

17,134
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享SELECT substr(orgCode,1,instr(orgCode, '.',1,3)) orgCode,SUM(s.MONTH_ADD)
from SPECIL_TASK_REPORT s
WHERE ((s.year = 2018 and s.month >= 7 or (s.year > 2018))
and ((s.year = 2018 and s.month <= 12) or (s.year < 2018)))
GROUP BY substr(orgCode,1,instr(orgCode, '.',1,3))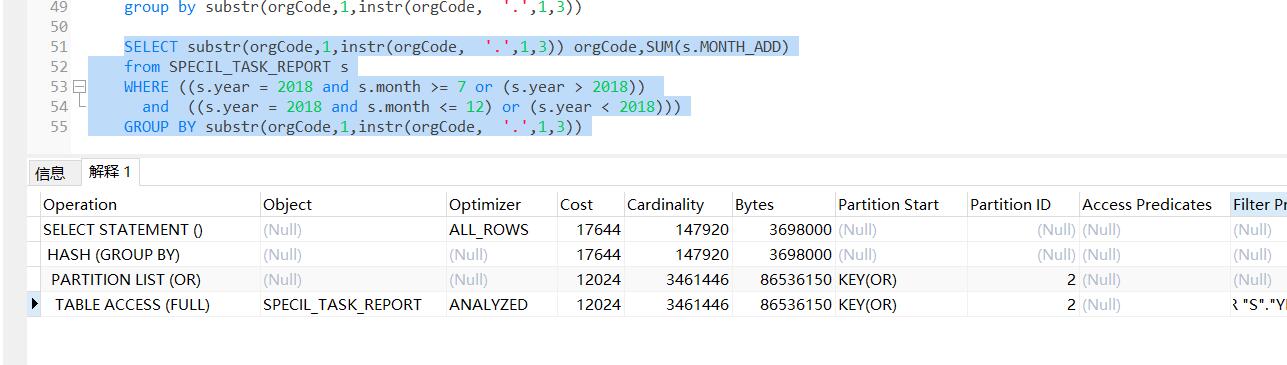
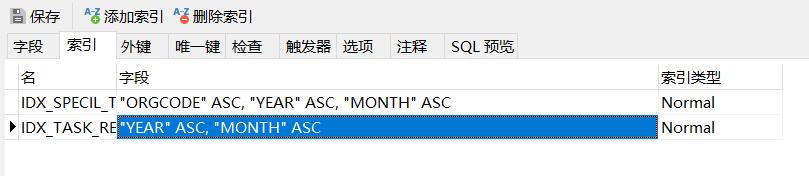








 如果以SQL的执行时间为标准来判断SQL性能的好坏,最好多执行几次,取稳定时间为准,因为有buffer cache缓存的影响。
如果以SQL的执行时间为标准来判断SQL性能的好坏,最好多执行几次,取稳定时间为准,因为有buffer cache缓存的影响。


