

70,038
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享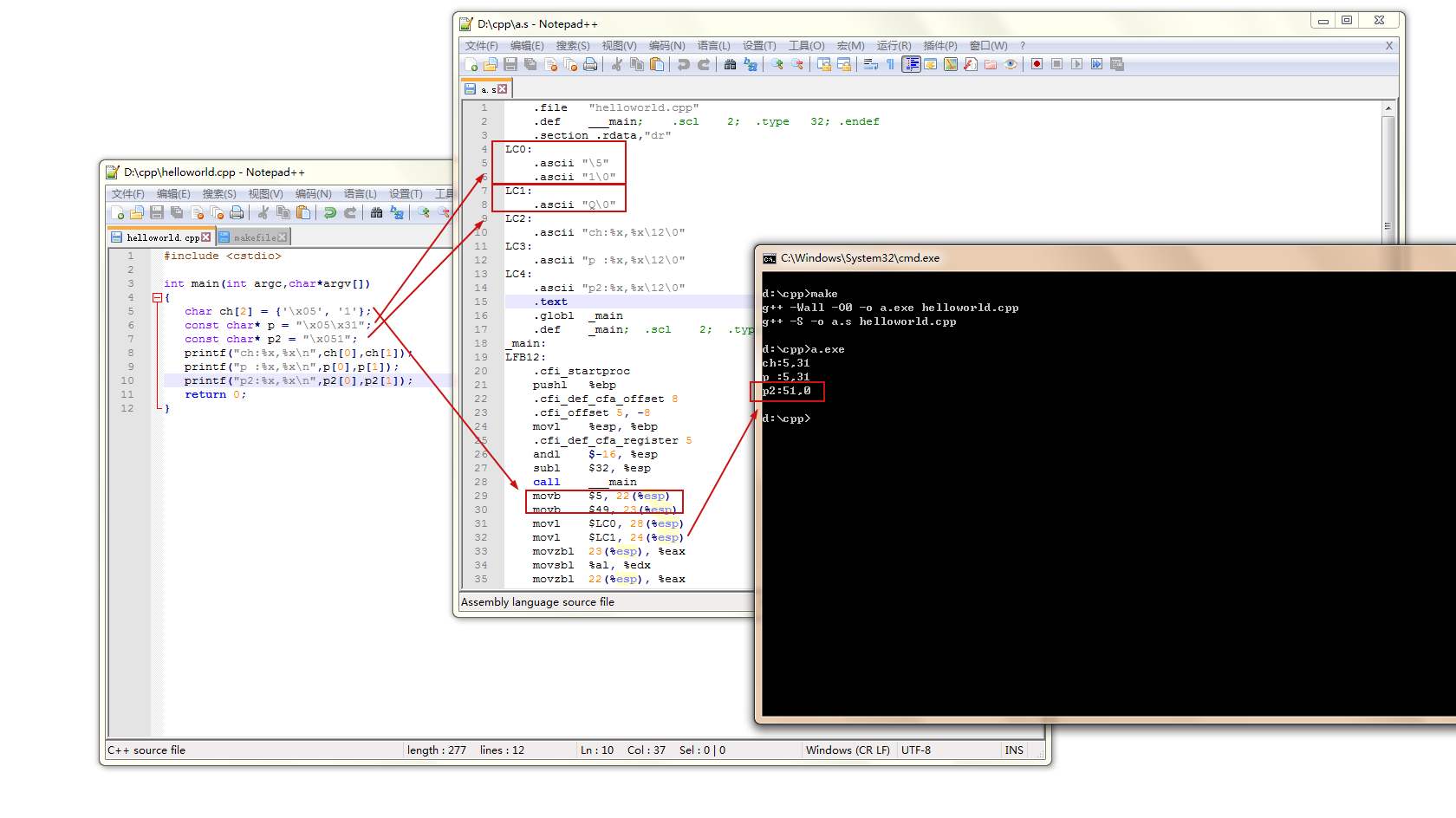
//helloworld.cpp
#include <cstdio>
int main(int argc,char*argv[])
{
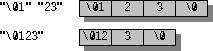
char ch[2] = {'\x05', '1'};
const char* p = "\x05\x31";
const char* p2 = "\x051";
printf("ch:%x,%x\n",ch[0],ch[1]);
printf("p :%x,%x\n",p[0],p[1]);
printf("p2:%x,%x\n",p2[0],p2[1]);
return 0;
}//makefile
exes = a.exe a.s
target: $(exes)
a.exe: helloworld.cpp dump.h
g++ -Wall -O0 -o a.exe helloworld.cpp
a.s: helloworld.cpp
g++ -S -o a.s helloworld.cpp
clean:
cmd //C del $(exes)
//a.s
.file "helloworld.cpp"
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "\5"
.ascii "1\0"
LC1:
.ascii "Q\0"
LC2:
.ascii "ch:%x,%x\12\0"
LC3:
.ascii "p :%x,%x\12\0"
LC4:
.ascii "p2:%x,%x\12\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
LFB12:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $32, %esp
call ___main
movb $5, 22(%esp)
movb $49, 23(%esp)
movl $LC0, 28(%esp)
movl $LC1, 24(%esp)
movzbl 23(%esp), %eax
movsbl %al, %edx
movzbl 22(%esp), %eax
movsbl %al, %eax
movl %edx, 8(%esp)
movl %eax, 4(%esp)
movl $LC2, (%esp)
call _printf
movl 28(%esp), %eax
addl $1, %eax
movzbl (%eax), %eax
movsbl %al, %edx
movl 28(%esp), %eax
movzbl (%eax), %eax
movsbl %al, %eax
movl %edx, 8(%esp)
movl %eax, 4(%esp)
movl $LC3, (%esp)
call _printf
movl 24(%esp), %eax
addl $1, %eax
movzbl (%eax), %eax
movsbl %al, %edx
movl 24(%esp), %eax
movzbl (%eax), %eax
movsbl %al, %eax
movl %edx, 8(%esp)
movl %eax, 4(%esp)
movl $LC4, (%esp)
call _printf
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
LFE12:
.ident "GCC: (GNU) 5.3.0"
.def _printf; .scl 2; .type 32; .endef






 查MSDN是Windows程序员必须掌握的技能之一。
C++ Character Constants
Character constants are one or more members of the “source character set,” the character set in which a program is written, surrounded by single quotation marks ('). They are used to represent characters in the “execution character set,” the character set on the machine where the program executes.
Microsoft Specific
For Microsoft C++, the source and execution character sets are both ASCII.
END Microsoft Specific
There are three kinds of character constants:
Normal character constants
Multicharacter constants
Wide-character constants
Note Use wide-character constants in place of multicharacter constants to ensure portability.
Character constants are specified as one or more characters enclosed in single quotation marks. For example:
char ch = 'x'; // Specify normal character constant.
int mbch = 'ab'; // Specify system-dependent
// multicharacter constant.
wchar_t wcch = L'ab'; // Specify wide-character constant.
Note that mbch is of type int. If it were declared as type char, the second byte would not be retained. A multicharacter constant has four meaningful characters; specifying more than four generates an error message.
Syntax
character-constant :
'c-char-sequence'
L'c-char-sequence'
c-char-sequence :
c-char
c-char-sequence c-char
c-char :
any member of the source character set except the single quotation mark ('), backslash (\), or newline character
escape-sequence
escape-sequence :
simple-escape-sequence
octal-escape-sequence
hexadecimal-escape-sequence
simple-escape-sequence : one of
\' \" \? \\
\a \b \f \n \r \t \v
octal-escape-sequence :
\octal-digit
\octal-digit octal-digit
\octal-digit octal-digit octal-digit
hexadecimal-escape-sequence :
\xhexadecimal-digit
hexadecimal-escape-sequence hexadecimal-digit
Microsoft C++ supports normal, multicharacter, and wide-character constants. Use wide-character constants to specify members of the extended execution character set (for example, to support an international application). Normal character constants have type char, multicharacter constants have type int, and wide-character constants have type wchar_t. (The type wchar_t is defined in the standard include files STDDEF.H, STDLIB.H, and STRING.H. The wide-character functions, however, are prototyped only in STDLIB.H.)
The only difference in specification between normal and wide-character constants is that wide-character constants are preceded by the letter L. For example:
char schar = 'x'; // Normal character constant
wchar_t wchar = L'\x81\x19'; // Wide-character constant
Table 1.2 shows reserved or nongraphic characters that are system dependent or not allowed within character constants. These characters should be represented with escape sequences.
Table 1.2 C++ Reserved or Nongraphic Characters
Character ASCII
Representation ASCII
Value Escape Sequence
Newline NL (LF) 10 or 0x0a \n
Horizontal tab HT 9 \t
Vertical tab VT 11 or 0x0b \v
Backspace BS 8 \b
Carriage return CR 13 or 0x0d \r
Formfeed FF 12 or 0x0c \f
Alert BEL 7 \a
Backslash \ 92 or 0x5c \\
Question mark ? 63 or 0x3f \?
Single quotation mark ' 39 or 0x27 \'
Double quotation mark " 34 or 0x22 \"
Octal number ooo — \ooo
Hexadecimal number hhh — \xhhh
Null character NUL 0 \0
If the character following the backslash does not specify a legal escape sequence, the result is implementation defined. In Microsoft C++, the character following the backslash is taken literally, as though the escape were not present, and a level 1 warning (“unrecognized character escape sequence”) is issued.
Octal escape sequences, specified in the form \ooo, consist of a backslash and one, two, or three octal characters. Hexadecimal escape sequences, specified in the form \xhhh, consist of the characters \x followed by a sequence of hexadecimal digits. Unlike octal escape constants, there is no limit on the number of hexadecimal digits in an escape sequence.
Octal escape sequences are terminated by the first character that is not an octal digit, or when three characters are seen. For example:
wchar_t och = L'\076a'; // Sequence terminates at a
char ch = '\233'; // Sequence terminates after 3 characters
Similarly, hexadecimal escape sequences terminate at the first character that is not a hexadecimal digit. Because hexadecimal digits include the letters a through f (and A through F), make sure the escape sequence terminates at the intended digit.
Because the single quotation mark (') encloses character constants, use the escape sequence \' to represent enclosed single quotation marks. The double quotation mark (") can be represented without an escape sequence. The backslash character (\) is a line-continuation character when placed at the end of a line. If you want a backslash character to appear within a character constant, you must type two backslashes in a row (\\). (SeePhases of Translation in the Preprocessor Reference for more information about line continuation.)
查MSDN是Windows程序员必须掌握的技能之一。
C++ Character Constants
Character constants are one or more members of the “source character set,” the character set in which a program is written, surrounded by single quotation marks ('). They are used to represent characters in the “execution character set,” the character set on the machine where the program executes.
Microsoft Specific
For Microsoft C++, the source and execution character sets are both ASCII.
END Microsoft Specific
There are three kinds of character constants:
Normal character constants
Multicharacter constants
Wide-character constants
Note Use wide-character constants in place of multicharacter constants to ensure portability.
Character constants are specified as one or more characters enclosed in single quotation marks. For example:
char ch = 'x'; // Specify normal character constant.
int mbch = 'ab'; // Specify system-dependent
// multicharacter constant.
wchar_t wcch = L'ab'; // Specify wide-character constant.
Note that mbch is of type int. If it were declared as type char, the second byte would not be retained. A multicharacter constant has four meaningful characters; specifying more than four generates an error message.
Syntax
character-constant :
'c-char-sequence'
L'c-char-sequence'
c-char-sequence :
c-char
c-char-sequence c-char
c-char :
any member of the source character set except the single quotation mark ('), backslash (\), or newline character
escape-sequence
escape-sequence :
simple-escape-sequence
octal-escape-sequence
hexadecimal-escape-sequence
simple-escape-sequence : one of
\' \" \? \\
\a \b \f \n \r \t \v
octal-escape-sequence :
\octal-digit
\octal-digit octal-digit
\octal-digit octal-digit octal-digit
hexadecimal-escape-sequence :
\xhexadecimal-digit
hexadecimal-escape-sequence hexadecimal-digit
Microsoft C++ supports normal, multicharacter, and wide-character constants. Use wide-character constants to specify members of the extended execution character set (for example, to support an international application). Normal character constants have type char, multicharacter constants have type int, and wide-character constants have type wchar_t. (The type wchar_t is defined in the standard include files STDDEF.H, STDLIB.H, and STRING.H. The wide-character functions, however, are prototyped only in STDLIB.H.)
The only difference in specification between normal and wide-character constants is that wide-character constants are preceded by the letter L. For example:
char schar = 'x'; // Normal character constant
wchar_t wchar = L'\x81\x19'; // Wide-character constant
Table 1.2 shows reserved or nongraphic characters that are system dependent or not allowed within character constants. These characters should be represented with escape sequences.
Table 1.2 C++ Reserved or Nongraphic Characters
Character ASCII
Representation ASCII
Value Escape Sequence
Newline NL (LF) 10 or 0x0a \n
Horizontal tab HT 9 \t
Vertical tab VT 11 or 0x0b \v
Backspace BS 8 \b
Carriage return CR 13 or 0x0d \r
Formfeed FF 12 or 0x0c \f
Alert BEL 7 \a
Backslash \ 92 or 0x5c \\
Question mark ? 63 or 0x3f \?
Single quotation mark ' 39 or 0x27 \'
Double quotation mark " 34 or 0x22 \"
Octal number ooo — \ooo
Hexadecimal number hhh — \xhhh
Null character NUL 0 \0
If the character following the backslash does not specify a legal escape sequence, the result is implementation defined. In Microsoft C++, the character following the backslash is taken literally, as though the escape were not present, and a level 1 warning (“unrecognized character escape sequence”) is issued.
Octal escape sequences, specified in the form \ooo, consist of a backslash and one, two, or three octal characters. Hexadecimal escape sequences, specified in the form \xhhh, consist of the characters \x followed by a sequence of hexadecimal digits. Unlike octal escape constants, there is no limit on the number of hexadecimal digits in an escape sequence.
Octal escape sequences are terminated by the first character that is not an octal digit, or when three characters are seen. For example:
wchar_t och = L'\076a'; // Sequence terminates at a
char ch = '\233'; // Sequence terminates after 3 characters
Similarly, hexadecimal escape sequences terminate at the first character that is not a hexadecimal digit. Because hexadecimal digits include the letters a through f (and A through F), make sure the escape sequence terminates at the intended digit.
Because the single quotation mark (') encloses character constants, use the escape sequence \' to represent enclosed single quotation marks. The double quotation mark (") can be represented without an escape sequence. The backslash character (\) is a line-continuation character when placed at the end of a line. If you want a backslash character to appear within a character constant, you must type two backslashes in a row (\\). (SeePhases of Translation in the Preprocessor Reference for more information about line continuation.)

#pragma comment(lib,"user32")
#pragma comment(lib,"gdi32")
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
extern "C" HWND WINAPI GetConsoleWindow();
void HideTheCursor() {
CONSOLE_CURSOR_INFO cciCursor;
HANDLE hStdOut = GetStdHandle(STD_OUTPUT_HANDLE);
if(GetConsoleCursorInfo(hStdOut, &cciCursor)) {
cciCursor.bVisible = FALSE;
SetConsoleCursorInfo(hStdOut, &cciCursor);
}
}
void ShowTheCursor() {
CONSOLE_CURSOR_INFO cciCursor;
HANDLE hStdOut = GetStdHandle(STD_OUTPUT_HANDLE);
if(GetConsoleCursorInfo(hStdOut, &cciCursor)) {
cciCursor.bVisible = TRUE;
SetConsoleCursorInfo(hStdOut, &cciCursor);
}
}
int main() {
HWND hwnd;
HDC hdc;
HFONT hfont;
wchar_t wc[2];
system("color F0");
system("cls");
HideTheCursor();
hwnd = GetConsoleWindow();
hdc = GetDC(hwnd);
hfont = CreateFont(48,0,0,0,0,0,0,0,GB2312_CHARSET ,0,0,0,0,"宋体-方正超大字符集");
SelectObject(hdc,hfont);
wc[0]=0xD854u;
wc[1]=0xDC00u;
TextOutW(hdc,10,10,wc,2);
DeleteObject(hfont);
ReleaseDC(hwnd,hdc);
getch();
system("color 07");
system("cls");
ShowTheCursor();
return 0;
}
#if 0
代理项或代理项对是一对共同表示单个字符的 16 位 Unicode 编码值。需要记住的关键一点是:
代理项对实际上是 32 位单个字符,不能再假定一个 16 位 Unicode 编码值正好映射到一个字符。
使用代理项对
代理项对的第一个值是高代理项,包含介于 U+D800 到 U+DBFF 范围内的 16 位代码值。
该对的第二个值是低代理项,包含介于 U+DC00 到 U+DFFF 范围内的值。通过使用代理项对,
16 位 Unicode 编码系统可以对已由 Unicode 标准定义的一百多万个其他字符 (220) 进行寻址。
在传递给 XmlTextWriter 方法的任何字符串中都可以使用代理项字符。不过,代理项字符在编写的
XML 中应该有效。例如,万维网联合会 (W3C) 建议不允许在元素或属性的名称中使用代理项字符。
如果字符串包含无效的代理项对,则引发异常。
另外,可以使用 WriteSurrogateCharEntity 写出与代理项对相对应的字符实体。字符实体以十六
进制格式写出,并用以下公式生成:
(highChar -0xD800) * 0x400 + (lowChar -0xDC00) + 0x10000
如果字符串包含无效的代理项对,则引发异常。下面的示例显示将代理项对作为输入的 WriteSurrogateCharEntity 方法。
C#复制
// The following line writes 𐀀.
WriteSurrogateCharEntity ('\uDC00', '\uD800');
下面的示例生成一个代理项对文件,将其加载到 XmlReader 中,并用新的文件名保存文件。
然后,原始文件和新文件被加载回应用程序的 XML 文档对象模型 (DOM) 结构中以进行比较。
C#复制
char lowChar, highChar;
char [] charArray = new char[10];
FileStream targetFile = new FileStream("SurrogatePair.xml",
FileMode.Create, FileAccess.ReadWrite, FileShare.ReadWrite);
lowChar = Convert.ToChar(0xDC00);
highChar = Convert.ToChar(0xD800);
XmlTextWriter tw = new XmlTextWriter(targetFile, null);
tw.Formatting = Formatting.Indented;
tw.WriteStartElement("root");
tw.WriteStartAttribute("test", null);
tw.WriteSurrogateCharEntity(lowChar, highChar);
lowChar = Convert.ToChar(0xDC01);
highChar = Convert.ToChar(0xD801);
tw.WriteSurrogateCharEntity(lowChar, highChar);
lowChar = Convert.ToChar(0xDFFF);
highChar = Convert.ToChar(0xDBFF);
tw.WriteSurrogateCharEntity(lowChar, highChar);
// Add 10 random surrogate pairs.
// As Unicode, the high bytes are in lower
// memory; for example, word 6A21 as 21 6A.
// The high or low is in the logical sense.
Random random = new Random();
for (int i = 0; i < 10; ++i) {
lowChar = Convert.ToChar(random.Next(0xDC00, 0xE000));
highChar = Convert.ToChar(random.Next(0xD800, 0xDC00));
charArray[i] = highChar;
charArray[++i] = lowChar;
}
tw.WriteChars(charArray, 0, charArray.Length);
for (int i = 0; i < 10; ++i) {
lowChar = Convert.ToChar(random.Next(0xDC00, 0xE000));
highChar = Convert.ToChar(random.Next(0xD800, 0xDC00));
tw.WriteSurrogateCharEntity(lowChar, highChar);
}
tw.WriteEndAttribute();
tw.WriteEndElement();
tw.Flush();
tw.Close();
XmlTextReader r = new XmlTextReader("SurrogatePair.xml");
r.Read();
r.MoveToFirstAttribute();
targetFile = new FileStream("SurrogatePairFromReader.xml",
FileMode.Create, FileAccess.ReadWrite, FileShare.ReadWrite);
tw = new XmlTextWriter(targetFile, null);
tw.Formatting = Formatting.Indented;
tw.WriteStartElement("root");
tw.WriteStartAttribute("test", null);
tw.WriteString(r.Value);
tw.WriteEndAttribute();
tw.WriteEndElement();
tw.Flush();
tw.Close();
// Load both result files into the DOM and compare.
XmlDocument doc1 = new XmlDocument();
XmlDocument doc2 = new XmlDocument();
doc1.Load("SurrogatePair.xml");
doc2.Load("SurrogatePairFromReader.xml");
if (doc1.InnerXml != doc2.InnerXml) {
Console.WriteLine("Surrogate Pair test case failed");
}
在使用 WriteChars 方法(一次写出一个缓冲区的数据)写出时,输入中的代理项对可能
会在一个缓冲区内被意外拆分。由于代理项值是定义完善的,如果 WriteChars 遇到来自
较低范围或者较高范围的 Unicode 值,它将该值标识为代理项对的一半。当遇到
WriteChars 将导致从拆分代理项对的缓冲区写入的情况时,将引发异常。使用
IsHighSurrogate 方法检查缓冲区是否以高代理项字符结束。如果缓冲区中的最后一个
字符不是高代理项,可以将该缓冲区传递给 WriteChars 方法。
请参见
概念
使用 XmlTextWriter 创建格式正确的 XML
XmlTextWriter 的 XML 输出格式设置
XmlTextWriter 的命名空间功能
#endif

 9楼正解!
9楼正解!






