社区
机器视觉
帖子详情
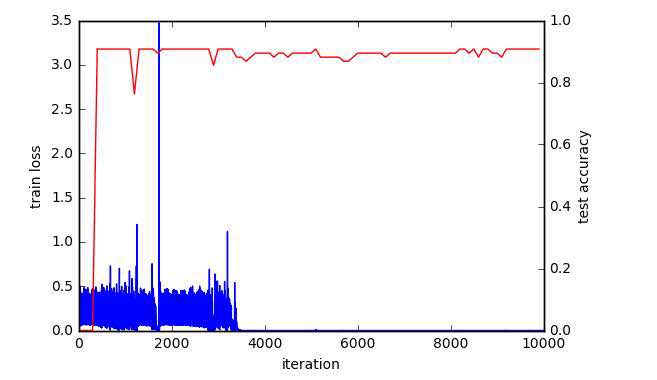
googlenet深度学习新人,训练的loss值突然变为0后一直变化,请问会是什么原因
nanoshikitty
2016-12-29 03:48:28
一共500张图片,348张训练,152张验证,请问这是梯度消失的情况吗,下一步应该怎么做
...全文
5694
2
打赏
收藏
googlenet深度学习新人,训练的loss值突然变为0后一直变化,请问会是什么原因
一共500张图片,348张训练,152张验证,请问这是梯度消失的情况吗,下一步应该怎么做
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
2 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
yunz619
2017-09-11
打赏
举报
回复
目测是overfitting 已经完美分类train set了 个人认为几个可能的解决办法 1.加个dropout 2. 从数据集中再分出来个validation set(或者用之前的train set做cross validation),看着validation set的loss做early stopping。
程序狗觅食中
2017-01-17
打赏
举报
回复
训练数据太小,overfitting了
复现基于改进扩散模型的高海拔地区新能源高波动出力场景生成方法(Python代码实现)
内容概要:本文提出了一种基于改进扩散模型的高海拔地区新能源高波动出力场景生成方法,并提供了完整的Python代码实现。该方法针对高海拔地区风能、光伏等新能源出力波动剧烈、不确定性高的特点,通过优化扩散模型的结构与
训练
策略,有效捕捉历史数据的概率分布特征与时序相关性,从而生成高质量、多样化的出力场景。文中详细阐述了模型的数学推导、网络架构设计、损失函数优化及采样算法改进,并通过实验证明其在拟合精度、场景多样性与稳定性方面优于传统生成模型,为电力系统在高比例新能源接入下的规划、调度与风险评估提供了可靠的场景输入支持。; 适合人群:具备一定Python编程能力和机器学习基础,从事新能源发电预测、电力系统分析、智能优化、场景生成等方向研究的科研人员、高校研究生及工程技术人员。; 使用场景及目标:①用于高海拔地区风电、光伏出力的不确定性建模与多场景生成;②支撑含高渗透率新能源的电力系统随机优化调度、鲁棒决策与风险评估;③为相关学术研究、论文复现与算法改进提供可运行的技术方案与代码基础; 阅读建议:建议读者结合所提供的完整资源(代码、数据集、说明文档)进行实践操作,重点关注扩散模型的前向加噪与反向去噪过程的设计细节,以及如何将其适配于新能源时序数据的生成任务,通过参数调优与对比实验深入理解模型的生成机制与性能边界。
复现计及风电不确定性的电力系统黑启动恢复模型(Matlab代码实现)
内容概要:本文档提供了多个电力系统及相关领域的Matlab和Python代码实现资源,重点聚焦于“计及风电不确定性的电力系统黑启动恢复模型”的复现研究。该模型针对高比例新能源接入背景下,风电出力波动性和不确定性对电力系统恢复过程的影响,构建了考虑不确定因素的黑启动优化恢复框架,并通过Matlab编程实现仿真验证,旨在提升新型电力系统在故障后的快速、可靠恢复能力。; 适合人群:具备一定电力系统基础知识和Matlab编程能力的研究生、科研人员及从事电力系统规划与运行工作的技术人员。; 使用场景及目标:①用于学习和复现含风电的电力系统黑启动恢复策略;②开展考虑新能源不确定性的电力系统恢复力(resilience)研究;③作为相关课题的算法开发与仿真验证参考; 阅读建议:建议结合电力系统恢复、随机优化或鲁棒优化等相关理论文献,深入理解模型构建逻辑,并利用提供的代码进行调试与案例分析,进一步拓展至其他不确定性场景或系统结构的研究。
【静态约束法】配电网电动汽车接入容量评估研究(Matlab代码实现)
内容概要:本文围绕基于静态约束法的配电网电动汽车接入容量评估展开研究,提出了一种在新型电力系统背景下评估主动配电网对电动汽车承载能力的方法。研究通过构建数学模型,结合潮流计算与关键约束条件(如电压越限、线路过载等),量化分析配电网可承受的最大电动汽车充电负荷容量,旨在识别规模化电动汽车接入带来的潜在运行风险,并为电网规划与运行提供科学依据。文中配套提供了完整的Matlab代码实现,便于仿真验证与结果复现。此外,该研究与分布式光伏承载力评估、电动汽车可调能力分析等方向形成技术联动,展现了多主题协同的研究体系。; 适合人群:具备电力系统分析基础理论知识及Matlab编程能力的高校研究生、科研机构研究人员,以及从事新能源并网、智能配电网规划与运行等相关领域的工程技术人员。; 使用场景及目标:①用于学术研究中的模型复现与论文撰写支撑;②评估实际配电网中电动汽车大规模接入的可行性与安全边界,指导充电基础设施布局;③作为高校教学案例,帮助学生深入理解电网承载力评估的核心原理、建模方法与仿真技术; 阅读建议:建议结合文中提及的相关研究方向(如二阶锥规划、多面体聚合方法等)进行对比学习,充分利用所提供的Matlab代码与网盘资料开展仿真实验,重点关注约束条件的设定逻辑与潮流计算模块的实现细节,以深化对评估模型机理与工程应用价
值
的理解。
考虑隐私保护的分布式联邦学习电力负荷预测研究(Python代码实现)
内容概要:本文围绕“考虑隐私保护的分布式联邦学习电力负荷预测研究”展开,提出了一种基于Python实现的联邦学习框架,旨在解决居民或行业电力负荷预测中用户电表数据隐私泄露的风险。该研究通过构建分布式机器学习模型,使各参与方在不共享原始数据的前提下协同
训练
全局模型,有效实现了数据“可用不可见”。文中详细阐述了联邦学习的整体架构设计、本地模型
训练
流程、参数加密传输与安全聚合机制,并结合差分隐私等技术进一步增强系统的隐私保护能力。同时,研究利用真实电力负荷数据集进行了实验验证,展示了方法在预测精度与隐私保障之间的良好平衡,并提供了完整的代码实例与复现指南,便于后续研究与应用拓展。; 适合人群:具备一定机器学习基础和电力系统背景知识,从事智慧能源、隐私计算或人工智能相关方向研究的研究生、科研人员及工程技术人员。; 使用场景及目标:① 实现跨区域、跨主体的电力负荷协同预测,打破数据孤岛;② 在确保用户用电数据隐私安全的前提下提升负荷预测准确性;③ 推动联邦学习在智能电网、需求响应、虚拟电厂等场景中的实际部署与应用。; 阅读建议:建议结合文中提供的Python代码与网盘资料进行动手实践,重点关注联邦学习的通信轮次设计、模型聚合算法(如FedAvg)的实现细节以及差分隐私噪声添加策略,深入理解其对模型性能与隐私强度的影响,为进一步优化与创新奠定基础。
【汽车制造质量检测】基于VDA 19.1-2026 标准的技术清洁度颗粒污染检验方法与应用
VDA_Band_19.1_3rd edition_2026 English Inspection of Technical Cleanliness 内容概要:本文档为德国汽车工业协
会
(VDA)发布的第三版《技术清洁度检验:功能相关汽车部件的颗粒污染检测》(VDA 19.1),系统规范了汽车行业中零部件技术清洁度的检测方法与流程。文件涵盖从取样、提取、过滤到分析的全流程标准化操作,重点更新了干法提取(如 Stamp Test 和刷吸法)、小于50µm颗粒的检测、光学子系统和SEM/EDX标准分析方法,并引入统一材料分类体系以提升结果可比性。同时明确了“标准分析”与“自由检验”的区别,前者用于高兼容性检测,后者允许客户与供应商协商定制参数。文档还强化了对非可测组件的技术清洁保障、测量不确定度评估及方法验证的要求,并提供了多个实际案例支持应用落地。; 适合人群:适用于汽车制造业中从事质量控制、工艺开发、供应商管理及相关检测实验室的技术人员和管理人员,尤其适合具备一定质量管理或洁净度检测基础的专业人员。; 使用场景及目标:①用于制定和执行零部件清洁度检测标准;②指导 incoming/outgoing 检验及生产过程监控;③支持失效分析与质量改进项目;④作为企业内部审核和技术交流的依据; 阅读建议:建议结合VDA 19.2及其他相关标准配套使用,重点关注各章节中的起始参数设定、方法选择逻辑及附录中的检查表示例,在实际操作中同步开展方法验证与人员培训,确保检测结果的有效性和可追溯性。
机器视觉
4,511
社区成员
15,351
社区内容
发帖
与我相关
我的任务
机器视觉
图形图像/机器视觉
复制链接
扫一扫
分享
社区描述
图形图像/机器视觉
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享