

17,136
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享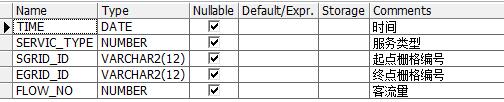

with t as
(select *
from (select a.*, b.AREA_ID SGRID_ZONE, c.AREA_ID EGRID_ZONE
from (select a.*,
CASE
WHEN TO_CHAR(a.TIME, 'HH24:MI') BETWEEN '08:00' and
'10:00' THEN
1
WHEN TO_CHAR(a.TIME, 'HH24:MI') BETWEEN '17:00' and
'20:00' THEN
2
ELSE
0
END as unit
from TSRT_TAXI_hourdemand a
where a.TIME >=
to_date('2017-03-26 00', 'yyyy-mm-dd HH24:mi')
and a.TIME <=
to_date('2017-03-27 23', 'yyyy-mm-dd HH24:mi')) a
left join TSRT_TAXI_TRAFFICZONE b
on b.GRID_ID = a.SGRID_ID
left join TSRT_TAXI_TRAFFICZONE c
on c.GRID_ID = a.EGRID_ID)
WHERE SGRID_ZONE IS NOT NULL
AND EGRID_ZONE IS NOT NULL
AND SGRID_ZONE != EGRID_ZONE
)
select b.AREA_NAME SGRID_NAME,
b.LONGITUDE SGRID_LON,
b.LATITUDE SGRID_LAT,
c.AREA_NAME EGRID_NAME,
c.LONGITUDE EGRID_LON,
c.LATITUDE EGRID_LAT,
FLOW_NO,
rn
from (select b.SGRID_ZONE, b.EGRID_ZONE, b.FLOW_NO, b.rn as rn
from (select a.*,
row_number() over(partition by a.SGRID_ZONE order by a.FLOW_NO DESC) rn
from (select t.SGRID_ZONE,
t.EGRID_ZONE,
sum(t.FLOW_NO) as FLOW_NO
from t
where t.SGRID_ZONE in
(select b.SGRID_ZONE
from (SELECT t.SGRID_ZONE, SUM(T.FLOW_NO)
FROM t
group by SGRID_ZONE
ORDER BY SUM(T.FLOW_NO) DESC) b
where ROWNUM <= 10)
group by t.SGRID_ZONE, t.EGRID_ZONE) a) b
where b.rn < 10) a
left join ttcb_trans_area b
on b.ID = a.SGRID_ZONE
left join ttcb_trans_area c
on c.ID = a.EGRID_ZONE;





