我用windows10和Alexnet,分类鸟和狗两种图片,alexnet是系统models下自带的。
accuracy总是 0.5 ,分类失败,下面我把过程都贴出来了,请教大家!
1, 训练用的图片
20张。
bird\21.jpg 0
bird\22.jpg 0
bird\23.jpg 0
bird\24.jpg 0
bird\25.jpg 0
bird\26.jpg 0
bird\27.jpg 0
bird\28.jpg 0
bird\29.jpg 0
bird\30.jpg 0
dog\31.jpg 1
dog\32.jpg 1
dog\33.jpg 1
dog\34.jpg 1
dog\35.jpg 1
dog\36.jpg 1
dog\37.jpg 1
dog\38.jpg 1
dog\39.jpg 1
dog\40.jpg 1
使用bat命令如下:
SET GLOG_logtostderr=1
D:\caffe\caffe-master\Build\x64\Debug\convert_imageset.exe -resize_width=200 --resize_height=200 D:\caffe\caffe-master\data\mine\train\ D:\caffe\caffe-master\data\mine\train.txt D:\caffe\caffe-master\data\mine\trainlmdb
pause
生成 daanda.mdb 和 lock.mdb.
2, 验证图片
10张。
6.jpg 0
7.jpg 0
8.jpg 0
9.jpg 0
10.jpg 0
1.jpg 1
2.jpg 1
3.jpg 1
4.jpg 1
5.jpg 1
使用bat文件:
SET GLOG_logtostderr=1
D:\caffe\caffe-master\Build\x64\Debug\convert_imageset.exe -resize_width=200 -resize_height=200 D:\caffe\caffe-master\data\mine\val\ D:\caffe\caffe-master\data\mine\val.txt D:\caffe\caffe-master\data\mine\vallmdb
pause
产生data.mdb 和 lock.mdb.
3, image_mean.binaryproto
使用bat:
SET GLOG_logtostderr=1
D:\caffe\caffe-master\Build\x64\Debug\compute_image_mean.exe D:\caffe\caffe-master\data\mine\trainlmdb\ D:\caffe\caffe-master\data\mine\image_mean.binaryproto
pause
成功产生 image_mean.binaryproto。
4,train-val.prototxt配置
使用alexnet网络,将最后fc8的num_output改为2,因为我只有两类,crop_size改为200,因为在前面的操作中图片已经resize200。
name: "AlexNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 200
mean_file: "D:/caffe/caffe-master/data/mine/image_mean.binaryproto"
}
data_param {
source: "D:/caffe/caffe-master/data/mine/trainlmdb"
batch_size: 2
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 200
mean_file: "D:/caffe/caffe-master/data/mine/image_mean.binaryproto"
}
data_param {
source: "D:/caffe/caffe-master/data/mine/vallmdb"
batch_size: 2
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "norm1"
type: "LRN"
bottom: "conv1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "norm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "norm2"
type: "LRN"
bottom: "conv2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "norm2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1024
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1024
weight_filler {
type: "gaussian"
std: 0.005
}
bias_filler {
type: "constant"
value: 0.1
}
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}
5, solver.prototxt配置
也是系统自带的solver.prototxt,将test_iter改为5,和train-val.prototxt的batch_size值2相乘等于10,即为验证图片总数。
net: "D:/caffe/caffe-master/data/mine/train-val/train_val.prototxt"
test_iter: 5
test_interval: 100
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 60
max_iter: 4000
momentum: 0.9
weight_decay: 0.004
snapshot: 4000
snapshot_prefix: "D:/caffe/caffe-master/data/mine/outcome/"
solver_mode: GPU
6,运行
run.bat
运行成功,产生两个文件 _iter_4000.caffemodel 和 _iter_4000.solverstate,但accuracy为0.5,改改试试几次,也有0.6的。
SET GLOG_logtostderr=1
D:\caffe\caffe-master\Build\x64\Debug\caffe.exe train --solver=D:\caffe\caffe-master\data\mine\train-val\solver.prototxt
pause
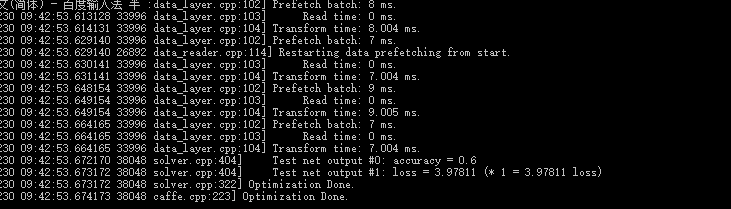
I1230 09:42:53.672170 38048 solver.cpp:404] Test net output #0: accuracy = 0.6
I1230 09:42:53.673172 38048 solver.cpp:404] Test net output #1: loss = 3.97811 (* 1 = 3.97811 loss)
I1230 09:42:53.673172 38048 solver.cpp:322] Optimization Done.
I1230 09:42:53.674173 38048 caffe.cpp:223] Optimization Done.
7 分类
classification.bat
使用classification.exe进行分类,也是没有成功。
use bat:
SET GLOG_logtostderr=1
D:\caffe\caffe-master\Build\x64\Debug\classification.exe D:\caffe\caffe-master\data\mine\train-val\deploy.prototxt D:\caffe\caffe-master\data\mine\outcome\_iter_3000.caffemodel D:\caffe\caffe-master\data\mine\image_mean.binaryproto D:\caffe\caffe-master\data\mine\labels.txt D:\caffe\caffe-master\data\mine\train-val\222.jpg
pause
labels文件包括:
0 bird
1 dog
222.jpg是一个鸟的图片。
deploy.prototxt主要修改了dim,长宽修改为200,dim第一个参数改为1,num_output修改为2。
name: "AlexNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 3 dim: 200 dim: 200 } }
}
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
因字数限制中间的省略了,按照系统默认的
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 2
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}
结果:

F1230 09:47:45.788908 28692 net.cpp:766] Cannot copy param 0 weights from layer
'fc6'; shape mismatch. Source param shape is 1024 9216 (9437184); target param
shape is 4096 9216 (37748736). To learn this layer's parameters from scratch rather than copying from a saved net, rename the layer.
*** Check failure stack trace: **


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





