社区
Spark
帖子详情
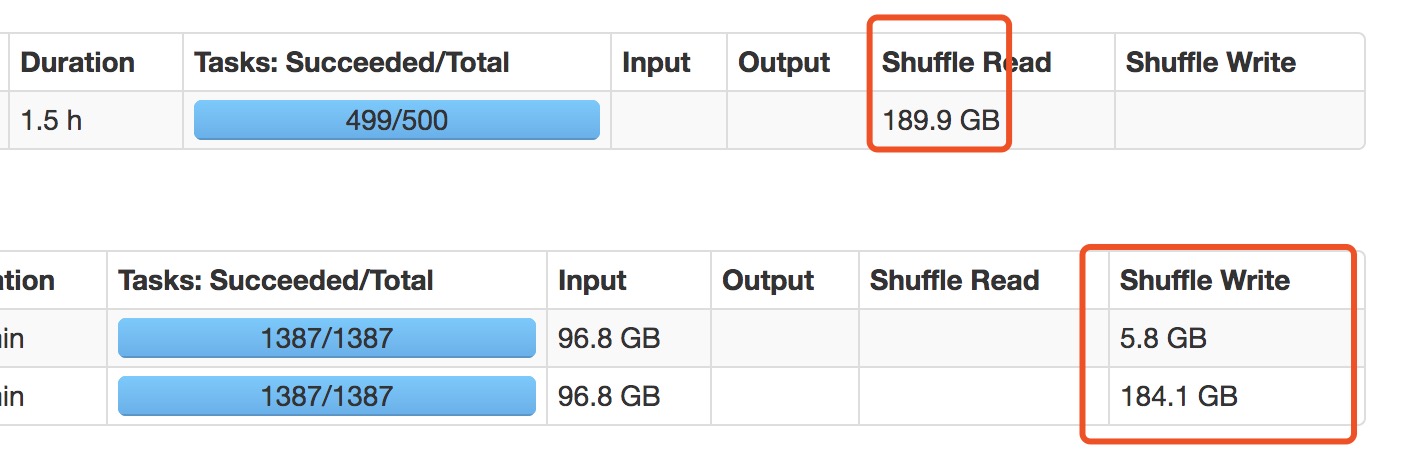
spark shuffle read 已经读完,但是就是不继续运行!!!
Tzero__
2019-01-05 08:05:17
...全文
12991
3
打赏
收藏
spark shuffle read 已经读完,但是就是不继续运行!!!
[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
Tzero__
2020-12-09
打赏
举报
回复
解决了 就是因为数据倾斜 导致oom
xingchensuiyue
2020-12-04
打赏
举报
回复
你的这种问题后来解决了吗
BigBangBug
2019-01-17
打赏
举报
回复
版本、配置、cpu内存啥的都没贴出来,看不出来的
Spark
中的
Spark
Shuffle
详解
Shuffle
简介
Shuffle
描述着数据从map task输出到reduce task输入的这段过程。
shuffle
是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过
shuffle
这个环节,
shuffle
的性能高低直接影响了整个程序的性能和吞吐量。因为在分布式情况下,reduce task需要跨节点去拉取其它节点上的map task结果。这一过程将会产生网络资源消耗和内存,磁盘IO的消耗。通常
shuffle
分为两部分:Map阶段的数据准备和Reduce阶段的数据拷贝处理。一
详解MapReduce
Shuffle
与
Spark
Shuffle
1
Shuffle
简介
Shuffle
的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,
Shuffle
更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。或者说需要将各节点上同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程成为
Shuffle
.。其在...
Spark
Shuffle
FetchFailedException报错解决方案
Spark
Shuffle
FetchFailedException
读懂
Spark
Shuffle
1. Hash
Shuffle
Manager
shuffle
write 阶段,主要就是在一个 stage 结束计算之后,为了下一个 stage 可以执行
shuffle
类的算子(比如 reduceByKey),而将每个 task 处理的数据按 key 进行“划分”。所谓“划分”,就是对相同的 key 执行 hash 算法,从而将相同 key 都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游 stage 的一个 task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁
Spark
Shuffle
和 MR
Shuffle
异同看这篇就够了
spark
shuffle
mapreduce
shuffle
过程,以及区别
Spark
1,260
社区成员
1,169
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享


