

17,134
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享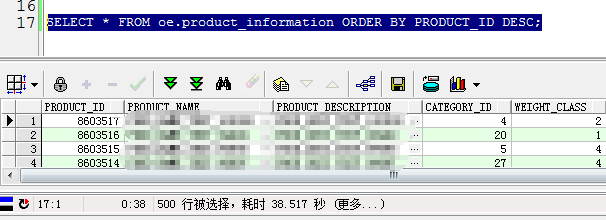

 谢谢版主,能不能帮忙看下上面的问题
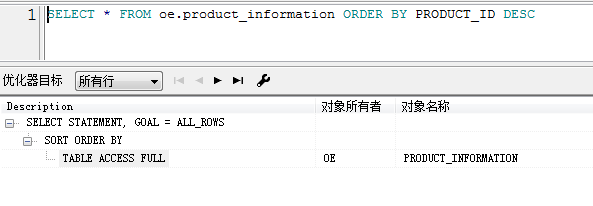
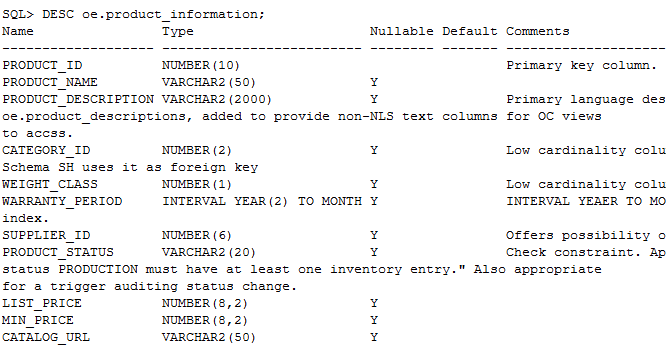
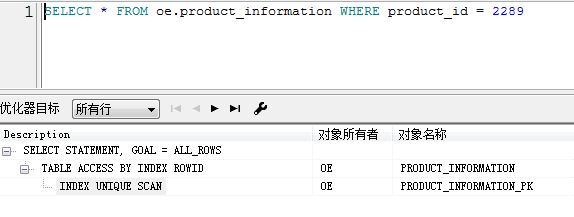
但是我发现一个问题
谢谢版主,能不能帮忙看下上面的问题
但是我发现一个问题
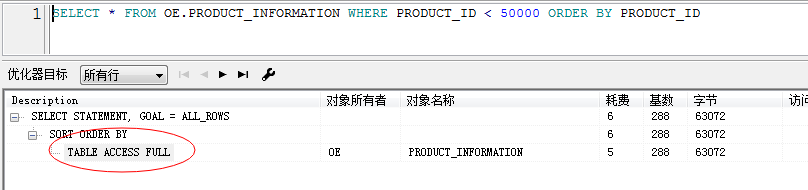
SELECT * FROM oe.product_information WHERE product_id < 50000 ORDER BY PRODUCT_ID DESC--大概有4万多
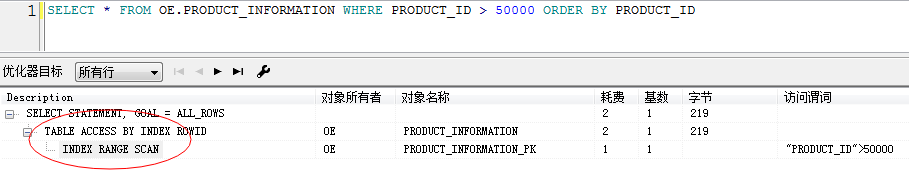
SELECT * FROM oe.product_information WHERE product_id > 50000 ORDER BY PRODUCT_ID DESC ---大概有800万多数据


 但是我发现一个问题
但是我发现一个问题
SELECT * FROM oe.product_information WHERE product_id < 50000 ORDER BY PRODUCT_ID DESC--大概有4万多
SELECT * FROM oe.product_information WHERE product_id > 50000 ORDER BY PRODUCT_ID DESC ---大概有800万多数据

 帮顶!
帮顶!


