



17,086
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享



create index idx_my_big_table on my_big_table(a, b);
select *
from my_big_table t1
where t1.a = 55654
union
select *
from my_big_table t1
where t1.b = 'b55654'

select *
from my_big_table t1
where t1.a = 55654
or t1.b = 'b55654';
select *
from my_big_table t1
where t1.a = 55654
union
select *
from my_big_table t1
where t1.b = 'b55654'
create table my_big_table as select level a, cast('b' || level as varchar2(8)) b from dual connect by level <= 200000;
create index idx_my_big_table on my_big_table(a, b);select *
from my_big_table t1
where t1.a = 55654
or t1.b = 'b55654';
select *
from my_big_table t1
where t1.a = 55654
union
select *
from my_big_table t1
where t1.b = 'b55654'create table my_big_table2 as select level a, cast('b' || level as varchar2(8)) b from dual connect by level <= 200000;
create index idx_my_big_table2_1 on my_big_table2(a);
create index idx_my_big_table2_2 on my_big_table2(b);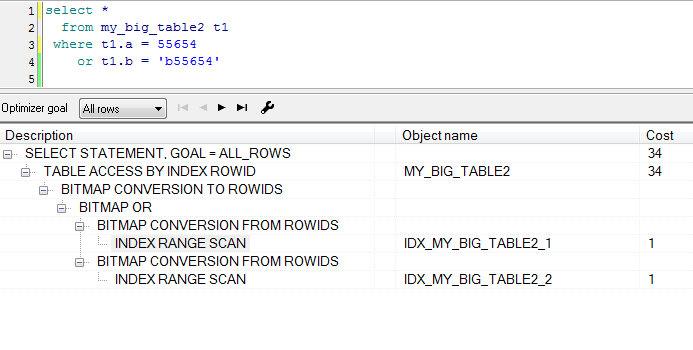 又可以看到优化器自作主张给转成了bitmap。
用hint强制修改执行计划
又可以看到优化器自作主张给转成了bitmap。
用hint强制修改执行计划
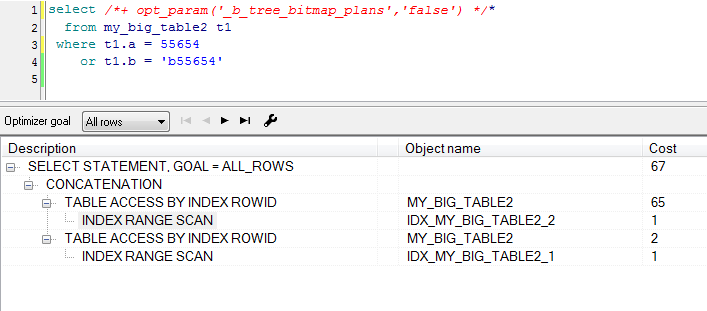 从这个执行计划可以看出确实改成union效率更高,但是优化器会自动帮你做这一步,并且这是根据统计信息做的智能判断,无需手动改成union。
再来一组数据奇葩的
从这个执行计划可以看出确实改成union效率更高,但是优化器会自动帮你做这一步,并且这是根据统计信息做的智能判断,无需手动改成union。
再来一组数据奇葩的
create table my_big_table3 as select mod(level, 2) a, cast('b' || level as varchar2(8)) b from dual connect by level <= 200000;
create index idx_my_big_table3_1 on my_big_table3(a);
create index idx_my_big_table3_2 on my_big_table3(b);
select *
from aaa.tab1 t1
where t1.aaaa_date = '20200504'
and t1.day_id = substr('20200504', 7, 2)
and t1.aaaa_no = '01'
and (
(#{levelType} = '1')
or (#{levelType} = '2' and #{saleId} = t1.col1)
or (#{levelType} = '3' and #{saleId} = t1.col2)
)


