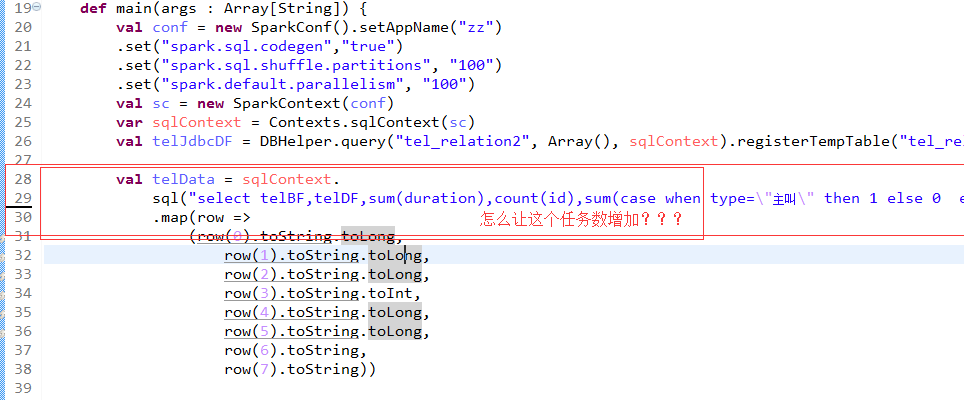

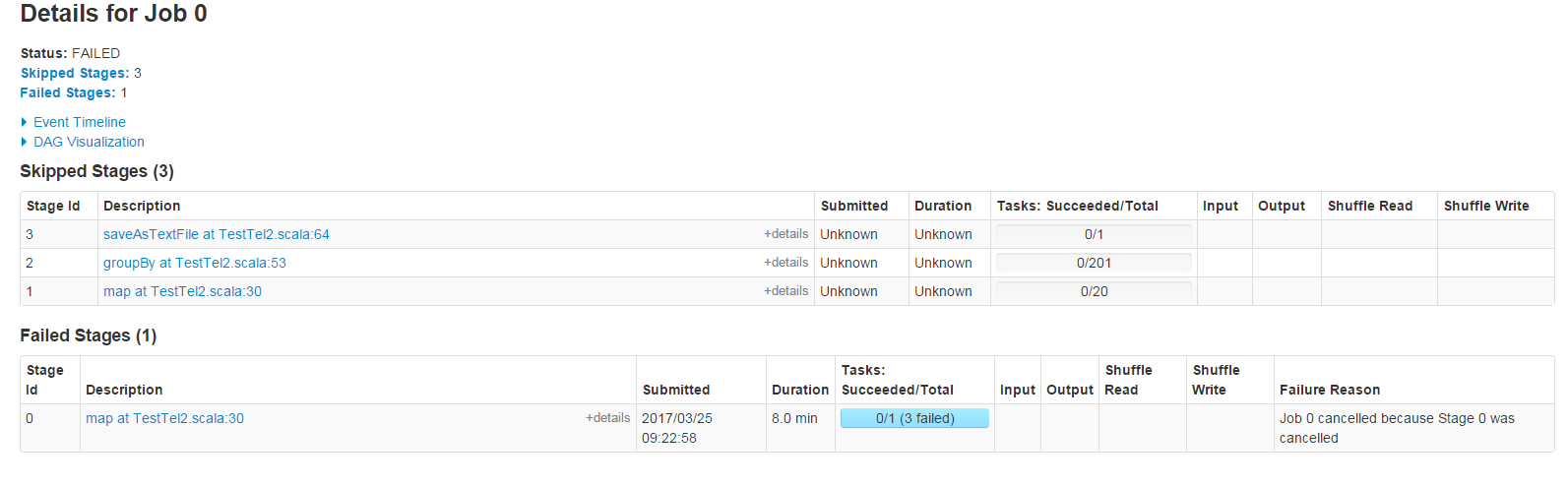
1000万的数据没问题,4000千万就会报这个错 ,我推测是内存不足导致的,所以我想把这里的任务数增加些,可是怎么设置参数都是1
sql内容 如 下
select telBF,telDF,sum(duration),count(id),sum(case when type=\"主叫\" then 1 else 0 end),sum(case when type=\"被叫\" then 1 else 0 end) ,max(tel_date),min(tel_date) from tel_rel group by telBF,telDF
或者还有其他方案吗?求大神们帮帮忙,困扰我好久了这个问题

这个是1000万数据任务成功执行的截图




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


