原因还是MapReduce自身的短板导致: 1. 基本运算规则从存储介质中采集数据,然后进行计算,最...
Spark
on Kubernetes:云原生大数据处理实践
在云原生(Cloud Native)浪潮下,企业越来越依赖容器化、自动化的基础设施。传统大数据框架(如
Spark
)的部署方式(Standalone/YARN)逐渐暴露资源利用率低、弹性不足的
问题
。本文聚焦“
Spark
on Kubernetes”这一云原生解决方案,覆盖从概念理解到实战部署的全流程,帮助读者掌握如何用Kubernetes优化
Spark
的大数据处理能力。本文从“为什么需要
Spark
on K8s”入手,用生活化案例解释核心概念;通过流程图和代码示例拆解技术原理;
大数据面试手写题:批处理
Word
Count
的5种实现方式
在大数据领域,
Word
Count
问题
是一个经典的入门级案例,它主要用于统计给定文本中每个单词出现的次数。掌握
Word
Count
的多种实现方式,不仅能加深对大数据处理技术的理解,更是应对大数据面试的必备技能。本文将深入探讨批处理
Word
Count
的5种实现方式,帮助读者在面试和实际工作中更好地运用相关知识。首先,我们会通过一个有趣的故事引入核心概念,然后详细解释批处理、
Word
Count
等核心概念及其关系,并给出相应的文本示意图和Mermaid流程图。
Spark
1,275
社区成员
1,171
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
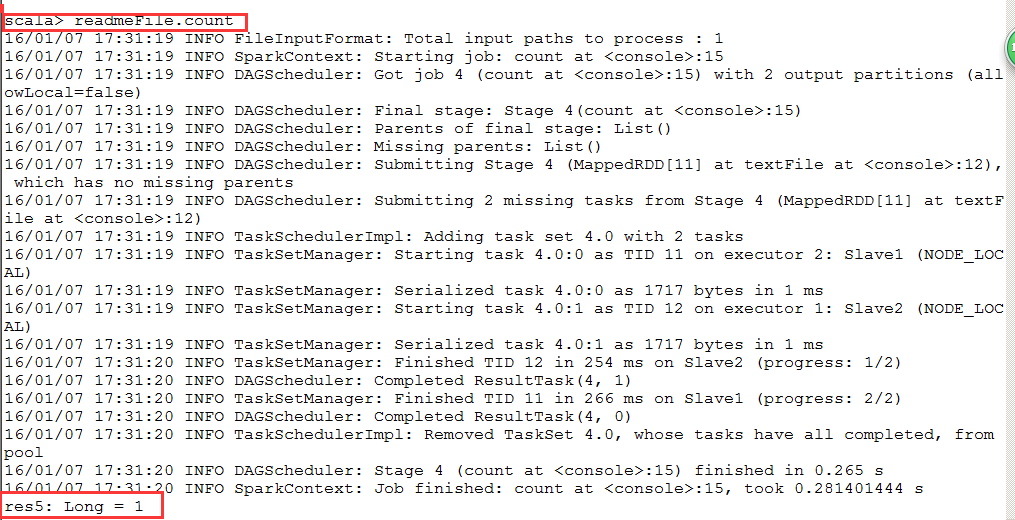 ,输出结果总是1,无语,折腾了我好久,已疯,希望大神们帮个忙!!!下面是我的hdfs文件:
,输出结果总是1,无语,折腾了我好久,已疯,希望大神们帮个忙!!!下面是我的hdfs文件:
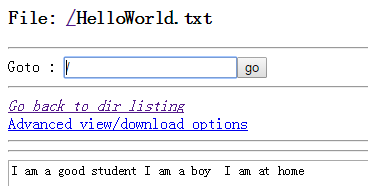 ,从最后一图看,单词数那么多,怎么也不是一个啊
,从最后一图看,单词数那么多,怎么也不是一个啊

