关于spark与cassandra结合使用的问题!!官网案列跑不通!!!!!
直接贴代码,我基本上都是按照官网案列来的!!!如下:分不够,只剩下这么点了 ....望大家帮帮我
maven依赖:
<!-- spark java 先注释 -->

<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector_2.10</artifactId>
<version>1.6.0-M2</version>
</dependency>
<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector-java_2.10</artifactId>
<version>1.6.0-M1</version>
</dependency>
<!-- spark java 结束 -->
<!-- spark core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.1</version>
</dependency>
<!-- spark core 结束 -->
<!-- cassandra驱动 -->
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>3.0.1</version>
</dependency>
<!-- cassandra实体对象映射相关连的包 -->
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-mapping</artifactId>
<version>3.0.1</version>
</dependency>
然后直接就是测试代码了:
/**
* 获取连接
*/
public static JavaSparkContext getConnection() {
// 获取连接方式
SparkConf conf = new SparkConf(true).setAppName("spark and cassandra")
//.set("spark.testing.memory", "2147480000")//分配内存,内存不足512M
.set("spark.cassandra.connection.host", "192.168.1.13");
JavaSparkContext sc = new JavaSparkContext("spark://192.168.1.13:7077", "SparkOptionCassandra1", conf);
System.out.println(sc.master() + " : " + sc.appName());
return sc;
}
/**
* spark读取cassandra表数据 22222
*/
public static void getDataFromCassandra() {
JavaSparkContext sc = getConnection();
try {
JavaRDD<String> cassandraRowsRDD = javaFunctions(sc).cassandraTable("xmmsg", "people")
.map(new Function<CassandraRow, String>() {
public String call(CassandraRow cassandraRow) throws Exception {
return cassandraRow.toString();
}
});
System.out.println("Data as CassandraRows: \n" + StringUtils.join("\n", cassandraRowsRDD.collect()));
} catch (Exception e) {
e.printStackTrace();
}finally{
sc.stop();
sc.close();
}
}
然后报错信息:
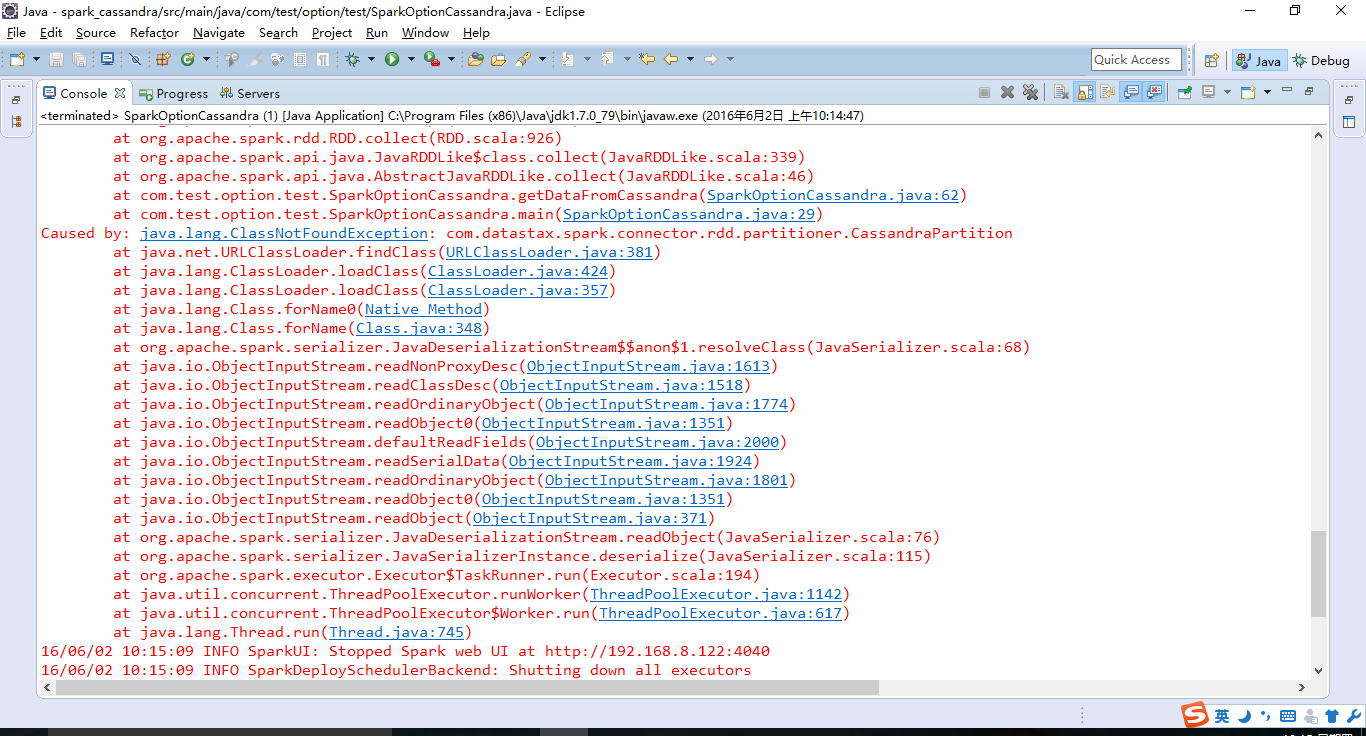
然后保存也是:哎
/**
* 持久化数据到cassandra数据库
*/
public static void savePerson() {
try {
JavaSparkContext sc = getConnection();
List<Person> people = Arrays.asList(
Person.newInstance(1, "John", new Date()),
Person.newInstance(2, "Anna", new Date()),
Person.newInstance(3, "Andrew", new Date())
);
JavaRDD<Person> rdd = sc.parallelize(people);
javaFunctions(rdd).writerBuilder("xmmsg", "people", mapToRow(Person.class)).saveToCassandra();
} catch (Exception e) {
e.printStackTrace();
}
}
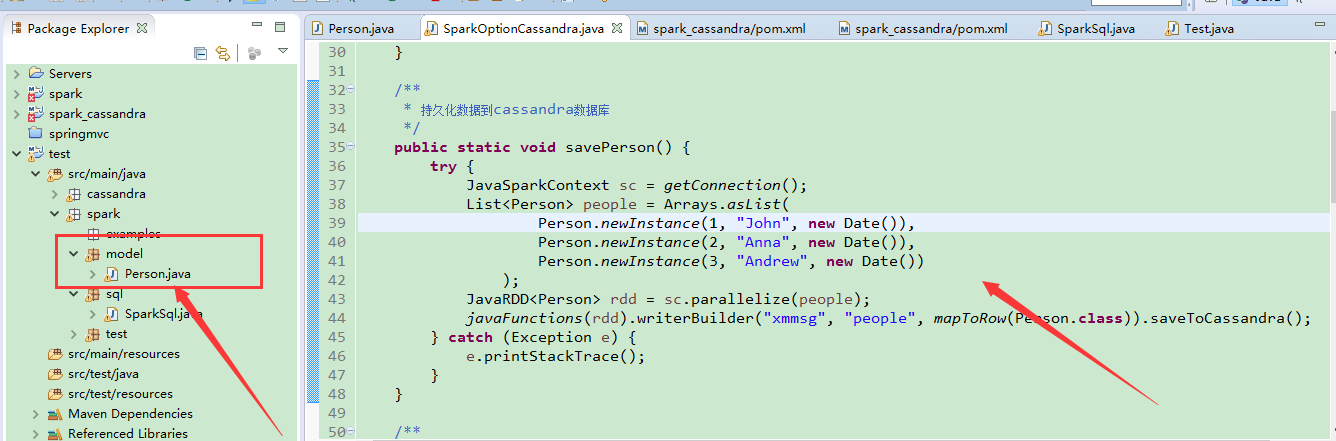
报错信息:
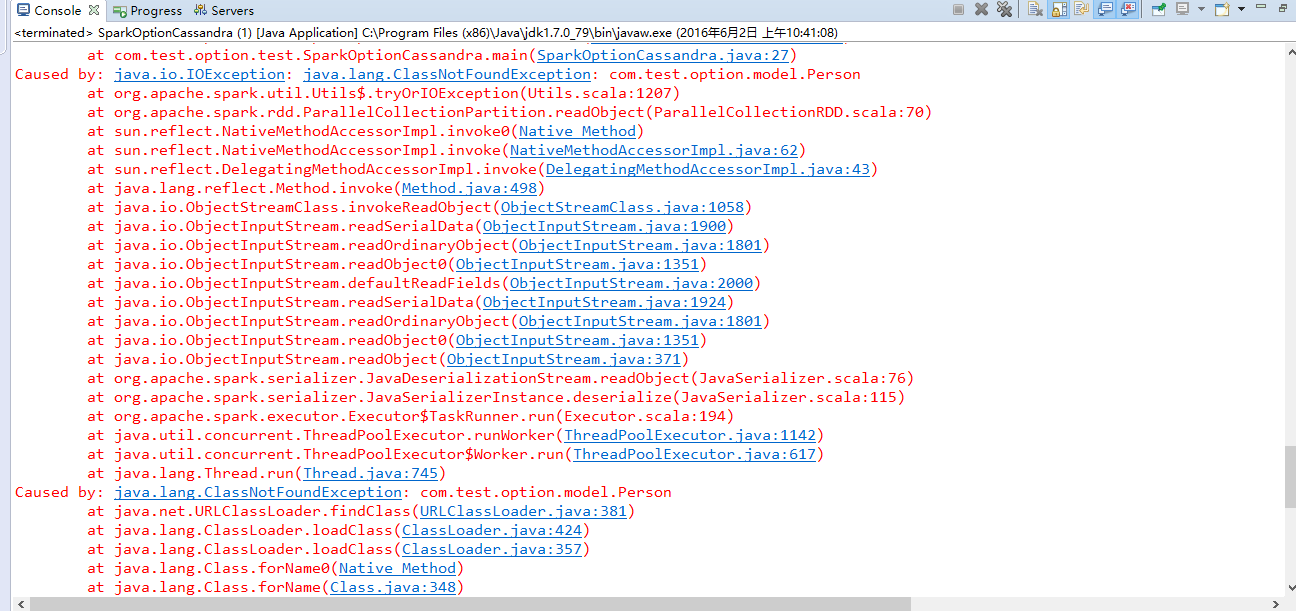 请大神帮帮我,谢谢啦!!!!!!!
请大神帮帮我,谢谢啦!!!!!!!
还有一个关于sparksql的问题:
public static void writeResouces(){
JavaSparkContext sc=getConnection("first","local");
SQLContext sqlContext = new SQLContext(sc);
DataFrame df = sqlContext.read().format("json").load("c://test//people.json");
//不知道为什么输出的文件居然是文件夹?win和linux区别?
df.select("name", "age").write().format("parquet").save("c://test/namesAndAges2.parquet");
//可以这么 查询
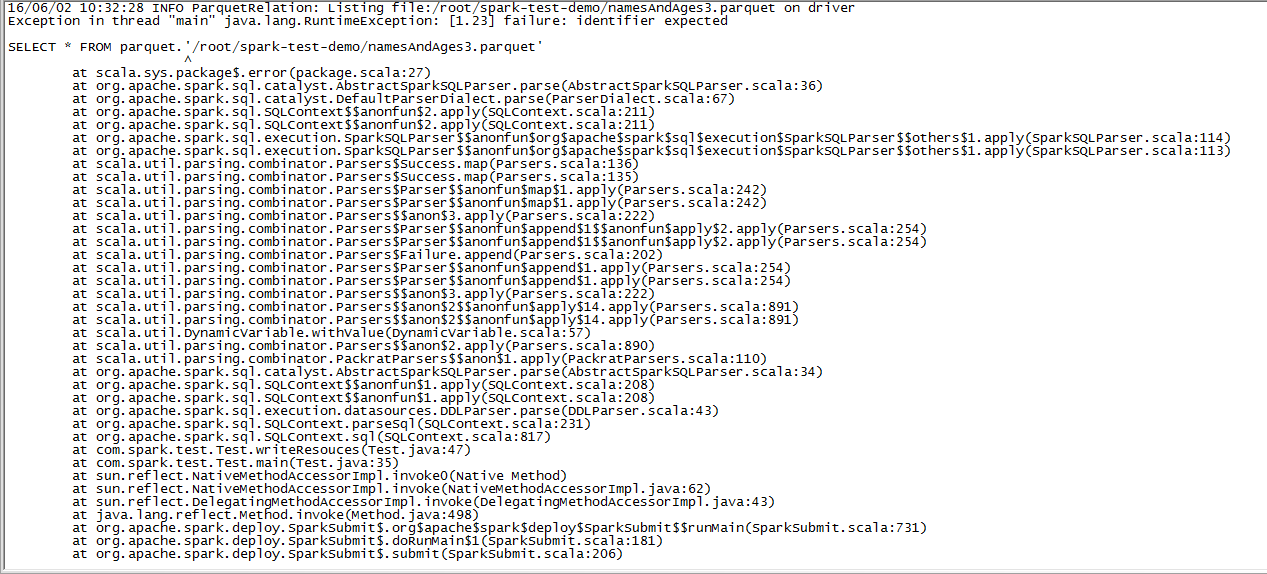
DataFrame df2 = sqlContext.sql("SELECT * FROM parquet.`c://test/namesAndAges2.parquet");
System.out.println(df2.count());
}
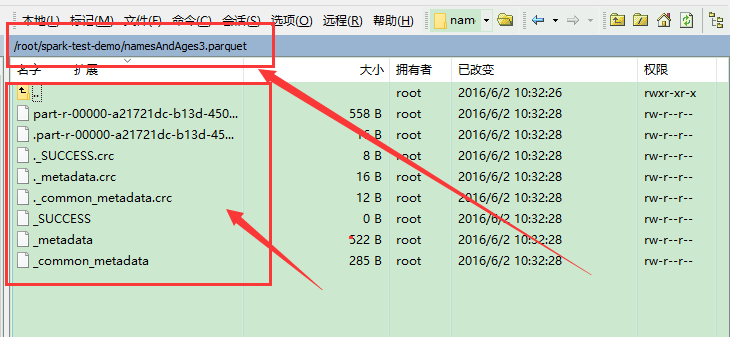
为什么我在win本地生成是namesAndAges2.parquet文件夹呢,里面啥东西都没有,
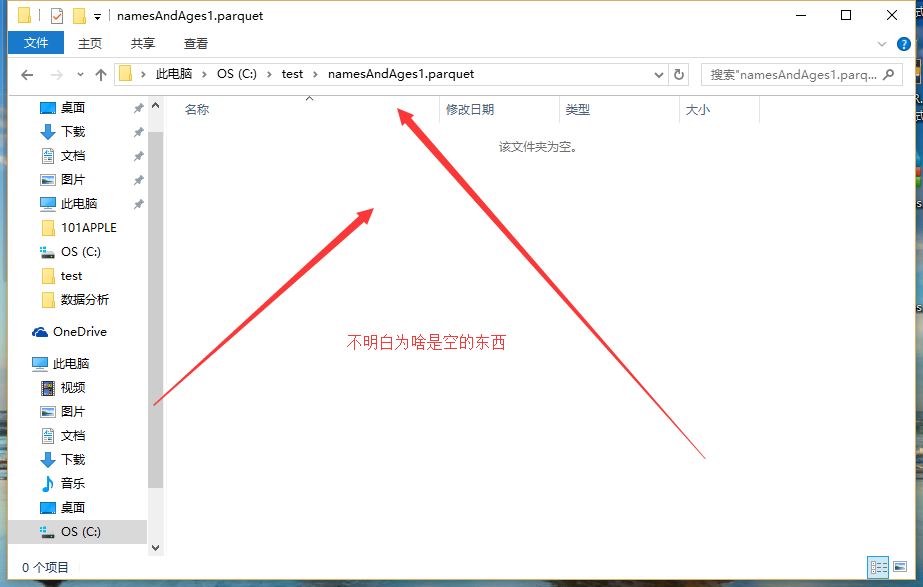 在linux上面能生成文件,但是没法读取!!
在linux上面能生成文件,但是没法读取!!




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

