环境asianux4 sp4+jdk1.8+hadoop2.8.1+hive2.3.0+spark2.2.0:
hive on spark首次搭建使用,执行insert语句一直pending,会是什么问题呢?
hive> create table aa (a char(4),b char(4));
OK
Time taken: 0.789 seconds
hive> desc aa;
OK
a char(4)
b char(4)
Time taken: 0.1 seconds, Fetched: 2 row(s)
hive> insert into aa values (1,2);
Query ID = study_20170805093834_45feb19d-b40d-41cf-9028-b3c63b73d871
Total jobs = 1
Launching Job 1 out of 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Spark Job = 4944aec7-5f34-47fa-83de-a240f0e59761
Query Hive on Spark job[0] stages: [0]
Status: Running (Hive on Spark job[0])
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-0 0 PENDING 1 0 0 1 0
--------------------------------------------------------------------------------------
STAGES: 00/01 [>>--------------------------] 0% ELAPSED TIME: 1037.34 s
--------------------------------------------------------------------------------------
日志情况:
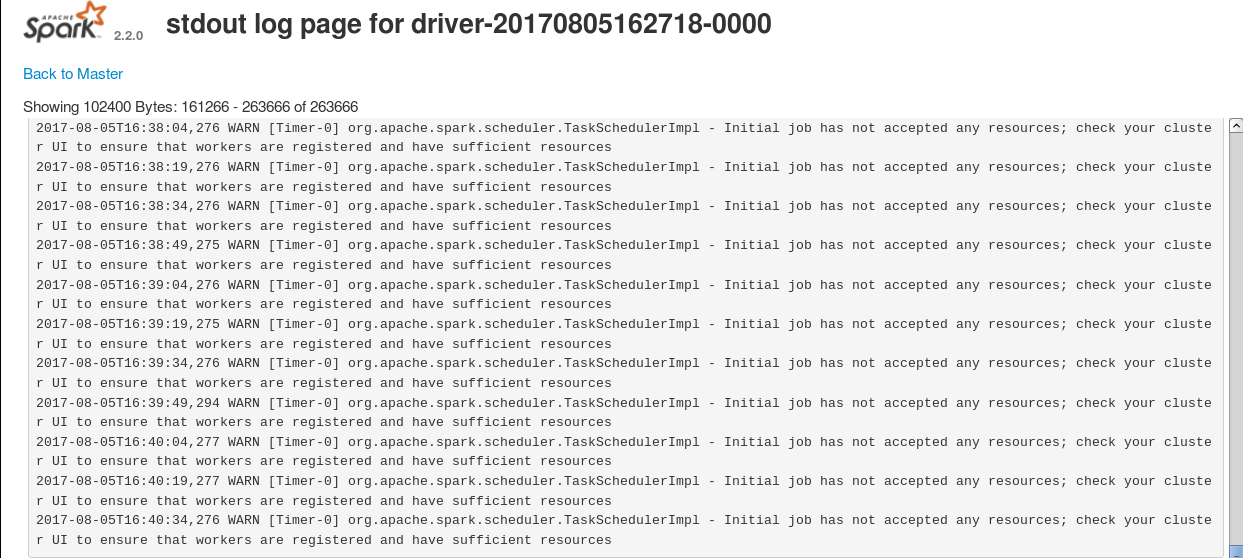
hive.log:
2017-08-05T09:40:25,285 INFO [main] SessionState: 2017-08-05 09:40:25,284 Stage-0_0: 0/1
2017-08-05T09:40:28,328 INFO [main] SessionState: 2017-08-05 09:40:28,326 Stage-0_0: 0/1
2017-08-05T09:40:31,374 INFO [main] SessionState: 2017-08-05 09:40:31,374 Stage-0_0: 0/1
2017-08-05T09:40:34,433 INFO [main] SessionState: 2017-08-05 09:40:34,432 Stage-0_0: 0/1
2017-08-05T09:40:37,459 INFO [main] SessionState: 2017-08-05 09:40:37,458 Stage-0_0: 0/1
2017-08-05T09:40:40,510 INFO [main] SessionState: 2017-08-05 09:40:40,509 Stage-0_0: 0/1
2017-08-05T09:40:43,544 INFO [main] SessionState: 2017-08-05 09:40:43,534 Stage-0_0: 0/1
2017-08-05T09:40:46,584 INFO [main] SessionState: 2017-08-05 09:40:46,582 Stage-0_0: 0/1
2017-08-05T09:40:49,606 INFO [main] SessionState: 2017-08-05 09:40:49,605 Stage-0_0: 0/1
2017-08-05T09:40:52,649 INFO [main] SessionState: 2017-08-05 09:40:52,649 Stage-0_0: 0/1
2017-08-05T09:40:55,690 INFO [main] SessionState: 2017-08-05 09:40:55,683 Stage-0_0: 0/1
2017-08-05T09:40:58,728 INFO [main] SessionState: 2017-08-05 09:40:58,723 Stage-0_0: 0/1
2017-08-05T09:41:01,762 INFO [main] SessionState: 2017-08-05 09:41:01,760 Stage-0_0: 0/1
2017-08-05T09:41:04,797 INFO [main] SessionState: 2017-08-05 09:41:04,797 Stage-0_0: 0/1
2017-08-05T09:41:07,829 INFO [main] SessionState: 2017-08-05 09:41:07,828 Stage-0_0: 0/1
2017-08-05T09:41:10,854 INFO [main] SessionState: 2017-08-05 09:41:10,853 Stage-0_0: 0/1
spark日志:
spark-study-org.apache.spark.deploy.master.Master-1-master.out:
17/08/05 09:38:54 INFO master.Master: Driver submitted org.apache.spark.deploy.worker.DriverWrapper
17/08/05 09:38:54 INFO master.Master: Launching driver driver-20170805093854-0004 on worker worker-20170805071939-192.168.144.141-7078
17/08/05 09:39:00 INFO master.Master: 192.168.144.141:45920 got disassociated, removing it.
17/08/05 09:39:00 INFO master.Master: 192.168.144.141:45922 got disassociated, removing it.
17/08/05 09:39:00 INFO master.Master: 192.168.144.141:59926 got disassociated, removing it.
17/08/05 09:39:03 INFO master.Master: Registering app Hive on Spark
17/08/05 09:39:03 INFO master.Master: Registered app Hive on Spark with ID app-20170805093903-0004
spark-env.sh:
export JAVA_HOME=/usr/java
export SCALA_HOME=/usr/local/scala-2.11.8
export HADOOP_HOME=/home/study/hadoop-2.8.1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/home/study/spark
export SPARK_LAUNCH_WITH_SCALA=0
export SPARK_WORKER_MEMORY=1g
export SPARK_DRIVER_MEMORY=1g
export SPARK_MASTER_IP=master
export SPARK_LIBRARY_PATH=$SPARK_HOME/jars
export SPARK_MASTER_WEBUI_PORT=18080
export SPARK_WORKER_DIR=$SPARK_HOME/work
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_PORT=7078
export SPARK_LOG_DIR=$SPARK_HOME/log
export SPARK_PID_DIR=$SPARK_HOME/run
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
spark-defaults.conf:
spark.master yarn-cluster
spark.home /home/study/spark
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/spark-log
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.executor.memory 1g
spark.driver.memory 1g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
yarn-site.conf:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
hive-site.conf:
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<property>
<name>hive.enable.spark.execution.engine</name>
<value>true</value>
</property>
<property>
<name>spark.home</name>
<value>/home/study/spark</value>
</property>
<property>
<name>spark.master</name>
<value>spark://master:7077</value>
</property>
<property>
<name>spark.enentLog.enabled</name>
<value>true</value>
</property>
<property>
<name>spark.serializer</name>
<value>org.apache.spark.serializer.KryoSerializer</value>
</property>
<property>
<name>spark.executor.memory</name>
<value>1g</value>
</property>
<property>
<name>spark.driver.memory</name>
<value>1g</value>
</property>
<property>
<name>spark.executor.extraJavaOptions</name>
<value>-XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"</value>
</property>
<property>
<name>spark.yarn.jars</name>
<value>hdfs://master:9000/usr/hive/spark-jars/*</value>
</property>



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

