tensorflow object detection API自己训练的数据集检测图像score很低而且检测不出物体。
自己的训练集和validation集是拍照之后把像素调小,大概几百*几百像素这种,图片大小不一。300左右在training set,有些图像之间很类似。66张在validation set. 用labellmg标定label如下:



用的是Faster R-CNN Inception v2 原型的configuration文件修改的,只修改了对应的路径,其他参数是默认值。
运行的python程序是把min_score_thresh修改到很小0.00000005接近0%才能看到bounding box.
vis_util.visualize_boxes_and_labels_on_image_array(
image,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8,
min_score_thresh=0.0000000005)
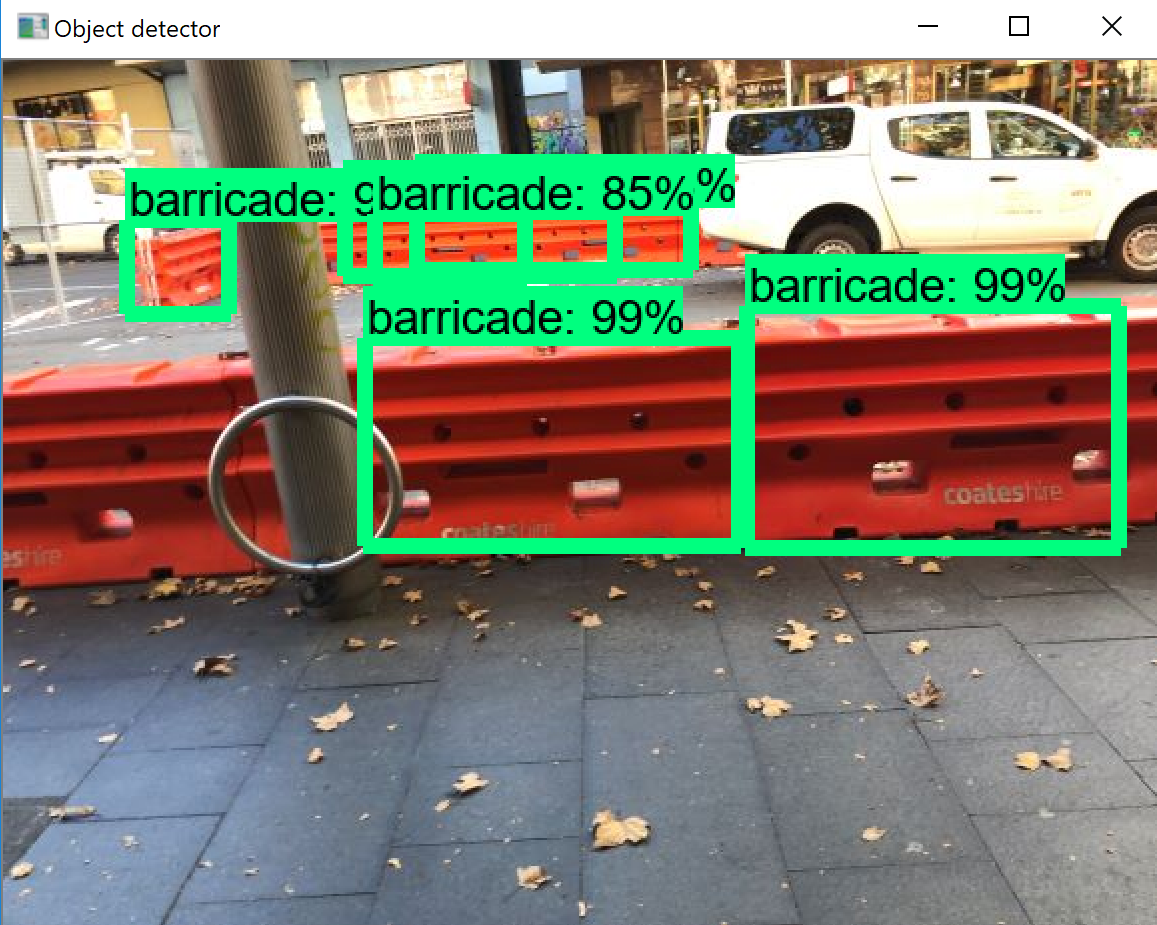
能确定程序执行没有问题,但是怀疑可能是阈值或者图像训练集有问题。因为这种建筑围栏都是连在一起的,每次我只能标注label一个,周边都是不完整的建筑围栏,如上图。训练完的detector去检测,结果如下:

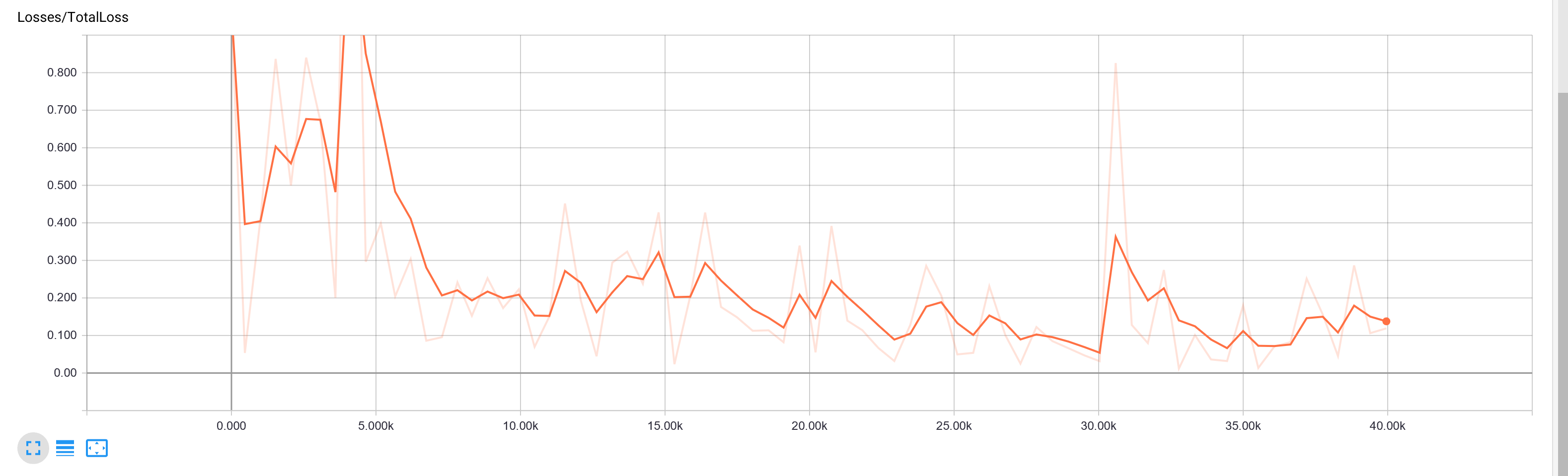
应该也没有过拟合,loss损失的图像:
请问如何修改才能正确检测出橙色塑料围栏?


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享