社区
Spark
帖子详情
讨论: 关于广播变量的用法
jdjwxj
2019-03-26 03:55:49
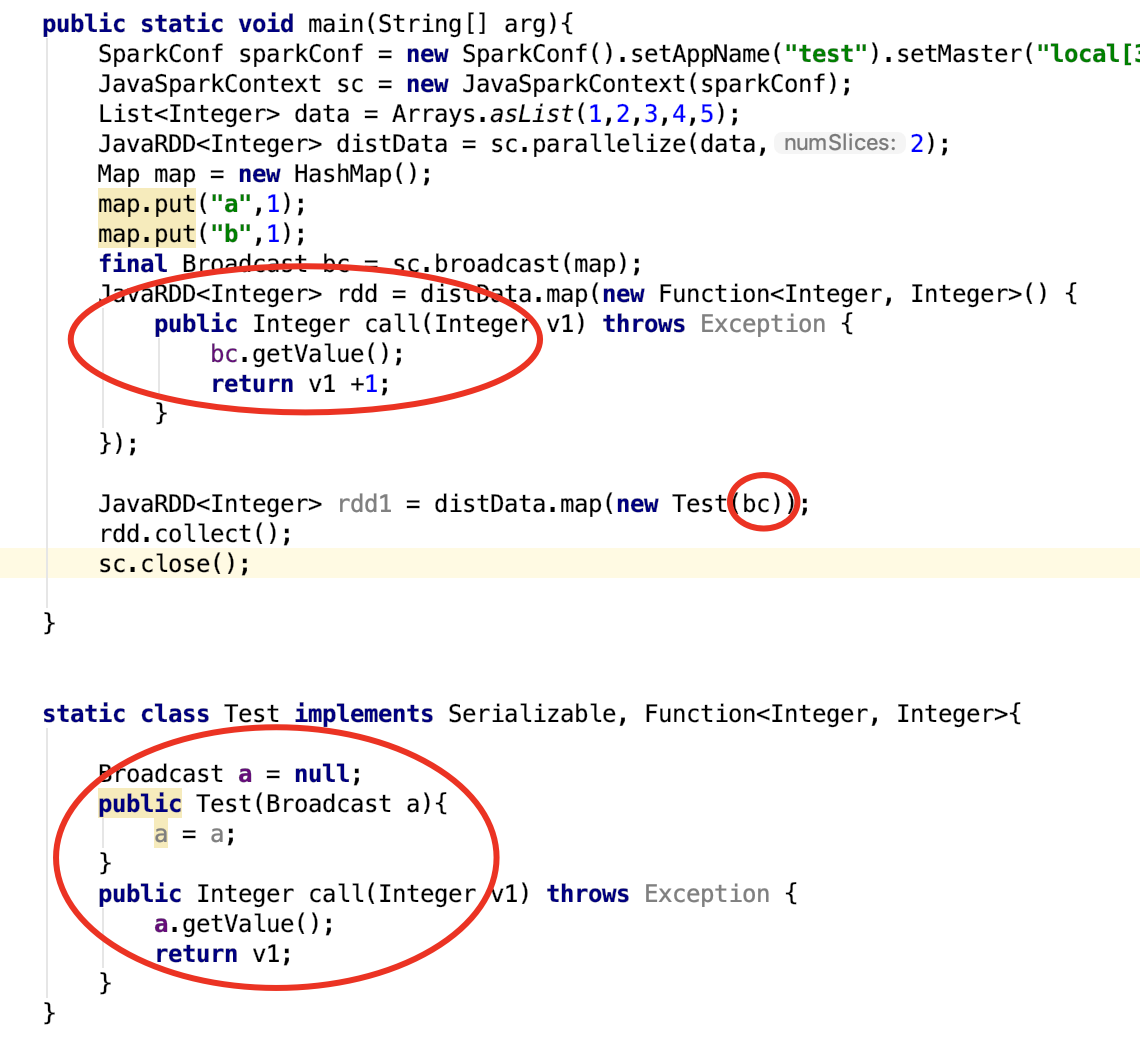
讨论下这两种使用广播变量的方式有区别吗?[图片]
...全文
322
4
打赏
收藏
讨论: 关于广播变量的用法
讨论下这两种使用广播变量的方式有区别吗?[图片]
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
4 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
杨荣茂
2019-03-28
打赏
举报
回复
你们咋都这么强
杨荣茂
2019-03-28
打赏
举报
回复
你们都好强啊
jdjwxj
2019-03-26
打赏
举报
回复
引用 1 楼 jdjwxj 的回复:
一种是把广播变量作为参数传递到map线程中,一种是常规的用法。这两种方法对内存是使用一样吗?效果是否有差别
jdjwxj
2019-03-26
打赏
举报
回复
python
变量
使用教案设计(1).doc
这意味着学生需要重点掌握
变量
的基本概念和使用方法,同时在学习过程中需要特别注意
变量
命名规则和赋值的细节。 11. **课堂总结和评价**:课堂结束时,教师应总结学生在
变量
使用方面的学习情况,同时评价他们的学习...
《Fragment间传递参数及结果》源码.
另一种方法是使用LocalBroadcastManager,创建一个本地
广播
,源Fragment发送
广播
,目标Fragment注册接收器来捕获
广播
消息。这种方法适用于不直接相关的Fragment之间的通信。 在实际开发中,我们需要根据具体需求...
Spark中
广播
变量
详解(TorrentBroadcast)
【前言:Spark目前提供了两种有限定类型的共享
变量
:
广播
变量
和累加器,今天主要介绍一下基于Spark2.4版本的
广播
变量
。先前的版本比如Spark2.1之前的
广播
变量
有两种实现:HttpBroadcast和TorrentBroadcast,但是鉴于...
Spark中
广播
变量
详解以及如何动态更新
广播
变量
【前言:Spark目前提供了两种有限定类型的共享
变量
:
广播
变量
和累加器,今天主要介绍一下基于Spark2.4版本的
广播
变量
。先前的版本比如Spark2.1之前的
广播
变量
有两种实现:HttpBroadcast和TorrentBroadcast,但是鉴于...
spark
广播
变量
大数据_Spark中
广播
变量
详解
Spark中
广播
变量
详解以及如何动态更新
广播
变量
mp.weixin.qq.com【前言:Spark目前提供了两种有限定类型的共享
变量
:
广播
变量
和累加器,今天主要介绍一下基于Spark2.4版本的
广播
变量
。先前的版本比如Spark2.1之前的...
Spark
1,275
社区成员
1,171
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章





 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

