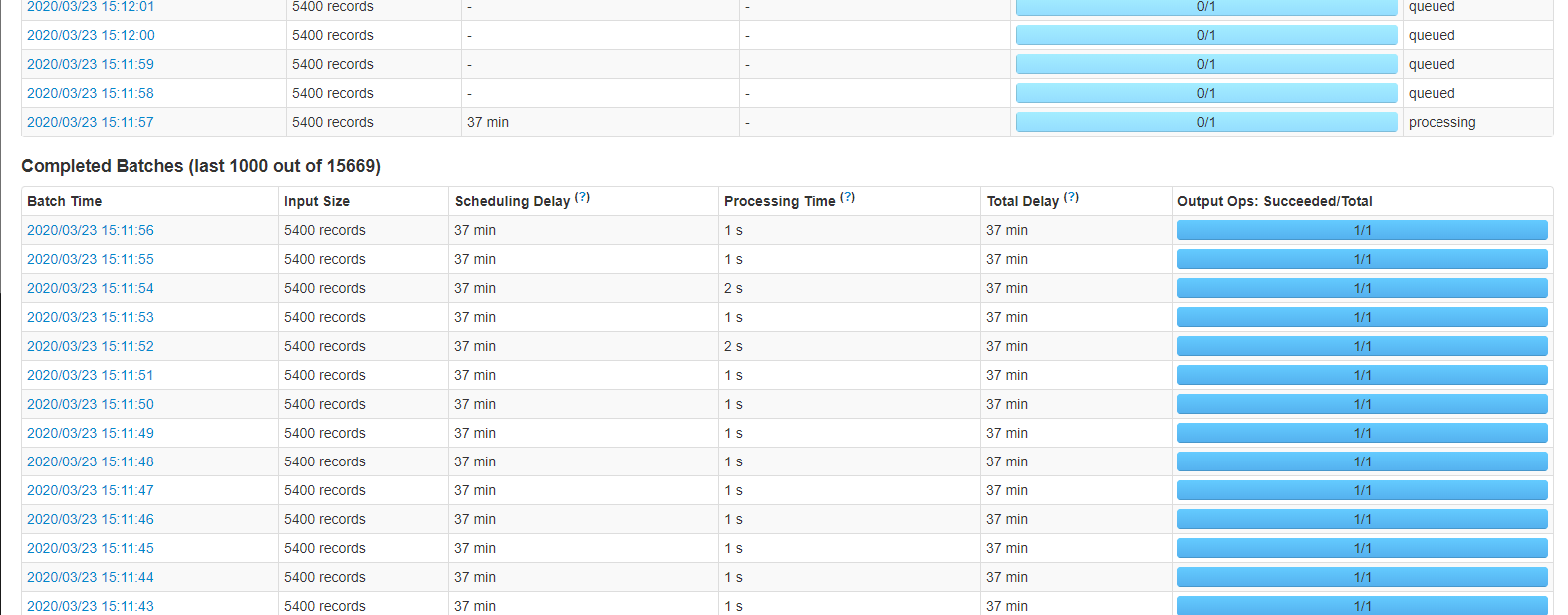
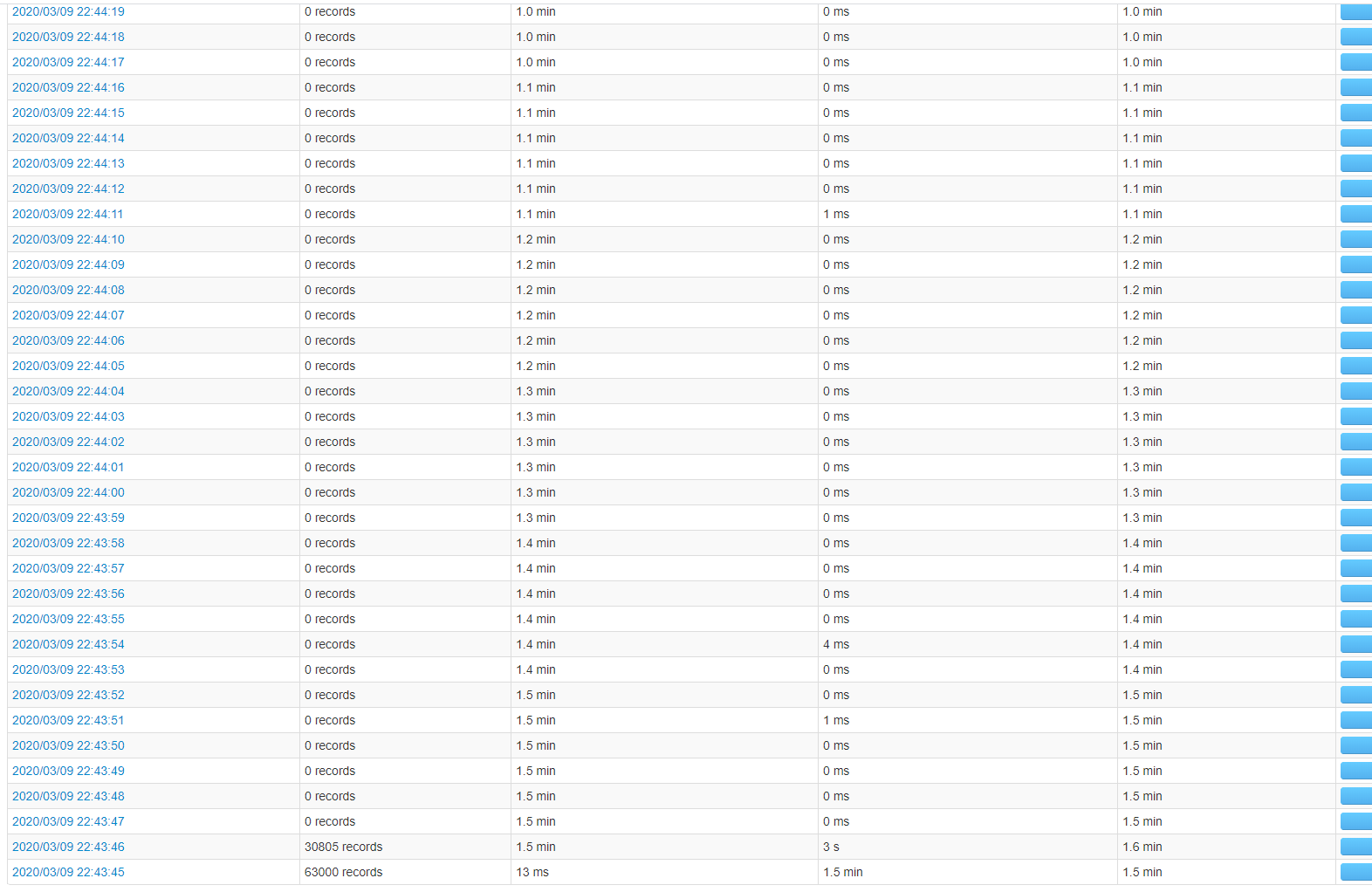
[quote=引用 3 楼 LinkSe7en 的回复:] 对于突然洪峰,然后后面很久都是每批0条,有可能是上游数据迟到了。跟上游消息发布者沟通一下是什么情况?
对于突然洪峰,然后后面很久都是每批0条,有可能是上游数据迟到了。跟上游消息发布者沟通一下是什么情况?
1,274
社区成员
1,171
社区内容
加载中
试试用AI创作助手写篇文章吧


 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



