社区
CGI
帖子详情
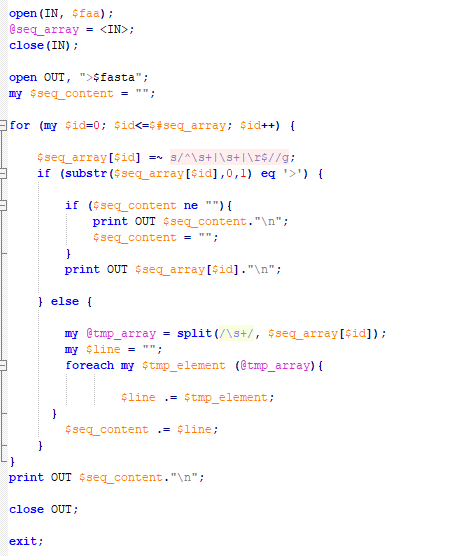
cgi运行perl脚本插入不了换行符
变成回忆的你
2019-06-17 07:56:50
我通过cgi执行perl脚本处理字符串,结果一直无法换行,单独执行perl脚本结果正常,请问这是怎么回事?
...全文
86
1
打赏
收藏
cgi运行perl脚本插入不了换行符
我通过cgi执行perl脚本处理字符串,结果一直无法换行,单独执行perl脚本结果正常,请问这是怎么回事?
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
变成回忆的你
2019-06-17
打赏
举报
回复
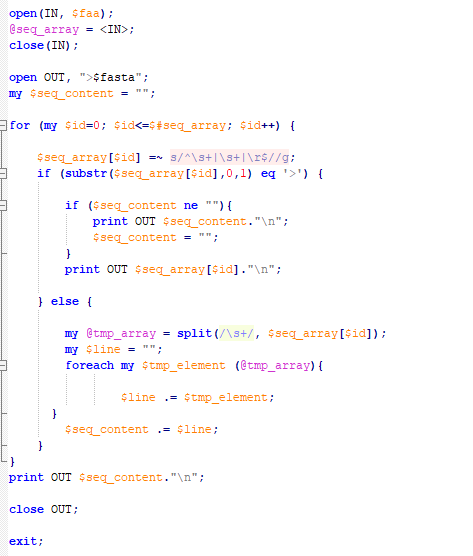
这是perl脚本
perl
语言
脚本
文档说明
目 录 译者序 前言 第一部分
Perl
基础 第1学时
Perl
入门 3 1.1 安装
Perl
3 1.1.1 等一等,也许你已经安装了
Perl
4 1.1.2 在Windows 95/98/NT上安装
Perl
5 1.1.3 在UNIX上安装
Perl
6 1.1.4 在Macintosh系统上安装
Perl
7 1.2 文档资料 7 1.2.1 某些特殊的文档资料举例 8 1.2.2 如果无法找到文档该怎么办 9 1.3 编写你的第一个
Perl
程序 9 1.3.1 键入程序 9 1.3.2
运行
程序 9 1.3.3 程序正确将会发生什么情况 10 1.3.4
Perl
程序的具体
运行
过程 10 1.3.5 必须知道的一些情况 11 1.4 课时小结 12 1.5 课外作业 12 1.5.1 专家答疑 12 1.5.2 思考题 12 1.5.3 解答 13 1.5.4 实习 13 第2学时
Perl
的基本构件:数字和 字符串 14 2.1 直接量 14 2.1.1 数字 14 2.1.2 字符串 15 2.2 标量变量 16 2.3 表达式和运算符 18 2.3.1 基本运算符 18 2.3.2 数字运算符 19 2.3.3 字符串运算符 19 2.4 其他运算符 20 2.4.1 单参数运算符 20 2.4.2 递增和递减 21 2.4.3 尖括号运算符 21 2.4.4 其他赋值运算符 22 2.4.5 关于字符串和数字的一些说明 22 2.5 练习:利息计算程序 23 2.6 课时小结 24 2.7 课外作业 24 2.7.1 专家答疑 24 2.7.2 思考题 24 2.7.3 解答 25 2.7.4 实习 25 第3学时 控制程序流 26 3.1 语句块 26 3.2 if语句 27 3.2.1 其他关系运算符 28 3.2.2 “真”对于
Perl
意味着什么 29 3.2.3 逻辑运算符 30 3.3 循环 32 3.3.1 用while进行循环 32 3.3.2 使用for循环 33 3.4 其他流控制工具 33 3.4.1 奇特的执行顺序 33 3.4.2 明细控制 34 3.4.3 标号 35 3.4.4 退出
Perl
35 3.5 练习:查找质数 35 3.6 课时小结 37 3.7 课外作业 37 3.7.1 专家答疑 37 3.7.2 思考题 37 3.7.3 解答 38 3.7.4 实习 38 第4学时 基本构件的堆栈:列表与数组 39 4.1 将数据放入列表和数组 39 4.2 从数组中取出元素 41 4.2.1 寻找结尾 42 4.2.2 关于上下文的详细说明 43 4.2.3 回顾以前的几个功能 44 4.3 对数组进行操作 45 4.3.1 遍历数组 46 4.3.2 在数组与标量之间进行转换 46 4.3.3 给数组重新排序 48 4.4 练习:做一个小游戏 49 4.5 课时小结 51 4.6 课外作业 51 4.6.1 专家答疑 51 4.6.2 思考题 51 4.6.3 解答 52 4.6.4 实习 52 第5学时 进行文件操作 53 5.1 打开文件 53 5.1.1 路径名 54 5.1.2 出色的防错措施 55 5.1.3 以适当的方式
运行
die函数 56 5.2 读取文件 56 5.3 写入文件 58 5.4 自由文件、测试文件和二进制数据 60 5.4.1 自由文件句柄 60 5.4.2 二进制文件 60 5.4.3 文件测试运算符 61 5.5 课时小结 62 5.6 课外作业 62 5.6.1 专家答疑 62 5.6.2 思考题 63 5.6.3 解答 63 5.6.4 实习 63 第6学时 模式匹配 64 6.1 简单的模式 64 6.2 元字符 66 6.2.1 一个简单的元字符 66 6.2.2 非输出字符 66 6.2.3 通配符 66 6.2.4 字符类 68 6.2.5 分组和选择 69 6.2.6 位置通配符 69 6.3 替换 70 6.4 练习:清除输入数据 70 6.5 关于模式匹配的其他问题 71 6.5.1 对其他变量进行操作 71 6.5.2 修饰符与多次匹配 72 6.5.3 反向引用 73 6.5.4 一个新函数:grep 73 6.6 课时小结 74 6.7 课外作业 74 6.7.1 专家答疑 74 6.7.2 思考题 75 6.7.3 解答 75 6.7.4 实习 75 第7学时 哈希结构 77 7.1 将数据填入哈希结构 77 7.2 从哈希结构中取出数据 78 7.3 列表与哈希结构 80 7.4 关于哈希结构的补充说明 81 7.4.1 测试哈希结构中的关键字 81 7.4.2 从哈希结构中删除关键字 81 7.5 用哈希结构进行的有用操作 81 7.5.1 确定频率分布 82 7.5.2 在数组中寻找惟一的元素 82 7.5.3 寻找两个数组之间的交汇部分 和不同部分 83 7.5.4 对哈希结构进行排序 84 7.6 练习:用
Perl
创建一个简单的客户 数据库 84 7.7 课时小结 86 7.8 课外作业 86 7.8.1 专家答疑 86 7.8.2 思考题 87 7.8.3 解答 87 7.8.4 实习 88 第8学时 函数 89 8.1 创建和调用子例程 89 8.1.1 返回子例程的值 90 8.1.2 参数 91 8.1.3 传递数组和哈希结构 91 8.2 作用域 92 8.3 练习:统计数字 94 8.4 函数的脚注 96 8.4.1 声明local变量 96 8.4.2 使
Perl
变得更加严格 97 8.4.3 递归函数 98 8.5 课时小结 99 8.6 课外作业 99 8.6.1 专家答疑 99 8.6.2 思考题 99 8.6.3 解答 100 8.6.4 实习 100 第二部分 高级特性 第9学时 其他函数和运算符 103 9.1 搜索标量 103 9.1.1 用index进行搜索 103 9.1.2 用rindex向后搜索 104 9.1.3 用substr分割标量 104 9.2 转换而不是替换 105 9.3 功能更强的print函数 106 9.4 练习:格式化报表 107 9.5 堆栈形式的列表 109 9.6 课时小结 110 9.7 课外作业 111 9.7.1 专家答疑 111 9.7.2 思考题 111 9.7.3 解答 112 9.7.4 实习 112 第10学时 文件与目录 113 10.1 获得目录列表 113 10.2 练习:UNIX的grep 116 10.3 目录 117 10.3.1 浏览目录 117 10.3.2 创建和删除目录 118 10.3.3 删除文件 119 10.3.4 给文件改名 119 10.4 UNIX系统 120 10.5 你应该了解的关于文件的所有信息 121 10.6 练习:对整个文件改名 122 10.7 课时小结 123 10.8 课外作业 124 10.8.1 专家答疑 124 10.8.2 思考题 124 10.8.3 解答 124 10.8.4 实习 125 第11学时 系统之间的互操作性 126 11.1 system()函数 126 11.2 捕获输出 128 11.3 管道 129 11.4 可移植性入门 131 11.5 课时小结 134 11.6 课外作业 134 11.6.1 专家答疑 134 11.6.2 思考题 135 11.6.3 解答 135 11.6.4 实习 136 第12学时 使用
Perl
的命令行工具 137 12.1 什么是调试程序 137 12.1.1 启动调试程序 137 12.1.2 调试程序的基本命令 138 12.1.3 断点 139 12.1.4 其他调试程序命令 140 12.2 练习:查找错误 141 12.3 其他命令行特性 142 12.3.1 单命令行程序 142 12.3.2 其他开关 143 12.3.3 空的尖括号与更多的单命令 行程序 144 12.4 课时小结 145 12.5 课外作业 145 12.5.1 专家答疑 145 12.5.2 思考题 146 12.5.3 解答 146 第13学时 引用与结构 147 13.1 引用的基本概念 147 13.1.1 对数组的引用 149 13.1.2 对哈希结构的引用 149 13.1.3 作为参数的引用 150 13.1.4 创建各种结构 151 13.2 结构的配置方法 152 13.2.1 一个例子:列表中的列表 152 13.2.2 其他结构 153 13.2.3 使用引用来调试程序 154 13.3 练习:另一个游戏——迷宫 155 13.4 课时小结 157 13.5 课外作业 157 13.5.1 专家答疑 157 13.5.2 思考题 158 13.5.3 解答 158 13.5.4 实习 158 第14学时 使用模块 159 14.1 模块的概述 159 14.1.1 读取关于模块的文档 160 14.1.2 什么地方可能出错 161 14.2 已安装模块简介 162 14.2.1 文件和目录简介 162 14.2.2 拷贝文件 164 14.2.3 用于通信的
Perl
模块 164 14.2.4 使用English模块 165 14.2.5 diagnostics模块 165 14.3 标准模块的完整列表 166 14.4 课时小结 167 14.5 课外作业 167 14.5.1 专家答疑 167 14.5.2 思考题 168 14.5.3 解答 168 14.5.4 实习 168 第15学时 了解程序的
运行
性能 169 15.1 DBM文件 169 15.1.1 需要了解的重点 170 15.1.2 遍历与DBM文件相连接的哈 希结构 170 15.2 练习:一种自由格式备忘记事板 171 15.3 将文本文件用作数据库 173 15.4 随机访问文件 175 15.4.1 打开文件进行读写操作 175 15.4.2 在读写文件中移动 176 15.5 锁定文件 176 15.5.1 锁定UNIX和NT下的文件 178 15.5.2 在加锁情况下进行读写操作 179 15.5.3 Windows 95和Windows 98下的 加锁问题 180 15.5.4 在其他地方使用文件锁的问题 181 15.6 课时小结 181 15.7 课外作业 181 15.7.1 专家答疑 181 15.7.2 思考题 182 15.7.3 解答 182 15.7.4 实习 182 第16学时
Perl
语言开发界 183 16.1
Perl
究竟是一种什么语言 183 16.1.1
Perl
的简单发展历史 183 16.1.2 开放源 184 16.1.3
Perl
的开发 185 16.2
Perl
综合存档文件网 185 16.2.1 什么是CPAN 186 16.2.2 为什么人们愿意提供自己的开 发成果 186 16.3 下一步你要做的工作 187 16.3.1 要做的第一步工作 187 16.3.2 最有用的工具 187 16.3.3 查找程序中的错误 188 16.3.4 首先要靠自己来解决问题 188 16.3.5 从别人的程序错误中吸取教训 189 16.3.6 请求他人的帮助 190 16.4 其他资源 191 16.5 课时小结 192 16.6 课外作业 192 16.6.1 专家答疑 192 16.6.2 思考题 192 16.6.3 解答 192 第三部分 将
Perl
用于
CGI
第17学时
CGI
概述 195 17.1 浏览Web 195 17.1.1 检索一个静态Web页 196 17.1.2 动态Web页—使用
CGI
197 17.2 不要跳过这一节内容 198 17.3 编写你的第一个
CGI
程序 199 17.3.1 在服务器上安装
CGI
程序 200 17.3.2
运行
你的
CGI
程序 201 17.4
CGI
程序无法
运行
时怎么办 201 17.4.1 这是你的
CGI
程序吗 201 17.4.2 服务器存在的问题 202 17.4.3 排除服务器内部错误或500错误 203 17.5 课时小结 204 17.6 课外作业 204 17.6.1 专家答疑 204 17.6.2 思考题 205 17.6.3 解答 205 17.6.4 实习 206 第18学时 基本窗体 207 18.1 窗体是如何
运行
的 207 18.1.1 HTML窗体元素概述 207 18.1.2 单击submit时出现的情况 208 18.2 将信息传递给你的
CGI
程序 209 18.3 Web安全性 211 18.3.1 建立传输明码文本的连接 211 18.3.2 注意不安全数据 212 18.3.3 从事无法执行的操作 213 18.3.4 拒绝服务 213 18.4 宾客留言簿 214 18.5 课时小结 215 18.6 课外作业 215 18.6.1 专家答疑 215 18.6.2 思考题 216 18.6.3 解答 216 18.6.4 实习 216 第19学时 复杂窗体 217 19.1 复杂的多页窗体 217 19.2 隐藏域 217 19.3 多页调查窗体 219 19.4 课时小结 224 19.5 课外作业 224 19.5.1 专家答疑 224 19.5.2 思考题 225 19.5.3 解答 225 19.5.4 实习 225 第20学时 对HTTP和
CGI
进行操作 226 20.1 HTTP通信概述 226 20.1.1 举例:人工检索Web页 227 20.1.2 举例:返回非文本信息 228 20.2 如何调用
CGI
程序的详细说明 230 20.2.1 将参数传递给
CGI
程序 230 20.2.2 特殊参数 231 20.3 服务器端的包含程序 232 20.4 部分环境函数简介 234 20.5 重定向 235 20.6 课时小结 237 20.7 课外作业 237 20.7.1 专家答疑 237 20.7.2 思考题 237 20.7.3 解答 238 20.7.4 实习 238 第21学时 cookie 239 21.1 什么是cookie 239 21.1.1 如何创建cookie 240 21.1.2 举例:使用cookie 241 21.1.3 另一个例子:cookie查看器 242 21.2 高级cookie特性 243 21.2.1 设置cookie终止
运行
的时间 243 21.2.2 cookie的局限性 244 21.2.3 将cookie发送到其他地方 244 21.2.4 限制cookie返回到的位置 246 21.2.5 带有安全性的cookie 247 21.3 cookie存在的问题 247 21.3.1 cookie的生存期很短 247 21.3.2 并非所有浏览器都支持cookie 247 21.3.3 有些人不喜欢cookie 247 21.4 课时小结 248 21.5 课外作业 248 21.5.1 专家答疑 248 21.5.2 思考题 249 21.5.3 解答 250 21.5.4 实习 250 第22学时 使用
CGI
程序发送电子邮件 251 22.1 Internet邮件入门 251 22.1.1 发送电子邮件 252 22.1.2 发送邮件时首先应该注意的问题 252 22.2 邮件发送函数 253 22.2.1 用于UNIX系统的邮件函数 254 22.2.2 用于非UNIX系统的邮件函数 255 22.3 从Web页发送邮件 257 22.4 课时小结 259 22.5 课外作业 259 22.5.1 专家答疑 259 22.5.2 思考题 260 22.5.3 解答 260 22.5.4 实习 260 第23学时 服务器推送和访问次数 计数器 261 23.1 什么是服务器推送 261 23.1.1 激活服务器推送特性 262 23.1.2 一个小例子:更新Web页上 的时钟 262 23.1.3 另一个例子:动画 263 23.1.4 客户机拖拉技术 264 23.2 访问次数计数器 264 23.2.1 编写一个访问次数计数器程序 266 23.2.2 图形访问次数计数器 267 23.3 课时小结 268 23.4 课外作业 269 23.4 1 专家答疑 269 23.4.2 思考题 269 23.4.3 解答 269 23.4.4 实习 270 第24学时 建立交互式Web站点 271 24.1 借用另一个站点的内容 271 24.1.1 注意内容的版权问题 271 24.1.2 举例:检索标题 272 24.2 调查窗体 275 24.2.1 调查窗体程序的第一部分: 提出问题 276 24.2.2 调查窗体程序的第二部分: 计算调查结果 277 24.3 课时小结 280 24.4 课外作业 280 24.4.1 专家答疑 280 24.4.2 思考题 281 24.4.3 解答 281 24.4.4 实习 281 第四部分 附录 附录 安装模块 285
Code2HTML语法高亮
code2html是一个
Perl
脚本
,可以转换多种语言的源码到HTML代码,它的功能非常丰富,既可以单独使用,也可以当作
CGI
脚本
来给网站使用。下面来看一下它的用法: code2html -h 此命令在终端打印code2html的命令格式和各个参数。code2html的命令格式如下: code2html [options] [input_file] [output_file] 下面是code2html常用的参数: input_file 要转换的源码文件的路径,如果源码文件在当前目录下,可以直接跟文件名。如果不加此参数或者使用减号”-”作占位符,code2html将出标准输入设备(通常为键盘)中获取源码。 output_file 转换源码后将HTML保存到的文件,如果不加此参数或者使用一个减号”-”做占位符,code2html将把转换结果输出到标准输出设备(通常为屏幕)中。 -l 设定要转换的源码文件是哪种语言,如果不加此参数,code2html将自动判断源码所属的语言。 -m 使用命令“code2html -m”可以在终端打印code2html所有支持的语言。 -n 使输出的HTML文档中包含行数。 -N 使输出的HTML文档中包含行数,并且行数序号包含指向当前行的超链接。 -t number 将文档中出现的任一Tab字符替换成number个空格。 该命令通常的用法可以是: code2html sample.java sample.html 上述命令将自动判断使用什么语言的语法的特点来格式化转换后的HTML文档。一般可以准确判断并转换。 code2html -l c sample.c sample.html 使用C语言的语法规范来格式化转换后的HTML代码。 code2html -l python -N sample.py sample.html 上述命令以python语言的语法规范来格式化转换后的HTML文档,同时为其加上都有指向自己的链接的行数。 code2html是一个功能比较强大的代码高亮转换工具,它的用法不止以上这么多。此外,它还可以当作
CGI
脚本
在网站上
运行
,关于它的更详细的用法可以参看其官方文档。 http://www.palfrader.org/code2html/manual.html
C语言入门到高阶-- printf、scanf 与
CGI
文件重定向
尹成老师,带你步入 C 语言的殿堂,讲课生动风趣、深入浅出,全套视频内容充实,整个教程以 C 语言为核心,完整精彩的演练了数据结构、算法、设计模式、数据库、大数据高并发检索、文件重定向、多线程同步、进程通讯、黑客劫持技术、网络安全、加密解密,以及各种精彩的小项目等,非常适合大家学习!帮助大家快速入门C语言,一步步的成为C语言高手。
Java-PHP-C#
"^The": 匹配以 "The"开头的字符串; "of despair$": 匹配以 "of despair" 结尾的字符串; "^abc$": 匹配以abc开头和以abc结尾的字符串,实际上是只有abc与之匹配 "notice": 匹配包含notice的字符串 你可以看见如果你没有用我们提到的两个字符(最后一个例子),就是说 模式(正则表达式) 可以出现在被检验字符串的任何地方,你没有把他锁定到两边 这里还有几个字符 '*', '+',和 '?', 他们用来表示一个字符可以出现的次数或者顺序. 他们分别表示:"zero or more", "one or more", and "zero or one." 这里是一些例子: "ab*": 匹配字符串a和0个或者更多b组成的字符串("a", "ab", "abbb", etc.); "ab+": 和上面一样,但最少有一个b ("ab", "abbb", etc.); "ab?":匹配0个或者一个b; "a?b+$": 匹配以一个或者0个a再加上一个以上的b结尾的字符串. 你也可以在大括号里面限制字符出现的个数,比如 "ab{2}": 匹配一个a后面跟两个b(一个也不能少)("abb"); "ab{2,}": 最少更两个b("abb", "abbbb", etc.); "ab{3,5}": 2-5个b("abbb", "abbbb", or "abbbbb"). 你还要注意到你必须总是指定 (i.e, "{0,2}", not "{,2}").同样,你必须注意到, '*', '+', 和'?' 分别和一下三个范围标注是一样的,"{0,}", "{1,}", 和 "{0,1}"。 现在把一定数量的字符放到小括号里,比如: "a(bc)*": 匹配 a 后面跟0个或者一个"bc"; "a(bc){1,5}": 一个到5个 "bc." 还有一个字符 '│', 相当于OR 操作: "hi│hello": 匹配含有"hi" 或者 "hello" 的 字符串; "(b│cd)ef": 匹配含有 "bef" 或者 "cdef"的字符串; "(a│b)*c": 匹配含有这样 - 多个(包括0个)a或b,后面跟一个c 的字符串 的字符串; 一个点('.')可以代表所有的 单一字符: "a.[0-9]": 一个a跟一个字符再跟一个数字的 (含有这样一个字符串的字符串将被匹配,以后省略此括号) "^.{3}$": 以三个字符结尾 . 中括号括住的内容只匹配一个 单一的字符 "[ab]": 匹配单个的 a 或者 b ( 和 "a│b" 一样); "[a-d]": 匹配'a' 到'd'的单个字符 (和"a│b│c│d" 还有 "[abcd]"效果一样); "^[a-zA-Z]": 匹配以字母开头的字符串 "[0-9]%": 匹配含有 形如 x% 的字符串 ",[a-zA-Z0-9]$": 匹配以逗号在加一个数字或字母结尾的字符串 你也可以把你不想要得字符列在中括号里,你只需要在总括号里面使用'^' 作为开头 (i.e., "%[^a-zA-Z]%" 匹配含有 两个百分号里面有一个非字母 的字符串). 为了能够解释,但"^.[$()│*+?{\"作为有特殊意义的字符的时候,你必须在这些字符面前加'', 还有在php3中你应该避免在模式的最前面使用\, 比如说,正则表达式 "(\$│?[0-9]+" 应该这样调用 ereg("(\\$│?[0-9]+", $str) (不知道php4是不是一样) 不要忘记在中括号里面的字符是这条规路的例外—在中括号里面, 所有的特殊字符,包括(''), 都将失去他们的特殊性质(i.e., "[*\+?{}.]"匹配含有这些字符的字符串). 还有,正如regx的手册告诉我们: "如果列表里含有 ']', 最好把它作为列表里的第一个字符(可能跟在'^'后面). 如果含有'-', 最好把它放在最前面或者最后面, or 或者一个范围的第二个结束点(i.e. [a-d-0-9]中间的‘-’将有效. 为了完整, 我应该涉及到 collating sequences, character classes, 同埋 equivalence classes. 但我在这些方面不想讲的太详细, 这些在下面的文章仲都不需要涉及到. 你们可以在regex man pages 那里得到更多消息. 如何构建一个模式来匹配 货币数量 的输入 好了,现在我们要用我们所学的来干一些有用的事:构建一个匹配模式去检查输入的信息是否为一个表示money的数字。我们认为一个表示money的数量有四种方式: "10000.00" 和 "10,000.00",或者没有小数部分, "10000" and "10,000". 现在让我们开始构建这个匹配模式: ^[1-9][0-9]*$ 这是所变量必须以非0的数字开头.但这也意味着 单一的 "0" 也不能通过测试. 以下是解决的方法: ^(0│[1-9][0-9]*)$ "只有0和不以0开头的数字与之匹配",我们也可以允许一个负号再数字之前: ^(0│-?[1-9][0-9]*)$ 这就是: "0 或者 一个以0开头可能有一个负号在前面的数字." 好了, 好了现在让我们别那么严谨,允许以0开头.现在让我们放弃 负号 , 因为我们在表示钱币的时候并不需要用到. 我们现在指定 模式 用来匹配小数部分: ^[0-9]+(\.[0-9]+)?$ 这暗示匹配的字符串必须最少以一个阿拉伯数字开头. 但是注意,在上面模式中 "10." 是不匹配的, 只有 "10" 和 "10.2" 才可以. (你知道为什么吗) ^[0-9]+(\.[0-9]{2})?$ 我们上面指定小数点后面必须有两位小数.如果你认为这样太苛刻,你可以改成: ^[0-9]+(\.[0-9]{1,2})?$ 这将允许小数点后面有一到两个字符. 现在我们加上用来增加可读性的逗号(每隔三位), 我们可以这样表示: ^[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?$ 不要忘记加号 '+' 可以被乘号 '*' 替代如果你想允许空白字符串被输入话 (为什么?). 也不要忘记反斜杆 ’\’ 在php字符串中可能会出现错误 (很普遍的错误). 现在,我们已经可以确认字符串了, 我们现在把所有逗号都去掉 str_replace(",", "", $money) 然后在把类型看成 double然后我们就可以通过他做数学计算了. 构造检查email的正则表达式 好,让我们继续讨论怎么验证一个email地址. 在一个完整的email地址中有三个部分: POP3 用户名 (在 '@' 左边的一切), '@', 服务器名(就是剩下那部分). 用户名可以含有大小写字母阿拉伯数字,句号 ('.'), 减号('-'), and 下划线 ('_'). 服务器名字也是符合这个规则,当然下划线除外. 现在, 用户名的开始和结束都不能是句点. 服务器也是这样. 还有你不能有两个连续的句点他们之间至少存在一个字符,好现在我们来看一下怎么为用户名写一个匹配模式: ^[_a-zA-Z0-9-]+$ 现在还不能允许句号的存在. 我们把它加上: ^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*$ 上面的意思就是说: "以至少一个规范字符(除.意外)开头,后面跟着0个或者多个以点开始的字符串." 简单化一点, 我们可以用 eregi()取代 ereg().eregi()对大小写不敏感, 我们就不需要指定两个范围 "a-z" 和 "A-Z" – 只需要指定一个就可以了: ^[_a-z0-9-]+(\.[_a-z0-9-]+)*$ 后面的服务器名字也是一样,但要去掉下划线: ^[a-z0-9-]+(\.[a-z0-9-]+)*$ Done. 现在只需要用”@”把两部分连接: ^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$ 这就是完整的email认证匹配模式了,只需要调用 eregi(‘^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$ ’,$eamil) 就可以得到是否为email了 正则表达式的其他用法 提取字符串 ereg() and eregi() 有一个特性是允许用户通过正则表达式去提取字符串的一部分(具体用法你可以阅读手册). 比如说,我们想从 path/URL 提取文件名 – 下面的代码就是你需要: ereg("([^\\/]*)$", $pathOrUrl, $regs); echo $regs[1]; 高级的代换 ereg_replace() 和 eregi_replace()也是非常有用的: 假如我们想把所有的间隔负号都替换成逗号: ereg_replace("[ \n\r\t]+", ",", trim($str)); PHP被大量的应用于Web的后台
CGI
开发,通常是在用户数据数据之后得出某种结果,但是如果用户输入的数据不正确,就会出现问题,比如说某人的生日是"2月30日"!那应该怎么样来检验暑假是否正确呢? 在PHP中加入了正则表达式的支持,让我们可以十分方便的进行数据匹配。 2 什么是正则表达式: 简单的说,正则表达式是一种可以用于模式匹配和替换的强大工具。在几乎所有的基于UNIX/LINUX系统的软件工具中找到正则表达式的痕迹,例如:
Perl
或PHP
脚本
语言。此外,JavaScript这种客户端的
脚本
语言也提供了对正则表达式的支持,现在正则表达式已经成为了一个通用的概念和工具,被各类技术人员所广泛使用。 在某个Linux网站上面有这样的话:"如果你问一下Linux爱好者最喜欢什么,他可能会回答正则表达式;如果你问他最害怕什么,除了繁琐的安装配置外他肯定会说正则表达式。" 正如上面说的,正则表达式看起来非常复杂,让人害怕,大多数的PHP初学者都会跳过这里,继续下面的学习,但是PHP中的正则表达式有着可以利用模式匹配找到符合条件的字符串、判断字符串是否合乎条件或者用指定的字符串来替代符合条件的字符串等强大的功能,不学实在太可惜了…… 3 正则表达式的基本语法: 一个正则表达式,分为三个部分:分隔符,表达式和修饰符。 分隔符可以是除了特殊字符以外的任何字符(比如"/ !"等等),常用的分隔符是"/"。表达式由一些特殊字符(特殊字符详见下面)和非特殊的字符串组成,比如"[a-z0-9_-]+@[a-z0-9_-.]+"可以匹配一个简单的电子邮件字符串。修饰符是用来开启或者关闭某种功能/模式。下面就是一个完整的正则表达式的例子: /hello.+?hello/is 上面的正则表达式"/"就是分隔符,两个"/"之间的就是表达式,第二个"/"后面的字符串"is"就是修饰符。 在表达式中如果含有分隔符,那么就需要使用转义符号"\",比如"/hello.+?\/hello/is"。转义符号除了用于分隔符外还可以执行特殊字符,全部由字母构成的特殊字符都需要"\"来转义,比如"\d"代表全体数字。 4 正则表达式的特殊字符: 正则表达式中的特殊字符分为元字符、定位字符等等。 元字符是正则表达式中一类有特殊意义的字符,用来描述其前导字符(即元字符前面的字符)在被匹配的对象中出现的方式。元字符本身是一个个单一的字符,但是不同或者相同的元字符组合起来可以构成大的元字符。 元字符: 大括号:大括号用来精确指定匹配元字符出现的次数,例如"/pre{1,5}/"表示匹配的对象可以是"pre"、"pree"、"preeeee"这样在"pr"后面出现1个到5个"e"的字符串。或者"/pre{,5}/"代表pre出现0此到5次之间。 加号:"+"字符用来匹配元字符前的字符出现一次或者多次。例如"/ac+/"表示被匹配的对象可以是"act"、"account"、"acccc"等在"a"后面出现一个或者多个"c"的字符串。"+"相当于"{1,}"。 星号:"*"字符用来匹配元字符前的字符出现零次或者多次。例如"/ac*/"表示被匹配的对象可以是"app"、"acp"、"accp"等在"a"后面出现零个或者多个"c"的字符串。"*"相当于"{0,}"。 问号:"?"字符用来匹配元字符前的字符出现零次或者1次。例如"/ac?/"表示匹配的对象可以是"a"、"acp"、"acwp"这样在"a"后面出现零个或者1个"c"的字符串。"?"在正则表达式中还有一个非常重要的作用,即"贪婪模式"。 还有两个很重要的特殊字符就是"[ ]"。他们可以匹配"[]"之中出现过的字符,比如"/[az]/"可以匹配单个字符"a"或者"z";如果把上面的表达式改成这样"/[a-z]/",就可以匹配任何单个小写字母,比如"a"、"b"等等。 如果在"[]"中出现了"^",代表本表达式不匹配"[]"内出现的字符,比如"/[^a-z]/"不匹配任何小写字母!并且正则表达式给出了几种"[]"的默认值: [:alpha:]:匹配任何字母 [:alnum:]:匹配任何字母和数字 [:digit:]:匹配任何数字 [:space:]:匹配空格符 [:upper:]:匹配任何大写字母 [:lower:]:匹配任何小写字母 [:punct:]:匹配任何标点符号 [:xdigit:]:匹配任何16进制数字 另外下面这些特殊字符在转义符号"\"转义后代表的含义如下: s:匹配单个的空格符 S:用于匹配除单个空格符之外的所有字符。 d:用于匹配从0到9的数字,相当于"/[0-9]/"。 w:用于匹配字母,数字或下划线字符,相当于"/[a-zA-Z0-9_]/"。 W:用于匹配所有与w不匹配的字符,相当于"/[^a-zA-Z0-9_]/"。 D:用于匹配任何非10进制的数字字符。 .:用于匹配除
换行符
之外的所有字符,如果经过修饰符"s"的修饰,"."可以代表任意字符。 利用上面的特殊字符可以很方便的表达一些比较繁琐的模式匹配。例如"/\d0000/"利用上面的正则表达式可以匹配万以上,十万一下的整数字符串。 定位字符: 定位字符是正则表达式中又一类非常重要的字符,它的主要作用是用于对字符在匹配对象中的位置进行描述。 ^:表示匹配的模式出现在匹配对象的开头(和在"[]"里面不同) $:表示匹配的模式出现在匹配对象的末尾 空格:表示匹配的模式出现在开始和结尾的两个边界之一 "/^he/":可以匹配以"he"字符开头的字符串,比如hello、height等等; "/he$/":可以匹配以"he"字符结尾的字符串即she等; "/ he/":空格开头,和^的作用一样,匹配以he开头的字符串; "/he /":空格结束,和$的作用一样,匹配以he结尾的字符串; "/^he$/":表示只和字符串"he"匹配。 括号: 正则表达式除了可以用户匹配,还可以用括号"()"来记录需要的信息,储存起来,给后面的表达式读取。比如: /^([a-zA-Z0-9_-]+)@([a-zA-Z0-9_-]+)(.[a-zA-Z0-9_-])$/ 就是记录邮件地址的用户名,和邮件地址的服务器地址(形式为username@server.com之类的),在后面如果想要读取记录下来的字符串,只是需要用"转义符+记录的次序"来读取。比如"\1"就相当于第一个"[a-zA-Z0-9_-]+","\2"相当于第二个([a-zA-Z0-9_-]+),"\3"就是第三个(.[a-zA-Z0-9_-])。但是在PHP中,"\"是一个特殊的字符,需要转义,所以""到了PHP的表达式中就应该写成"\\1"。 其他特殊符号: "|":或符号"|"和PHP里面的或一样,不过是一个"|",而不是PHP的两个"||"!意思就是可以是某个字符或者另一个字符串,比如"/abcd|dcba/"可能匹配"abcd"或者"dcba"。 5 贪婪模式: 前面在元字符中提到过"?"还有一个重要的作用,即"贪婪模式",什么是"贪婪模式"呢? 比如我们要匹配以字母"a"开头字母"b"结尾的字符串,但是需要匹配的字符串在"a"后面含有很多个"b",比如"a bbbbbbbbbbbbbbbbb",那正则表达式是会匹配第一个"b"还是最后一个"b"呢?如果你使用了贪婪模式,那么会匹配到最后一个"b",反之只是匹配到第一个"b"。 使用贪婪模式的表达式如下: /a.+?b/ /a.+b/U 不使用贪婪模式的如下: /a.+b/ 上面使用了一个修饰符U,详见下面的部分。 6 修饰符: 在正则表达式里面的修饰符可以改变正则的很多特性,使得正则表达式更加适合你的需要(注意:修饰符对于大小写是敏感的,这意味着"e"并不等于"E")。正则表达式里面的修饰符如下: i :如果在修饰符中加上"i",则正则将会取消大小写敏感性,即"a"和"A" 是一样的。 m:默认的正则开始"^"和结束"$"只是对于正则字符串如果在修饰符中加上"m",那么开始和结束将会指字符串的每一行:每一行的开头就是"^",结尾就是"$"。 s:如果在修饰符中加入"s",那么默认的"."代表除了
换行符
以外的任何字符将会变成任意字符,也就是包括
换行符
! x:如果加上该修饰符,表达式中的空白字符将会被忽略,除非它已经被转义。 e:本修饰符仅仅对于replacement有用,代表在replacement中作为PHP代码。 A:如果使用这个修饰符,那么表达式必须是匹配的字符串中的开头部分。比如说"/a/A"匹配"abcd"。 E:与"m"相反,如果使用这个修饰符,那么"$"将匹配绝对字符串的结尾,而不是
换行符
前面,默认就打开了这个模式。 U:和问号的作用差不多,用于设置"贪婪模式"。 7 PCRE相关的正则表达式函数: PHP的
Perl
兼容正则表达式提供的多个函数,分为模式匹配,替换和匹配数目等等: 1、preg_match : 函数格式:int preg_match(string pattern, string subject, array [matches]); 这个函数会在string中使用pattern表达式来匹配,如果给定了[regs],就会将string记录到[regs][0]中,[regs][1]代表使用括号"()"记录下来的第一个字符串,[regs][2]代表记录下来的第二个字符串,以此类推。preg如果在string中找到了匹配的pattern,就会返回"true",否则返回"false"。 2、preg_replace : 函数格式:mixed preg_replace(mixed pattern, mixed replacement, mixed subject); 这个函数会使用将string中符合表达式pattern的字符串全部替换为表达式replacement。如果replacement中需要包含pattern的部分字符,则可以使用"()"来记录,在replacement中只是需要用"\1"来读取。 3、preg_split : 函数格式:array preg_split(string pattern, string subject, int [limit]); 这个函数和函数split一样,区别仅在与split可以使用简单正则表达式来分割匹配的字符串,而preg_split使用完全的
Perl
兼容正则表达式。第三个参数limit代表允许返回多少个符合条件的值。 4、preg_grep : 函数格式:array preg_grep(string patern , array input); 这个函数和preg_match功能基本上,不过preg_grep可以将给定的数组input中的所有元素匹配,返回一个新的数组。 下面举一个例子,比如我们要检查Email地址的格式是否正确: <?php function emailIsRight($email) { if (preg_match("^[_\.0-9a-z-]+@([0-9a-z][0-9a-z-]+\.)+[a-z]{2,3}$",$email)) { return 1; } return 0; } if(emailIsRight('y10k@963.net')) echo '正确
'; if(!emailIsRight('y10k@fffff')) echo '不正确
'; ?> 上面的程序会输出"正确
不正确"。 8.PHP中的
Perl
兼容正则表达式和
Perl
/Ereg正则表达式的区别: 虽然叫做“
Perl
兼容正则表达式”,但是和
Perl
的正则表达式相比,PHP的还是由一些不同,比如修饰符“G”在
Perl
里面代表全部匹配,但是在PHP中没有加入对这个修饰符的支持。 还有就是和ereg系列函数的区别,ereg也是PHP中提供的正则表达式函数,不过和preg相比,要弱上很多。 1、ereg里面是不需要也不能使用分隔符和修饰符的,所以ereg的功能比preg要弱上不少。 2、关于".":点在正则里面一般是除了
换行符
以外的全部字符,但是在ereg里面的"."是任意字符,即包括
换行符
!如果在preg里面希望"."能够包括
换行符
,可以在修饰符中加上"s"。 3、ereg默认使用贪婪模式,并且不能修改,这个给很多替换和匹配带来麻烦。 4、速度:这个或许是很多人关心的问题,会不会preg功能强大是以速度来换取的?不用担心,preg的速度要远远比ereg快,笔者做了一个程序测试: time test: PHP代码: <?php echo "Preg_replace used time:"; $start = time(); for($i=1;$i<=100000;$i++) { $str = "ssssssssssssssssssssssssssss"; preg_replace("/s/","",$str); } $ended = time()-$start; echo $ended; echo " ereg_replace used time:"; $start = time(); for($i=1;$i<=100000;$i++) { $str = "ssssssssssssssssssssssssssss"; ereg_replace("s","",$str); } $ended = time()-$start; echo $ended; echo " str_replace used time:"; $start = time(); for($i=1;$i<=100000;$i++) { $str = "sssssssssssssssssssssssssssss"; str_replace("s","",$str); } $ended = time()-$start; echo $ended; ?> 结果: Preg_replace used time:5 ereg_replace used time:15 str_replace used time:2 str_replace因为不需要匹配所以速度非常快,而preg_replace的速度比ereg_replace要快上不少。 9.关于PHP3.0对于preg的支持: 在PHP 4.0中默认加入了preg支持,但是在3.0中确没有。如果在3.0中希望使用preg函数,必须加载php3_pcre.dll文件,只要在php.ini的extension部分设置加入"extension = php3_pcre.dll"然后从新启动PHP就可以了! 其实正则表达式还常用于UbbCode的实现,很多PHP论坛都使用了这个方法(比如zForum zphp.com或者vB vbullent.com),但是具体的代码比较长。 本文来自http://blog.csdn.net/kkobebryant/archive/2005/01/25/267527.aspx
CGI
2,204
社区成员
4,518
社区内容
发帖
与我相关
我的任务
CGI
Web 开发 CGI
复制链接
扫一扫
分享
社区描述
Web 开发 CGI
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
 这是perl脚本
这是perl脚本
