

17,140
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
create table SC
(
mtype varchar(10),
worktime DATE
)
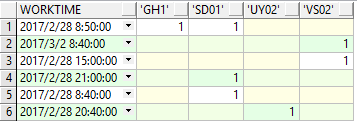
insert into SC VALUES('SD01',TO_DATE('2017-02-28 08:40:00','yyyy-mm-dd hh24:mi:ss'))
insert into SC VALUES('GH1',TO_DATE('2017-02-28 08:50:00','yyyy-mm-dd hh24:mi:ss'))
insert into SC VALUES('SD01',TO_DATE('2017-02-28 08:50:00','yyyy-mm-dd hh24:mi:ss'))
insert into SC VALUES('VS02',TO_DATE('2017-02-28 15:00:00','yyyy-mm-dd hh24:mi:ss'))
insert into SC VALUES('UY02',TO_DATE('2017-02-28 20:40:00','yyyy-mm-dd hh24:mi:ss'))
insert into SC VALUES('SD01',TO_DATE('2017-02-28 21:00:00','yyyy-mm-dd hh24:mi:ss'))
insert into SC VALUES('VS02',TO_DATE('2017-03-02 08:40:00','yyyy-mm-dd hh24:mi:ss'))

create or replace procedure test20181101 is
pivot_sql_text varchar2(30000);
select_sql_text varchar2(30000);
begin
select to_char(wm_concat('''' || t1.mtype || '''')) pivot_sql_text ,
to_char(wm_concat('count(decode(t2."''' || t1.mtype ||
'''", 0, null, null, null, 1)) ' || t1.mtype)) || ',' select_sql_text into pivot_sql_text,
select_sql_text
from (select distinct v1.mtype mtype from sc v1) t1
order by t1.mtype;
execute immediate
'
create or replace view view_test20181101 as
with tab1 as (
select 60 * 60 * (7.5 + level) st,
60 * 60 * (8.5 + level) ed
from dual
connect by level <= 13
),
tab2 as (
select*from sc t1
pivot(count(t1.mtype) for mtype in (' || pivot_sql_text || '))
)
select ' || select_sql_text || '
to_char(trunc(sysdate) + t1.st / 86400, ''fmhh24:mi'') || ''-'' ||
to_char(trunc(sysdate) + t1.ed / 86400, ''fmhh24:mi'') ttttt
from tab1 t1, tab2 t2
where t1.st <= to_number(to_char(t2.worktime(+), ''sssss''))
and t1.ed > to_number(to_char(t2.worktime(+), ''sssss''))
group by t1.st, t1.ed
order by t1.st
'
;
end test20181101;
begin
test20181101;
end;
select*from view_test20181101;
create or replace procedure test20181101 is
pivot_sql_text varchar2(30000);
select_sql_text varchar2(30000);
begin
select listagg('''' || t1.mtype || '''', ',') within group(order by t1.mtype) ,
listagg('count(decode(t2."''' || t1.mtype ||
'''", 0, null, null, null, 1)) ' || t1.mtype, ',') within group(order by t1.mtype) || ',' into pivot_sql_text,
select_sql_text
from (select distinct v1.mtype mtype from sc v1) t1
;
execute immediate
'
create or replace view view_test20181101 as
with tab1 as (
select 60 * 60 * (7.5 + level) st,
60 * 60 * (8.5 + level) ed
from dual
connect by level <= 13
),
tab2 as (
select*from sc t1
pivot(count(t1.mtype) for mtype in (' || pivot_sql_text || '))
)
select ' || select_sql_text || '
to_char(trunc(sysdate) + t1.st / 86400, ''fmhh24:mi'') || ''-'' ||
to_char(trunc(sysdate) + t1.ed / 86400, ''fmhh24:mi'') ttttt
from tab1 t1, tab2 t2
where t1.st <= to_number(to_char(t2.worktime(+), ''sssss''))
and t1.ed > to_number(to_char(t2.worktime(+), ''sssss''))
group by t1.st, t1.ed
order by t1.st
'
;
end test20181101;

with tab1 as (
select 60 * 60 * (7.5 + level) st,
60 * 60 * (8.5 + level) ed
from dual
connect by level <= 13
),
tab2 as (
select*from sc t1
pivot(count(t1.mtype) for mtype in ('SD01', 'GH1', 'VS02', 'UY02'))
)
select to_char(trunc(sysdate) + t1.st / 86400, 'fmhh24:mi') || '-' ||
to_char(trunc(sysdate) + t1.ed / 86400, 'fmhh24:mi') ttttt,
count(decode(t2."'SD01'", 0, null, null, null, 1)) sd01,
count(decode(t2."'GH1'", 0, null, null, null, 1)) gh1,
count(decode(t2."'VS02'", 0, null, null, null, 1)) vs02,
count(decode(t2."'UY02'", 0, null, null, null, 1)) uy02
from tab1 t1, tab2 t2
where t1.st <= to_number(to_char(t2.worktime(+), 'sssss'))
and t1.ed > to_number(to_char(t2.worktime(+), 'sssss'))
group by t1.st, t1.ed
order by t1.st
;select to_char(wm_concat(distinct '''' || t1.mtype || '''')) pivot_sql_text,
to_char(wm_concat(distinct 'count(decode(t2."''' || t1.mtype || '''", 0, null, null, null, 1)) ' || t1.mtype)) || ',' select_sql_text
from sc t1 order by t1.mtype;
if OBJECT_ID('tempdb..#tempP') is not null
drop table #tempP
CREATE TABLE #tempP(mtype varchar(10),worktime DATETIME)
insert into #tempP
select 'SD01' ,'2017-02-28 08:10:00.000' UNION ALL
select 'GH1' ,'2017-02-28 10:00:00.000' UNION ALL
select 'SD01' ,'2017-02-28 14:40:00.000' UNION ALL
select 'VS02' ,'2017-02-28 15:00:00.000' UNION ALL
select 'UY02' ,'2017-02-28 20:00:00.000' UNION ALL
select 'VS02' ,'2017-03-28 08:40:00.000'
DECLARE @START_TIME TIME
DECLARE @END_TIME TIME
DECLARE @SQL VARCHAR(MAX)
SET @START_TIME='08:30'
SET @END_TIME='21:30'
;WITH CTE_1
AS
(SELECT A.NUMBER,
CASE WHEN NUMBER<>0 THEN DATEADD(MINUTE,1,DATEADD(HOUR,NUMBER,START_TIME)) ELSE DATEADD(HOUR,NUMBER,START_TIME) END AS START_TIME,
DATEADD(HOUR,NUMBER+1,START_TIME) AS END_TIME
FROM MASTER.DBO.spt_values A
JOIN
(SELECT DATEDIFF(HOUR,@START_TIME,@END_TIME) AS QTY,@START_TIME AS START_TIME) AS B ON A.NUMBER<=B.QTY-1
WHERE TYPE='P'),
CTE_2
AS
(SELECT CONVERT(VARCHAR(5),A.START_TIME,108)+'-'+CONVERT(VARCHAR(5),A.END_TIME,108) AS PERIOD,
mtype
FROM CTE_1 A
LEFT JOIN (SELECT * from #tempP WHERE CONVERT(VARCHAR(10),WORKTIME,23)='2017-03-28') B ON CONVERT(VARCHAR(10),B.WORKTIME,108) BETWEEN A.START_TIME AND A.END_TIME
)
SELECT @SQL=ISNULL(@SQL+',','')+'SUM(CASE WHEN MTYPE='''+MTYPE+''' THEN 1 ELSE 0 END) AS '+MTYPE
FROM
(SELECT MTYPE FROM #tempP GROUP BY MTYPE ) AS A
SET @SQL='
DECLARE @START_TIME TIME
DECLARE @END_TIME TIME
SET @START_TIME=''08:30''
SET @END_TIME=''21:30''
;WITH CTE_1
AS
(SELECT A.NUMBER,
CASE WHEN NUMBER<>0 THEN DATEADD(MINUTE,1,DATEADD(HOUR,NUMBER,START_TIME)) ELSE DATEADD(HOUR,NUMBER,START_TIME) END AS START_TIME,
DATEADD(HOUR,NUMBER+1,START_TIME) AS END_TIME
FROM MASTER.DBO.spt_values A
JOIN
(SELECT DATEDIFF(HOUR,@START_TIME,@END_TIME) AS QTY,@START_TIME AS START_TIME) AS B ON A.NUMBER<=B.QTY-1
WHERE TYPE=''P''),
CTE_2
AS
(SELECT CONVERT(VARCHAR(5),A.START_TIME,108)+''-''+CONVERT(VARCHAR(5),A.END_TIME,108) AS PERIOD,
mtype
FROM CTE_1 A
LEFT JOIN (SELECT * from #tempP WHERE CONVERT(VARCHAR(10),WORKTIME,23)=''2017-04-28'') B ON CONVERT(VARCHAR(10),B.WORKTIME,108) BETWEEN A.START_TIME AND A.END_TIME
)
SELECT PERIOD,'+@SQL+' FROM CTE_2 GROUP BY PERIOD order by PERIOD'
EXEC(@SQL)


