本人刚学Spark,有个最简单的例子,但是我在spark中运行报以上错误,
package example
import com.typesafe.scalalogging.LazyLogging
import org.apache.spark.{SparkConf, SparkContext}
object SparkExample extends LazyLogging {
private val master = "spark://master:7077"
private val appName = "example-spark"
private val stopWords = Set("gif", "png")
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster(master)
.setAppName(appName)
val sc = new SparkContext(conf)
val lines = sc.textFile("file:/home/qiujl/access.log")
val wordsCount = WordsCount.count(sc, lines, stopWords)
val counts = wordsCount.collect().mkString("[", ", ", "]")
logger.info(counts)
}
}
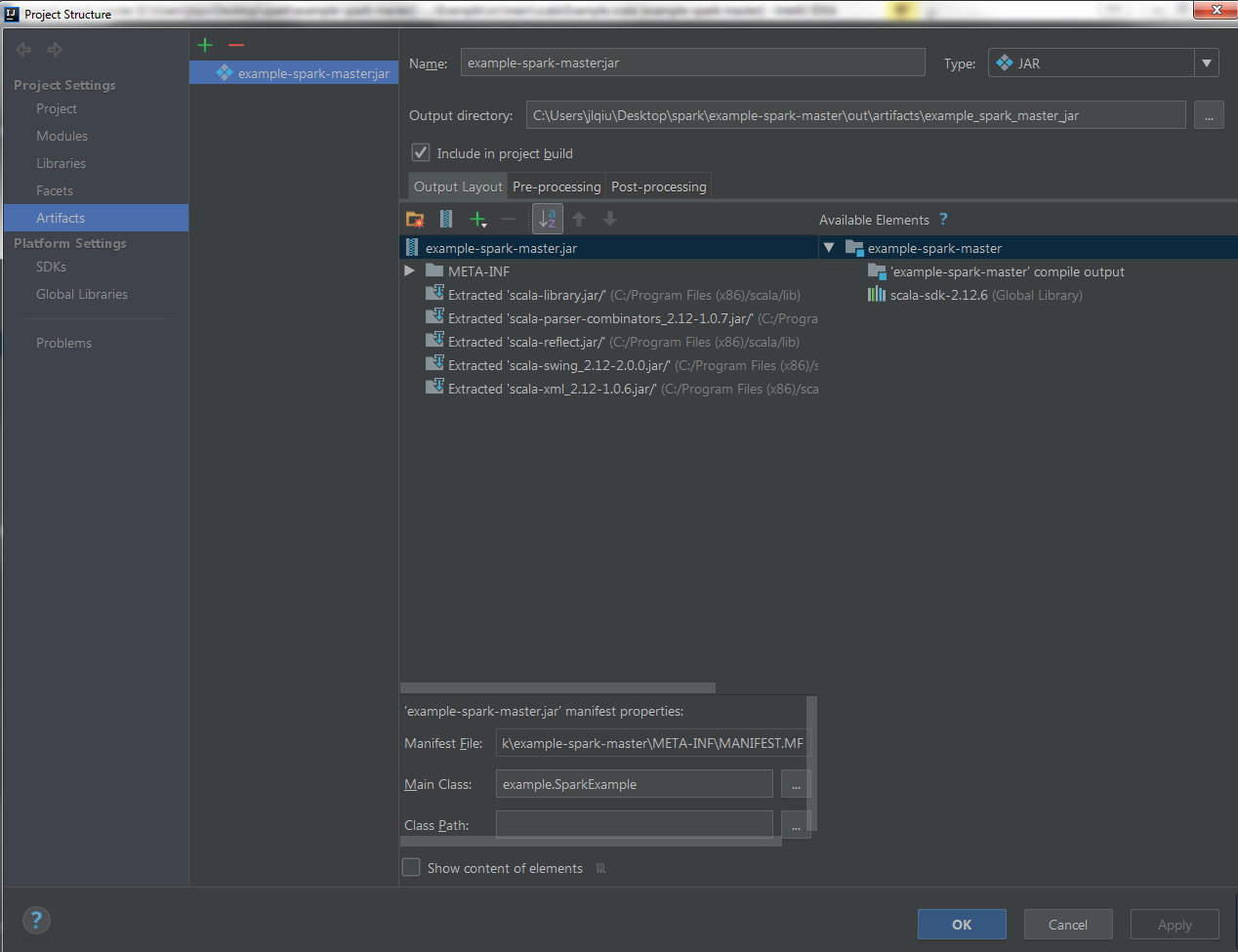
报以下错误:
[qwwsl@master ~]$ spark-submit --master spark://master:7077 --num-executors 48 --driver-memory 2g --executor-memory 7g --executor-cores 3 /home/qiujl/example-spark-master.jar
18/05/30 10:27:38 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
java.lang.ClassNotFoundException: example.SparkExample
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.spark.util.Utils$.classForName(Utils.scala:235)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:836)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:197)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:227)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:136)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享




