社区
Spark
帖子详情
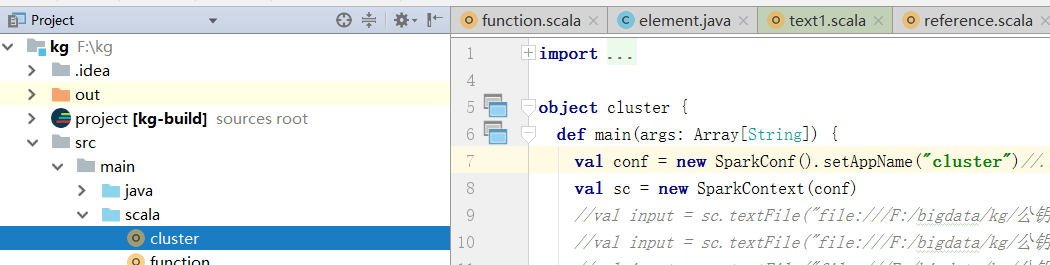
spark集群启动之后,spark-submit提交任务,主类找不到
elan3906
2017-08-23 10:09:39
如题。我在远程部署了spark集群。启动spark之后,想submit提交上传的jar包。报错:java.lang.ClassNotFoundException: cluster。我的主类名是:cluster
...全文
4310
6
打赏
收藏
spark集群启动之后,spark-submit提交任务,主类找不到
如题。我在远程部署了spark集群。启动spark之后,想submit提交上传的jar包。报错:java.lang.ClassNotFoundException: cluster。我的主类名是:cluster
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
6 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
RivenDong
2019-09-08
打赏
举报
回复
你可以通过.setJars直接提交到远程集群,非常方便调试。
PasPerCon
2019-04-02
打赏
举报
回复
你说的:在打包的时候Name后面填的要跟submit的参数class一样,是什么意思?您打包的方式是命令打包还是用Artifact打包?我也遇到了同样的问题,可以详细说一下吗?谢谢!!!
elan3906
2017-08-27
打赏
举报
回复
搞出来了。在打包的时候Name后面填的要跟submit的参数class一样。
LinkSe7en
2017-08-23
打赏
举报
回复
你确定你main方法类名是cluster,而不是像org.mortbay.jetty.Main这样的?
赵4老师
2017-08-23
打赏
举报
回复
JAVA_HOME或CLASSPATH环境变量没设置好?
elan3906
2017-08-23
打赏
举报
回复
master那边其它情况是这样。/etc/profile
spark-env.sh
开发环境IDEA是按照网上方法打jar包的
Spark
Submit
任务
提交
流程
1,简介 在上一篇博客中,我们详细介绍了
Spark
Standalone模式下
集群
的
启动
流程。在
Spark
集群
启动
后,我们要想在
集群
上运行我们自己编写的程序,该如何做呢?本篇博客就主要介绍
Spark
Submit
提交
任务
的流程。 2,
Spark
任务
的
提交
我们可以从
spark
的官网看到,
spark
-
submit
的
提交
格式如下: ./bin/
spark
-
submit
–class –ma...
Spark
之
Spark
任务
的
提交
方式【
Spark
-shell、
Spark
-
submit
】
spark
-shell1、概述2、
启动
1、概述 \quad \quad
Spark
-shell 是
Spark
给我们提供的交互式命令窗口(类似于 Scala 的 REPL) 2、
启动
直接
启动
bin目录下的
spark
-shell: ./
spark
-shell <1>直接使用 ./
spark
-shell 表示使用local 模式
启动
,在本机
启动
一个
Spark
Submit
进程 <2>还可指定参数 --master,如:
spark
-shell --master local[
一文带你解析
Spark
的源码:从
Spark
-
Submit
任务
提交
到资源分配Executor
随着互联网的告诉发展,每天会有大量的数据产生,传统的数据分析手段已经不能满足现在的需求。Apache
Spark
是专为大规模数据处理而设计的快速通用的计算引擎,现在形成一个高速发展应用广泛的生态系统。
Spark
由于其基于内存的计算模式,能够很好的应用于各个应用场景,包括离线数据分析、在线 数据分析和机器学习等。要想深入的了解
Spark
,学习其源码实现是必不可少的过程。 在本场 Chat 中,会讲到...
[1015]
spark
-
submit
提交
任务
及参数说明
文章目录例子
spark
-
submit
详细参数说明--master--deploy-mode--class--name--jars--packages--exclude-packages--repositories--py-files--files--conf PROP=VALUE--properties-file--driver-memory--driver-java-options--driver-library-path--driver-class-path--driver-cores--e
Py
Spark
任务
提交
spark
-
submit
参数设置一文详解
之前我们已经进行了py
spark
环境的搭建以及经过jupyter notebook进行过开发以及实现了一系列的函数功能.但是一般我们跑
spark
都是在
集群
上面跑,只有测试一般在本地上测试,而且每个公司配置的
spark
集群
的端口和设置的参数都有很大出入,故每种情况都有可能发生。所以一般
任务
提交
的参数最好都需要能够清楚的明白对应功能。很多
spark
任务
都会吃大量的内存以及队列资源,合理的安排
spark
资源十分重要,这些都需要我们在
spark
-
submit
指令上面配置。
Spark
1,274
社区成员
1,171
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
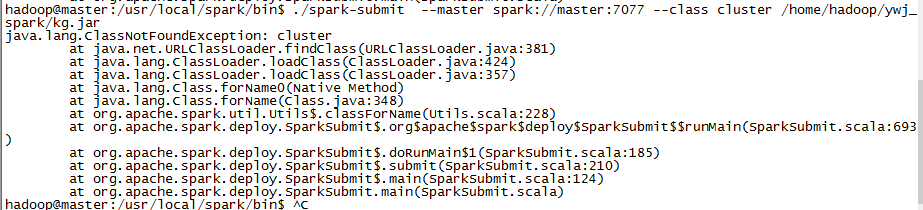



 你确定你main方法类名是cluster,而不是像org.mortbay.jetty.Main这样的?
你确定你main方法类名是cluster,而不是像org.mortbay.jetty.Main这样的?