1,274
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
public class TestUtil {
public static void main(String[] args){
System.setProperty("user.name", "root");
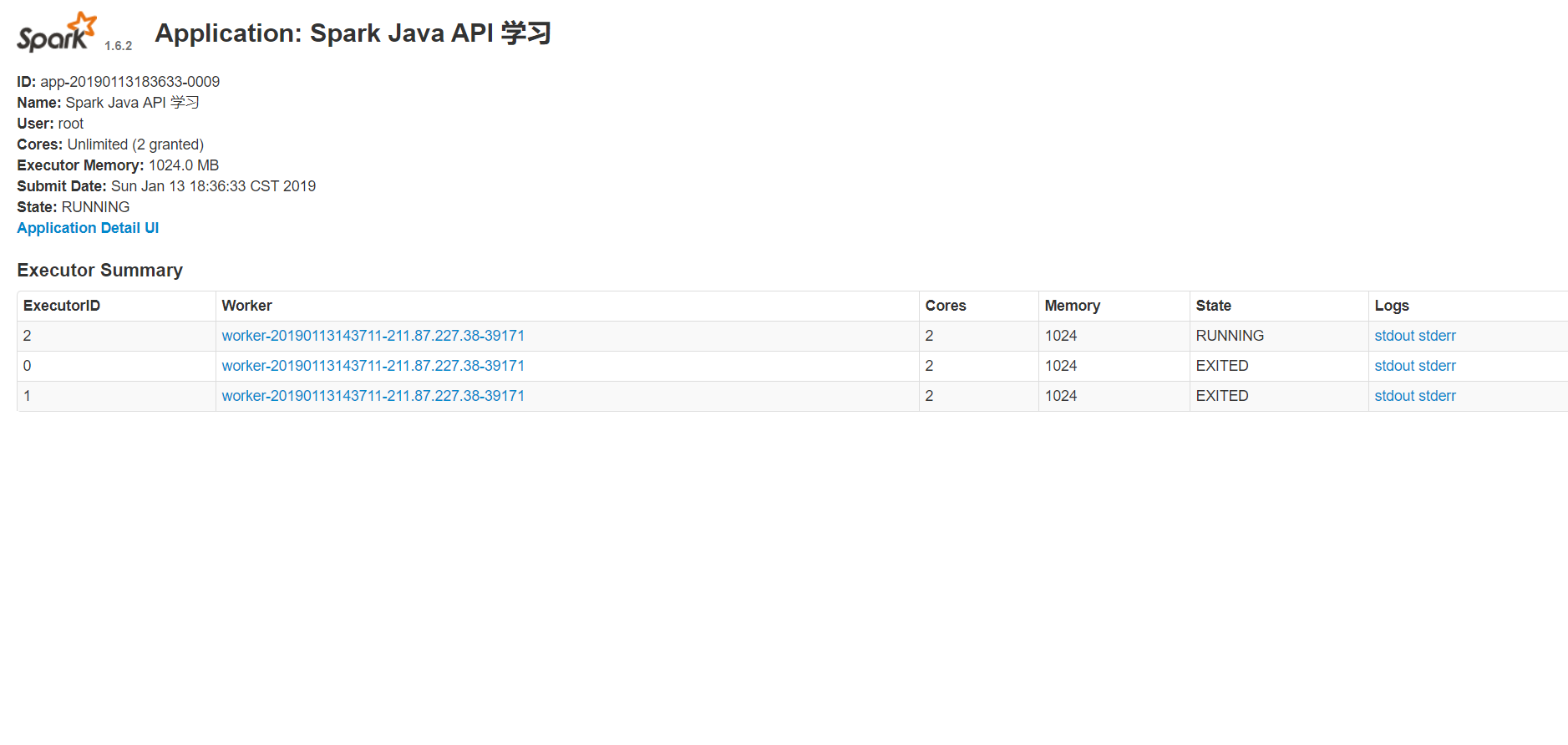
SparkConf conf = new SparkConf().setAppName("Spark Java API 学习")
.setMaster("spark://211.87.227.79:7077");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> users = sc.textFile("hdfs://211.87.227.79:8020/input/wordcount.txt");
System.out.println(users.first());
}
}