社区
C语言
帖子详情
Format specifies type 'char *' but the argument has type 'char (*)[12]'如何解决
啊这是谁
2019-11-10 06:34:47
程序可以运行,但是会有提醒格式不对,有人能帮忙解决一下吗?刚刚学C语言真的问了很多白痴问题……谢谢!!
...全文
6000
3
打赏
收藏
Format specifies type 'char *' but the argument has type 'char (*)[12]'如何解决
程序可以运行,但是会有提醒格式不对,有人能帮忙解决一下吗?刚刚学C语言真的问了很多白痴问题……谢谢!!
复制链接
扫一扫
分享
转发到动态
举报
写回复
配置赞助广告
用AI写文章
3 条
回复
切换为时间正序
请发表友善的回复…
发表回复
打赏红包
liups
2019-11-10
打赏
举报
回复
2
引用 1 楼 SuperDay 的回复:
不要用&符号,order本来就是数组首地址
wowpH
2019-11-10
打赏
举报
回复
参考:
https://baike.baidu.com/item/scanf/10773316?fr=aladdin#5_1
解决了就结贴,不要点赞。
CSDN论坛新手指南
铖邑
2019-11-10
打赏
举报
回复
2
不要用&符号,order本来就是数组首地址
C:
format
specifies
type
‘unsigned int‘ but the
argument
has
type
‘
char
*‘
format
指定类型“unsigned int”,但参数的类型为“
char
*”
操作数组:warning:
format
‘%s’ expects
type
‘
char
*’, but
argument
2 has
type
‘int’...
代码编译后显示错误: 错误原因: %s格式对应的是字符串,a[1]类型为
char
,储存的是一个字符,如果要求输出a[1] 中的字符,可以把%s改为%c。如果是要去掉a[0],从a[1]开始显示数组中的字符串则将在a[1] 加取地址符’&’或者将‘a[1]’改为’a+1’。 更改之后的代码: 输出字符串。 或 输出a[1]中的字符。 ...
printf函数的 %s 与 %c
今天在研究C++的时候在Mac上随手写了些例子,结果发现一个关于printf很有趣的现象: 先定义一个模板: templateclass data_count{
type
a;
type
b; public: data_count(
type
A,
type
B):a(A),b(B){}
type
add(){return a+b;}
type
sub(
LLDB 调试 Segmentation fault (core dumped)
LLDB 调试 Segmentation fault (core dumped)
C语言 printf 格式化输出:5个易错点与3种长字符串换行方案
本文深入探讨C语言中printf函数的5个常见易错点与3种长字符串换行方案,涵盖类型不匹配、格式化参数细节、缓冲区性能优化等关键问题。通过实际代码示例和工程实践建议,帮助开发者避免格式化输出陷阱,提升代码健壮性和可维护性。特别针对C语言开发中的printf函数使用难点提供专业
解决
方案。
C语言
70,039
社区成员
243,246
社区内容
发帖
与我相关
我的任务
C语言
C语言相关问题讨论
复制链接
扫一扫
分享
社区描述
C语言相关问题讨论
社区管理员
加入社区
获取链接或二维码
近7日
近30日
至今
加载中
查看更多榜单
社区公告
暂无公告
试试用AI创作助手写篇文章吧
+ 用AI写文章
 啊这是谁 2019-11-10 06:34:47
啊这是谁 2019-11-10 06:34:47 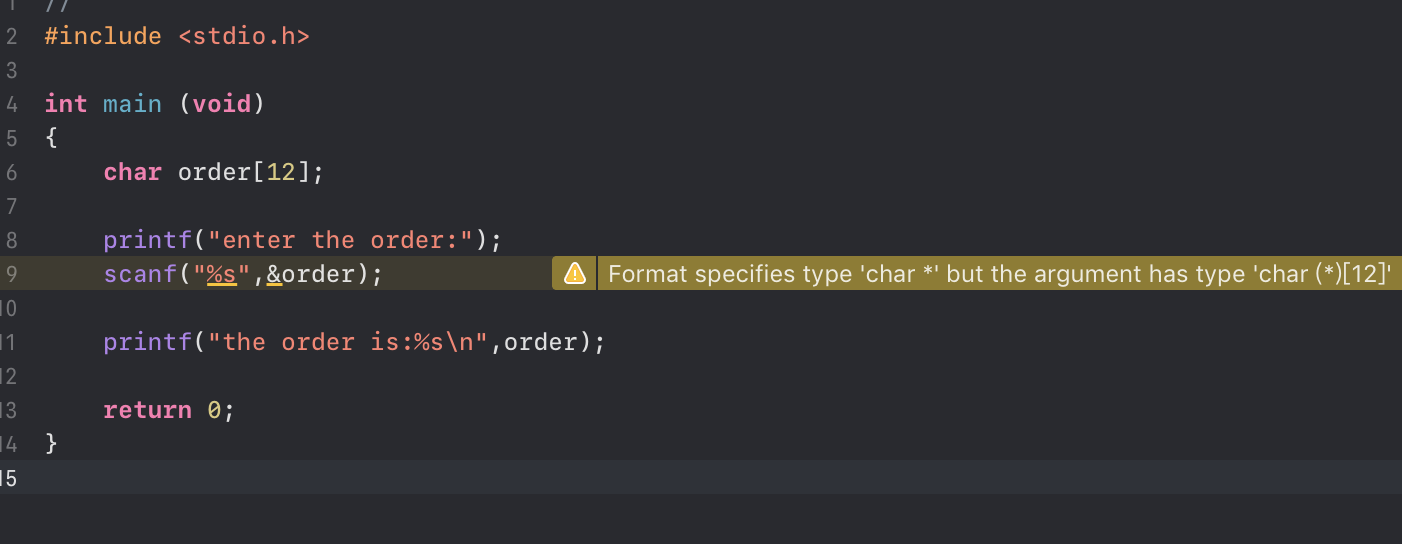


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享





