社区
Spark
帖子详情
sparksql 获取数据转rdd执行阻塞
weixin_41884762
2019-09-02 11:25:59
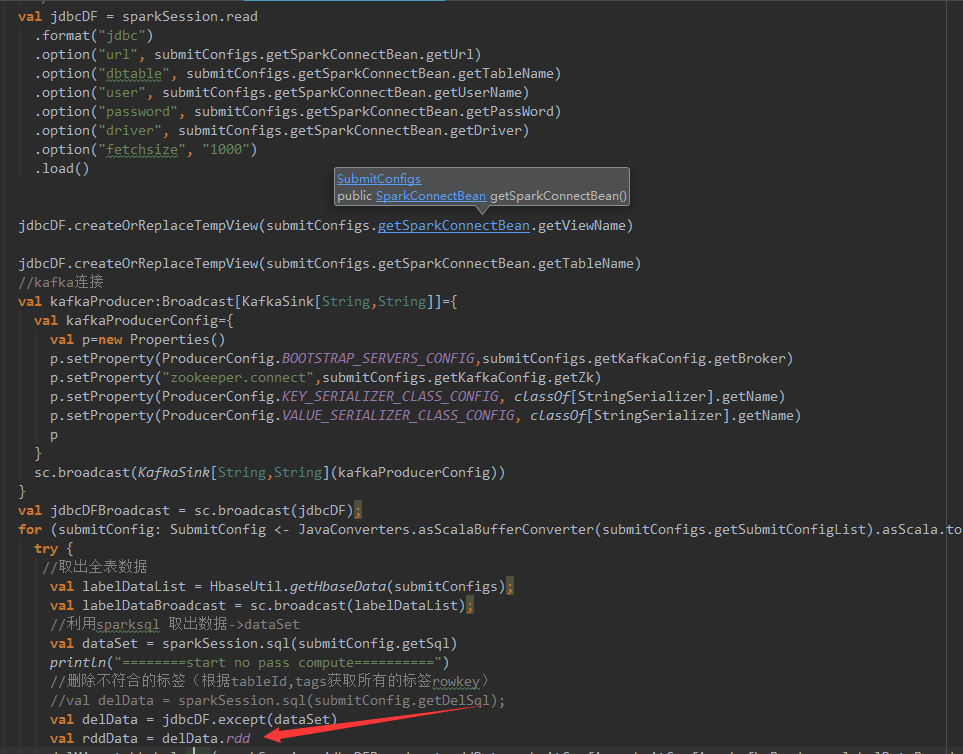
图片中标红部分在转rdd的时候一直在running最后失败
dataset数据量大概6000万多,各位大佬请帮忙解答因为啥导致的,给小白一点建议
...全文
204
1
打赏
收藏
sparksql 获取数据转rdd执行阻塞
图片中标红部分在转rdd的时候一直在running最后失败 dataset数据量大概6000万多,各位大佬请帮忙解答因为啥导致的,给小白一点建议
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
1 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
RivenDong
2019-09-08
打赏
举报
回复
我想知道你机器内存多少??
锅炉系统完整工程设计方案(深度详细版).docx
锅炉系统完整工程设计方案(深度详细版).docx
光流模块使用手册(LC-307)V1.3@20230223,湖南优象科技有限公司资料分享
资料来源:湖南优象科技有限公司资料链接下载。里面包含了:湖南优象科技有限公司光流飞控端的使用源码(参考代码)demo,湖南优象科技有限公司上位机光流软件,配置文件,LC307需初始化设置的光流模块配置选项说明图,飞控端调试光流方法说明V1.0@20240329,光流模块使用手册(LC-307)V1.3@20230223,无人机光流模块使用技巧。原来的下载链接通过百度网盘分享的文件:光流模块使用手册… 链接:https://pan.baidu.com/s/1ktmurBJHyzPNgBS298_wyw?pwd=sdgl 家人们谁懂哇,csdn和优象官网,只找到了使用手册,配置文件一点都不带有的哇,去找淘宝客服直接说没有。去找优象科技有限公司的邮箱才给我发哇。。。。。。。
V90伺服系统操作说明-下载即用.zip
下载代码方式:https://pan.quark.cn/s/a4b39357ea24 SHEMaskDemo App遮罩引导操作提示 使用说明类的操作引导提示,点击x或“我知道了”或“下一步”直到结束。 Image text
机电一体化系统综合课程设计_X-Y数控工作台设计说明书——22.rar
机电一体化系统综合课程设计_X-Y数控工作台设计说明书——22.rar
无尽冬日AAAAAAAAAAB
无尽冬日AAAAAAAAAAB
Spark
1,275
社区成员
1,171
社区内容
发帖
与我相关
我的任务
Spark
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
复制链接
扫一扫
分享
社区描述
Spark由Scala写成,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于MapReduce算法实现的分布式计算。
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章




 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享

