17,086
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





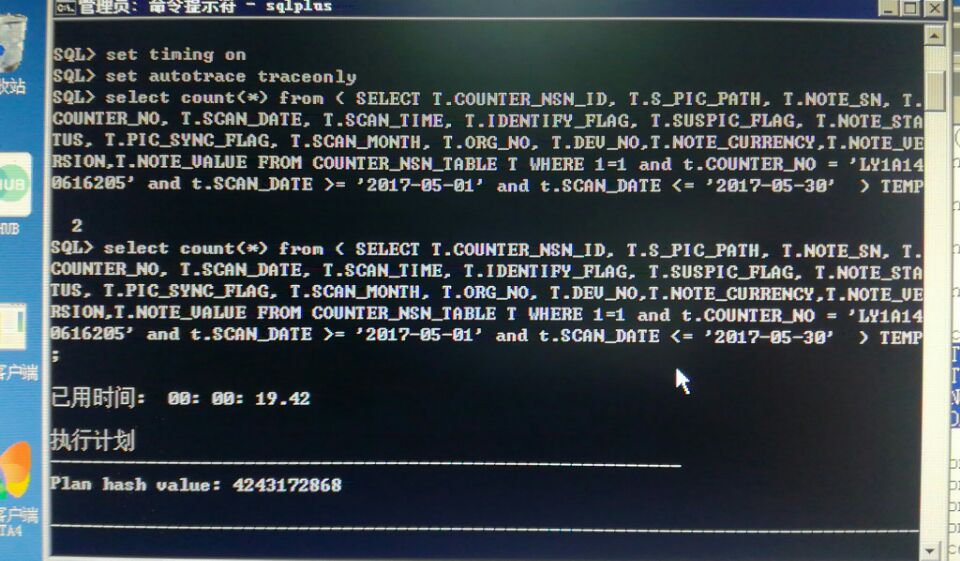
SQL> set pagesize 1000
SQL> set linesize 200
SQL> select /*+gather_plan_statistics*/count(*) from ttt;
COUNT(*)
----------
1643
SQL> select sql_id,sql_text from v$sql where sql_text ='select /*+gather_plan_statistics*/count(*) from ttt';
SQL_ID
-------------
SQL_TEXT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2j6cbrxqxds4v
select /*+gather_plan_statistics*/count(*) from ttt
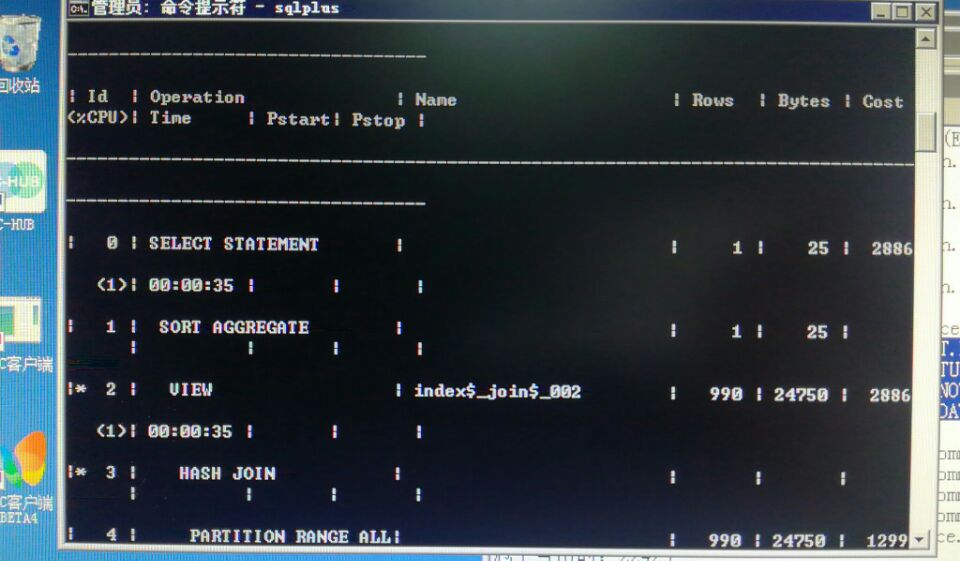
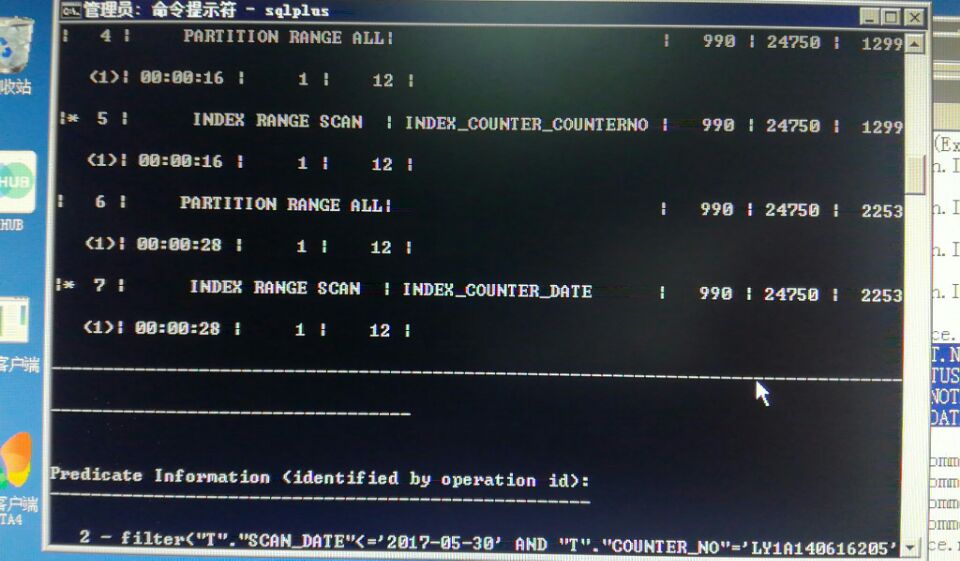
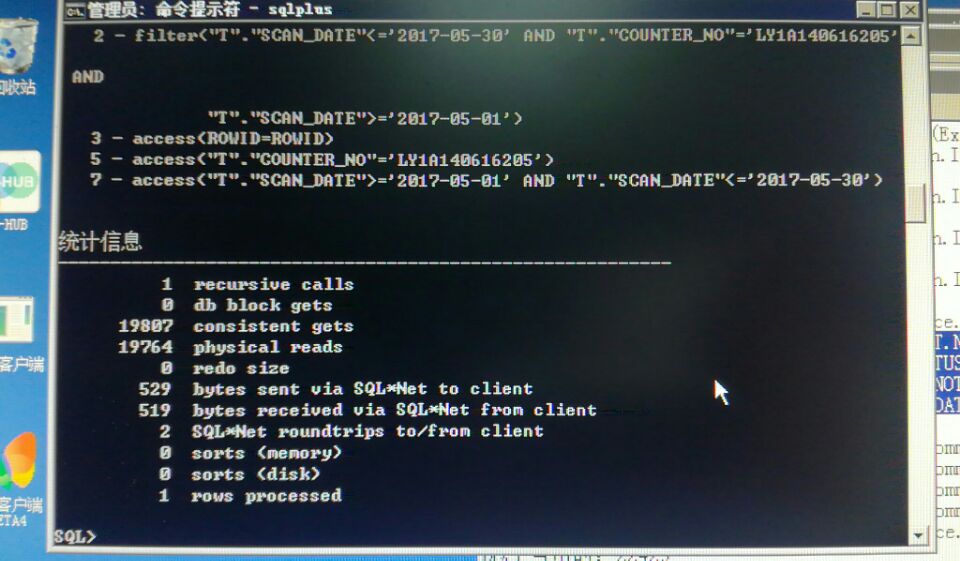
SQL> select * from table(dbms_xplan.display_cursor('2j6cbrxqxds4v',null,'allstats last'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 2j6cbrxqxds4v, child number 0
-------------------------------------
select /*+gather_plan_statistics*/count(*) from ttt
Plan hash value: 3818711063
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 11 |
| 1 | SORT AGGREGATE | | 1 | 1 | 1 |00:00:00.01 | 11 |
| 2 | INDEX FAST FULL SCAN| I_ttt_ID | 1 | 1643 | 1643 |00:00:00.01 | 11 |
----------------------------------------------------------------------------------------------
14 rows selected.
SQL>