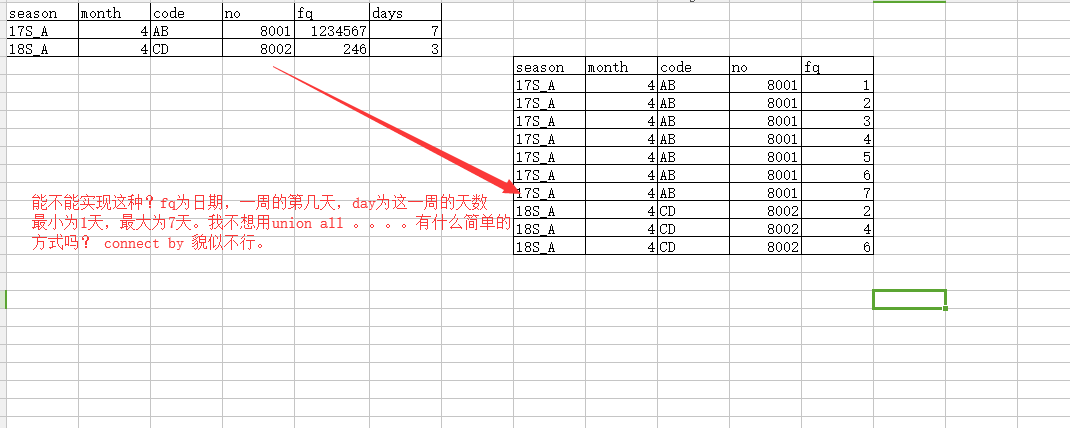
写了个,但效率不高,如果数据量大,对性能影响比较大
with d as
(select '17S_A' as season,
4 as month,
'AB' as code,
8001 as no,
1234567 as fq,
7 as days
from dual
union all
select '18S_A', 4, 'CD', 8002, 246, 3
from dual
union all
select '19S_A', 4, 'EF', 8003, 15, 2 from dual)
select distinct *
from (select season, month, code, no, substr(fq, level, 1) fq
from d
connect by substr(fq, level, 1) is not null)
order by 1, 2, 3, 4, 5;
重新写了一个,这个效率高
with d as
(select '17S_A' as season,
4 as month,
'AB' as code,
8001 as no,
1234567 as fq,
7 as days
from dual
union all
select '18S_A' as season,
4 as month,
'CD' as code,
8002 as no,
246 as fq,
3 as days
from dual
union all
select '19S_A', 4, 'EF', 8003, 15, 2 from dual)
select season, month, code, no, substr(fq, level, 1) fq
from d
connect by level <= length(fq)
and season = prior season
and month = prior month
and code = prior code
and no = prior no
and prior dbms_random.value is not null



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



